I am attending Veeam Live 2020 from the comfort of my home this year. I can stay safe and still learn, connect, and investigate new technologies and options.
This works for me 🙂
Allow me to invite you Veeam Live 2020. This year the content focus area is on “Cloud Data Best Practices”. The online event takes place on October the 20th 2020 for a full day. Veeam is gathering its global talent pool to present at this event. That talent is both internal to Veeam as well as external. Some of my fellow Veeam Vanguards are presenting and sharing their expertise.
With names like Anton Gostev, Danny Allen, Rick Vanover, Michael Cade, Anthony Spiteri, Dave Kawula, Andrew Zhelezko, Dmitry Kniazez, David Hill, Karinne Bessette, Kirsten Stoner, Dave Russel Melissa Palmer, Sander Berkouwer, Drew J. Como and so many others, the experience and expertise to share are second to none. Many industry and customer experts are also joining in to share their insights.
As Veeam states
At Veeam Live, you’ll gain data management guidance you can activate today. You’ll learn how to up your data protection game across your enterprise, connect with like-minded professionals, set the strategy right for your organization, and be part of the future of Cloud Data Management™.”
Veeam Live 2020 October 2020 – Join for free
So no matter what level you are at or what part you play in managing and safeguarding the data of your organization there are things to explore and learn.
Topics
Topics to be discussed are Multi-Cloud Data Management, AWS- and Azure-Native Backup, Office 365 Backup, Ransomware Best Practices, Kubernetes Backup and App Mobility. Check out the full agenda to find the topics and sessions that are of most interest to you.
On all those subjects Veeam is actively developing and releasing new capabilities. Just think about their recent acquisition of Kasten. They are also sharing information about Veeam Backup & Replication V11 which is currently in Beta.
Get your questions answerd
Do you want to find out how you can make your solutions more efficient? Need to figure out the biggest threats and opportunities there are in today’s technical, business, and security landscape? Want to learn what new technologies you need to keep an eye on and learn about? Is the evergrowing ransomware threat keeping you awake at night?
Join us from the comfort of your own (home) office or couch. It all works. Just bring an open mind, a willingness to listen and learn. The interesting thing about Veeam is that they sell solutions that cater to real, existing, and emerging needs of their (potential) customers. They keep it real and have a tradition of explaining why they develop and bring their solutions and offerings to the market. It makes for educational and insightful sessions and events.
So now you know the secret of how I stay on top of things in the data protection and management world. I listen. Not the sound of crickets (that’s for vacations) but to people that are smart, experienced, and have a proven track record of delivering value in a very competitive and ever-changing landscape. So, now you also know how to stay up to speed, all that is left to do is register today. You are very welcome.
In this post, I will be discussing an issue we ran into when leveraging the instant recovery capability of Veeam Backup & Replication (VBR). The issue became apparent when we set up the preferred networks in VBR. The backup jobs and the standard restores both leveraged the preferred network as expected. We ran into an issue with instant recovery. While the mount phase leverages the preferred network this is not the case during the restore phase. That uses the default host management network. To make Veeam instant recovery use a preferred network we had to do some investigation and tweaking. This is what this blog post is all about.
Overview
We have a Hyper-V cluster, shared storage (FC), that acts as our source. We back up to a Scale Out Backup Repository that exists of several extend or standard repository. Next to the management network, all of the target and source nodes have connectivity to one or more 10/25Gbps networks. This is leveraged for CSV, live migrations, storage replication, etc. but also for the backup traffic via the Veeam Backup & Replication preferred network settings.
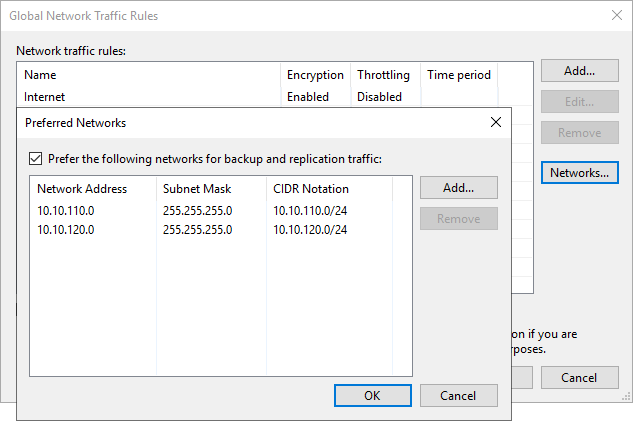
We have 2 preferred networks. This is for redundancy but also because there are different networks in use in the environment.
