Use DNS Application Directory Partitions with conditional forwarders
Before I explain how to use DNS Application Directory Partitions with conditional forwarders, we need to set the stage. We will shortly revisit how DNS name resolution is set up and configured for hybrid Azure environments. Then it will help to understand why DNS Application Directory Partitions are useful in such scenarios.
Active Directory Domain Services extended to Azure
In the context of this article, an Azure hybrid environment is where you have Active Directory Domain Services (ADDS) extended to Azure. I.e., you have a least one AD site on-premises and at least one AD Site in Azure, with connectivity between the two all set up via ExpressRoute or a Site-to-Site VPN, firewall configured, etc. In most cases, the DNS servers for the ADDS environment are AD integrated. Which is what we want for this scenario.
You must have DNS name resolution sorted out effectively and efficiently in such an environment. Queries from on-premises to Azure need to be resolved, and queries from Azure to on-premises.
Regarding resolving private endpoints in Azure and potentially other private DNS zones in Azure, we need to leverage conditional forwarders. That means we must create all the public DNS zones as conditional forwarders on the on-premises domain controllers. We point these at our custom DNS servers in Azure or our Azure Firewall DNS proxy that points to our custom DNS servers in Azure. The latter is the better option if that is available. Those custom DNS Servers will most likely be our AD/DNS server in Azure. These will forward the queries to azure VIP 168.63.129.16, which will let Azure DNS handle the actual name resolution.
Conditional forwarders on-premises
There are two attention points in this scenario. First, the conditional forwarders should only exist on the on-premises DC/DNS servers. That is normal. The DC/DNS servers in Azure can just forward the queries to the Azure VIP, which will have the AD recursive DNS service query the private DNS zones and provide an answer. That is why we forward the on-prem queries to them directly or via the firewall DNS proxy.
Secondly, less frequent, but more often than you think, ADDS on-premises does not translate into a single Azure tenant or deployment. You can have multiple AD Sites in Azure for the same on-prem ADSS environment. That happens via different business units, mergers, and acquisitions, politics, life, or whatever.

Both attention points mean that we must ensure that the on-prem conditional forwarders only live on the DC/DNS servers that forward to the correct custom DNS services in Azure. Some DC/DNS servers on-premises might send their queries to Azure AD site 1 and others to Azure AD site 2, which might live in separate tenants or Azure deployments.
How do we achieve this?
One option is to create the conditional forwarders without storing and replicating them to all DC/DNS servers in the forest or the domain. That works quite well, but it leaves the burden to configure them on every DC/DNS server where required. That’s OK; PowerShell is your friend. See PowerShell script to maintain Azure Public DNS zone conditional forwarders – Working Hard In ITWorking Hard In IT for a script to do that for you.
But another option might be handy if you have 10 on-premises Active Directory Sites and 5 Azure Active Directory Sites. That option is called DNS partitioning. You can create your own Active Directory partitions, To those, you add the desired DC/DNS servers. You can now create your conditional forwarders, store them in Active Directory and replicate them to their respective custom partition. That leaves the flexibility to keep the conditional forwarders out of the Azure DC/DNS servers and enables different conditional forwarders configurations per on-premises Active Directory Site.
DNS Application Directory Partitions
To create the DNS application directory partitions, you can use PowerShell or the ‘dnscnd’ command line tool. I will use Powershell here. If you want to use the command line, look at How to create and apply a custom application directory partition on an Active Directory-integrated DNS zone on how to do this.
Add-DnsServerDirectoryPartition -Name "OP-BLUE-ADDS-SITE"
The command above did two things. It created the application directory partition and registered the DNS server on which you ran the script. You can test that with Get-DnsServerDirectoryPartition -Name “OP-BLUE-ADDS-SITE” or Get-DnsServerDirectoryPartition -Name “OP-BLUE-ADDS-SITE” -ComputerName ‘DC01’ if you specify the computer name.
By the way, if you run just Get-DnsServerDirectoryPartition, you will see all partition info for the current node or the node you specify.