The IPs for the preferred networks are NOT registered in DNS. Note that the Veeam Backup & Replication server also has connectivity to the preferred networks. The reason for this is described in Optimize the Veeam preferred networks backup initialization speed.
As you might have guessed from the blog post title “Make Veeam Instant Recovery use a preferred network” this all worked pretty much as expected for the backup themselves and standard restores. But when it came to Instant Recovery we noticed that while the mount phase leveraged the preferred network, the actual restore phase did not.
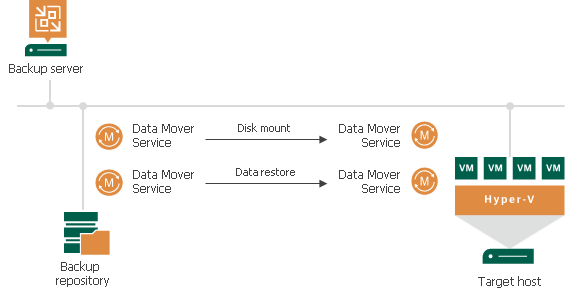
Instant VM recovery overview.
To read up on instant recovery go to Instant VM Recovery. But in this blog post, it is time to dive into the log files to figure out what is going on?
To solve the issue we dive into the VBR logs, but also into the logs on both the repository/extent and the Hyper-V server where we restore the VM to. The logs confirmed what we already noticed. For backups and normal restores, it correctly decides to use the preferred network. With instant recovery for some reason, in the restore phase, it selects the default host network which is 1Gbps.
Investigating the logs
Reading logs can seem an intimidating tedious task. The trick is to search for relevant entries and that is something you learn by doing. Combine that with an understanding of the problem and some common sense and you can quickly find what you need to look for. Than it is key to figure out why this could be happening. Sometimes that doesn’t work out. In that case, you contact Veeam support. That’s what I did as I knew well what the issue was and I could see this reflected in the logs. But I did not know how to handle this one.
We will look at the logs on the VBR Server, the repository where the backup files of the VM live, and the Hyper-V node where we restore the VM to investigate this issue.
The VBR log
Let’s look at the restore log of the virtual machine for which we perform instant recovery on the VBR server. We notice the following.
The actual restore phase of Instant Recovery leveraging the 1Gbps default host management network
The repository logs
These are the logs of our repository or extent where the restore reads the backup data from. There are actually 2 logs. One is the mount log and the other is the restore log.
We first dive into the Agent.IR.DidierTest08.Mount.Backup-Side.log of our test VM instant recovery. Here we can see connections to our Hyper-V server node where instant recover the test VM over the preferred network. Note that is is the Hyper-V server node that acts as the client!
Agent.IR.DidierTest08.Mount.Backup-Side.log
Let ‘s now parse the Agent.IR.DidierTest08.Restore.Backup-.Side.log of our test VM instant recovery. No matter how hard we look we cannot find any connection attempt, let alone a connection to a preferred network (10.10.110.0/24). We do see the restore work over the default management network (10.18.0.0/16). Also note here that it is the repository node that connects to the Hyper-V node (10.18.230.5), it acts as a client now.
Agent.IR.DidierTest08.Restore.Backup-Side.log
The restore target log
This is the Hyper-V server to where we restore the virtual machine. There are multiple logs but we are most interested in the mount log and the restore log.
We first dive into the Agent.IR.DidierTest08.Mount.HyperV-Side.log of our test VM instant recovery.The mount log shows what we already know. It also shows that it is the Hyper-V server that initiates the connection. This does leverage the preferred network (10.10.110.0/24).
Agent.IR.DidierTest08.Mount.HyperV-Side.log
It also shows the mount phase does leverage the preferred network (10.10.110.0/24).
Agent.IR.DidierTest08.Mount.HyperV-Side.log
But when we look at the restore phase log Agent.IR.DidierTest08.Restore.HyperV-Side.log we again see that the default host management network is used instead of the preferred network.
Agent.IR.DidierTest08.Restore.HyperV-Side.log
Again, we see that the Hyper-V server node during the restore phase acts as the server while the repository is the client (10.18.217.5).
Summary of our findings
Based on our observations on the servers (networks used) and investigating the logs we conclude the following. During an instant recovery, the VM is mounted on the Hyper-V host (where the checkpoint is taken). During the mount phase, the Hyper-V host acts as the client, while the repository acts as the client. This leverages the preferred network. Now, during the restore phase, the repository acts as the client and connects to the Hyper-V host that acts as the server. This does not leverage the preferred network.
This indicates that the solution might lie in reversing the client/server direction for the restore phase of Instant Recovery. But how? Well, there is a setting in Veeam where we can do just this.
Make Veeam Instant Recovery use a preferred network
I have to thank the Veeam support engineer that worked on this with me. He investigated the logs that I sent him as well but with more insight than I have. Those were clean logs just showing reproductions of the issue in combination with a Camtasia Video of it all. That way I showed him what was happening and what I saw while he also had the matching logs to what he was looking at.
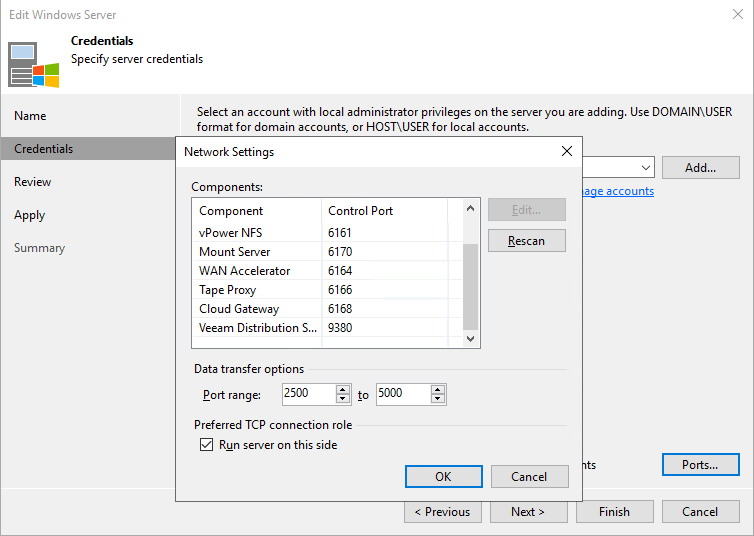
Sure enough, he came back with a fix or workaround if you like. To make sure instant recovery leverages the preferred network we needed to do the following. On each extent, in properties, under credentials go to network settings and check “Run server on this side” under “Preferred TCP connection role”.
On each extend, in properties, under credentials go to network settings and check Run server on this side under “Preferred TCP connection role”.
The “normal” use cases are for example when most the repository FQDN resolves into several IP addresses and Hyper-V FQDN is resolved into 1 only. This was not the case in our setup, the preferred networks are not registered in DNS. But here leveraging the capability to set “Run server on this side” solves our issue as well.
Parse the logs with “Run server on this side” enabled on the repository/extents
When we start a clean test and rerun an Instant Recovery of our test VM we now see that the restore phase does leverage the preferred network. The “Run server on this side” setting is also reflected in the restore phase logs on both the repository and the backup server.
Agent.IR.DidierTest08.Restore.Backup-Side.log. The Hyper-V server is the client (10.10.110.211) connects to the server, which is the repository.Agent.IR.DidierTest08.Restore.HyperV-Side.log. The server is now indeed the repository (10.10.110.14) and the client is the Hyper-V server node.
In the VBR log itself, we notice the “Run server on this side” has indeed been enabled.