Register the second DC/DNS server in this partition with the following command.
Register-DnsServerDirectoryPartition -Name "OP-BLUE-ADDS-SITE" -ComputerName 'DC02'.
Register-DnsServerDirectoryPartition -Name "OP-BLUE-ADDS-SITE" -ComputerName 'DC02'.
This returns nothing by default or an error in case something is wrong. Check your handy work with the below command.
Get-DnsServerDirectoryPartition -Name "OP-BLUE-ADDS-SITE" -ComputerName 'DC02'

Note that the Get-DnsServerDirectoryPartition only shows the registered DNS server for the node you are running it on or the one you specify. You do not get a list of all registered servers.
Now go ahead and store some zones in Active Directory and replicate to the BLUE partition on one of the DC/DNS servers you will see the ZoneCount go up on both. Just wait for replication to do its job or force replication to happen.

Storing the conditional forwarder in your DNS application directory partition
It is easy to store conditional forwarders in your custom DNS application directory partition. You can do this by adding or editing a conditional forwarding zone. However, be aware of the bug I wrote about in Bug when changing the “store this conditional forwarder in active directory” setting.
When you create the conditional forwarder zones for the private endpoints, you can store them in Active Directory and replicate them to their respective partitions. Just select the correct partition in the drop-down list. You will only see the partition for which your DC/DNS server has been registered, not every existing partition.
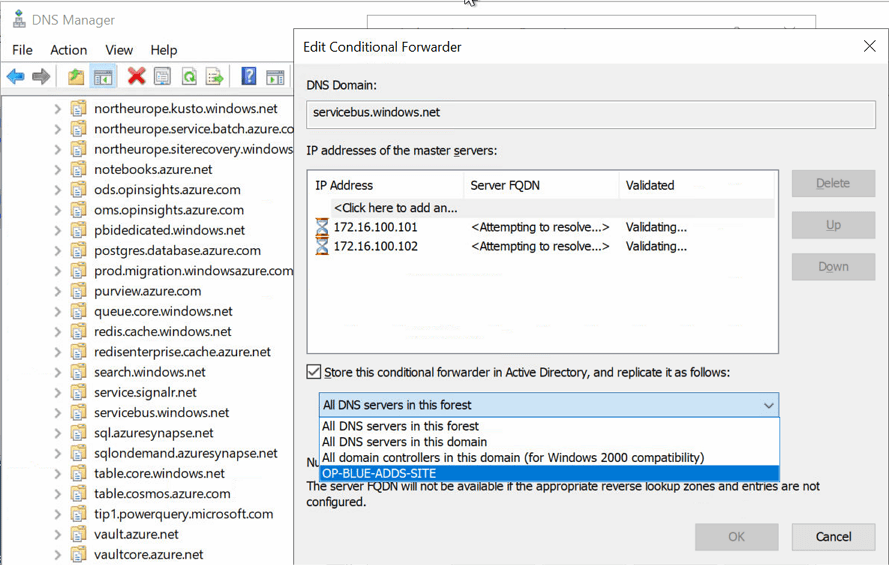
When done, the properties for the conditional forwarder will show that the zone is stored in Active Directory and replicated to all domain controllers in a user-defined scope.
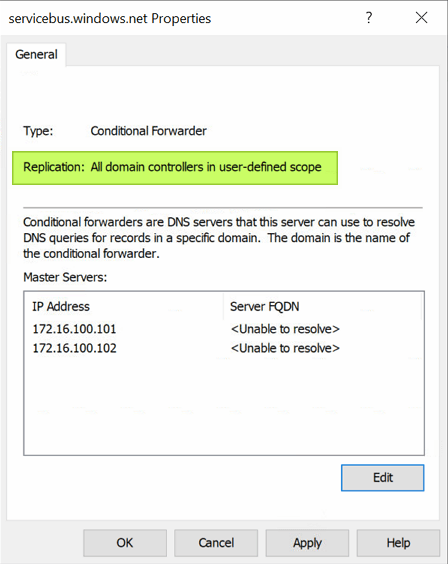
Create a partition for any collection of DC/DNS servers that you want to have their Azure private endpoint DNS zones sent to a specific Azure deployment. So depending on your situation, that might be one or more.
As I mentioned, the custom partition will not even be offered on any DC/DNS server that has not enlisted for that zone. This protects against people selecting the wrong custom partition for their environment.
Conclusion
That’s it. You now have one more option on your tool belt when configuring on-premises to Azure name resolution in hybrid scenarios. The fun thing is that I have never seen more people learn about using DNS Application Directory Partitions with conditional forwarders now they have to design and configure DNS for hybrid on-premises/Azure ADDS environments. Maybe you learned something new today. If so, I am happy you did.