Host ‘REPOSITORYSERVER’ should be server, reversing connection
IR.DidierTest08.Mount.log
In the Agent.IR.DidierTest08.Restore.Backup-Side.log on the repository server, we also see this setting reflected.
Agent.IR.DidierTest08.Restore.Backup-Side.log
Based on the documentation about “Run server on this side” in https://helpcenter.veeam.com/docs/backup/hyperv/hv_server_credentials.html?ver=95u4 you would assume this is only needed in scenarios where NAT is in play. But this doesn’t cover all use cases. Enabling this checkbox on a server means it does not initiate the connection but waits for the incoming connection from its partner. In our case that also causes the preferred network to be picked up. Apparently, all that is needed is to make sure the Hyper-V hosts to where we restore act as the client and initializes the connection to the server, our repository or extents in SOBR.
Conclusion
We achieved a successful result. Our instant recoveries now also leverage the preferred network. In this use case, this is really important as multiple concurrent instant recoveries are part of the recovery plan. That’s why we have performant storage solutions for our backup and source in combination with high bandwidth on a capable network. In the end, it all worked out well with a minor tweak to make Veeam Instant Recovery use a preferred network. This was however unexpected. I hope that Veeam dives into this issue and sees if the logic can be improved in future updates to make this tweak unnecessary. If I ever hear any feedback on this I will let you know.
Veeam NAS and File Share Backups are a new capability in Veeam Backup & Replication V10. We can now backup SMB, NFS shares as well as file server sources. This means it covers Linux and Windows files servers and shares. It can also backup also many NAS devices. There are many of those in both the SME and enterprise market. I know it is fashionable to state that file servers are dead, But that is like saying e-mail is dead. Yes, right until the moment you kill their mailbox. At that moment it is mission critical again.
My first test results with the RTM bits are so good I doing this quick publish to share them with you.
Early testing of Veeam NAS and File Share Backups
As a Veeam Vanguard I got access to the Veeam Backup & Replication V10 RTM bits so I decided to give it a go in some of our proving grounds.
I tested a Windows File Server, a Windows File share and a General Purpose File Share with continuous availability on a 2 node cluster. All operating systems run Windows Server 2019, fully patched at the time of writing.
These are your 3 major options and they cover 99% of file share uses cases out there.
Windows File Server
This is the preferred method if you can use it. That is if you have a Windows or Linux server as opposed to an appliance. The speeds are great and I am flirting with the 10Gbps limits of the NIC. As this is pure TCP it does not leverage SMB Multichannnel or SMB Direct.
9.9Gbps, 800-900MB/s, what is not to like about such early test results?
Windows File Share
With a NAS you might not have the option to leverage the file server object. No worries, we than use the File Share. If it is SMB 3 you can even leverage VSS if the NAS supports it. It might have the added benefit that you can add more file share proxies to do the initial full backup if so required. With File Server you are limited to itself. But it all depends on what the source can deliver and the target ingest.
A file share on Windows Server 2019
Note that we use a SMB 3 file share here. With a properly configured network you can leverage SMB Direct and SMB Multichannel with this.
RDMA and Multichannel – gotta love it.
General Purpose File Share with continuous availability on a 2 node cluster
This one is important to me. I normally only deploy General Purpose File Shares with continuous availability anymore where applicable and possible. SMB 3 haves given us many gifts and I like to leverage them. The ease of maintenance it offers is too good not to use it when possible. Can you say office hours patching of file servers?
So here is a screen shot of a Backup of a General Purpose File Shares with continuous availability where is initiate a fail over of the file share. That explains for the dip in the throughput, but the backup keeps running. Awesome!
Our backup source fails over but the backup keeps running. That is what we like to see. All this also leverages SMB 3 Direct and Multichannel by the way.
Restores
Backups are cool but restores rule. So to finish up this round of testing we share a restore. Not bad, not bad at all. 221.9 GB restored in 5.33 minutes.
Speedy restores are always welcome
More testing to follow
I will do more testing in the future. This will include small office files in large quantities. These early tests are more focused on large image data such as satellite, aerial photography and mobile mapping images. An important use case, hence our early testing focus.
For an overview of Veeam NAS and file share backups as well as the details take a look here for a presentation on the subject by one and only Michael Cade at TFD20.
Conclusion
The Veeam NAS and file share backups in Backup & Replication V10 are delivering great results right from the start. I am happy to see this capability arrive. Without any doubt the only remark I have is that they should have done this sooner. But today, it is here and I am nothing but happy about this.
There are lot of details to this but that will be for later content.
This is just a quick blog post to let you know the Hyper-V Amigos have released 2 webcasts recently. These are Hyper-V Amigos Showcast Episode 20 and 21. You will find a link to the videos and a description of the content below.
Hyper-V Amigos Showcast – Episode 20
In episode 20 of the Hyper-V Amigo ShowCast, we continue our journey in the different ways in which we can use storage spaces in backup targets. In our previous “Hyper-V Amigos ShowCast (Episode 19)– Windows Server 2019 as Veeam Backup Target Part I” we looked at stand-alone or member servers with Storage Spaces. With both direct-attached storage and SMB files shares as backup targets. We also played with Multi Resilient Volumes.
For this webcast, we have one 2 node S2D cluster set up for the Hyper-V workload (Azure Stack HCI). On a second 2 node S2D cluster, we host 2 SOFS file shares. Each on their own CSV LUN. SOFS on S2D is supported for backups and archival workloads. And as it is SMB3 and we have RDMA capable NICs we can leverage RDMA (RoCE, Mellanox ConnectX-5) to benefit from CPU offloading and superb throughput at ultra-low latency.
The General Purpose File Server (GPFS role) is not supported on S2D for now. You can use GPFS with shared storage and in combination with continuous availability. This performs well as a high available backup target as well. The benefit here is that this is cost-effective (Windows Server Standard licenses will do) and you get to use the shared storage of your choice. But in this show cast, we focus on the S2D scenario and we didn’t build a non-supported scenario.
You would normally expect to notice the performance impact of continuous availability when you compare the speeds with the previous episode where we used a non-high available file share (no continuous availability possible). But we have better storage in the lab for this test, the source system is usually the bottleneck and as such our results were pretty awesome.
The lab has 4 Tarox server nodes with a mix of Intel Optane DC Memory (Persistent Memory or Storage Class Memory), Intel NVMe and Intel SSD disks. For the networking, we leverage Mellanox ConnectX-5 100Gbps NICs and SN2100 100Gbps switches. Hence we both had a grin on our face just prepping this lab.
As a side note, the performance impact of continuous availability and write-through is expected. I have written about it before here. The reason why you might contemplate to use it. Next to a requirement for high availability, is due to the small but realistic data corruption risk you have with not continuously available SMB shares. The reason is that they do not provide write-through for guaranteed data persistence.
We also demonstrate the “Instant Recovery” capability of Veeam to make workloads available fast and point out the benefits.
Hyper-V Amigos Showcast – Episode 21
In episode 21 we are diving into leveraging the Veeam Agent for Windows integrated with Veeam Backup & Replication (v10 RC1) to protect our physical S2D nodes. For shops that don’t have an automated cluster node build processes set up or rely on external help to come in and do it this can be a huge time saver.
We walk through the entire process and end up doing a bare metal recovery of one of the S2D nodes. The steps include:
Setting up an Active Directory protection group for our S2D cluster.
Creating a backup job for a Windows Server, where we select failover cluster as type (Which has only the “Managed by Backup Server” as the mode).
We run a backup
After that, we create the Veeam Agent Recovery Media (the most finicky part)
Finally, we restore one of the S2D hosts completely using the bare metal recovery option
Some more information
Now we had some issues in the lab one of them suffering to a BSOD on the laptop used to make the recording and being a bit too impatient when booting from the ISO over a BMC virtual CD/DVD. Hence we had to glue some parts together and fast forward through the boring bits. We do appreciate that watching a system bot for 10 minutes doesn’t make for good infotainment. Other than that, it went fine and we were able to demonstrate the process from the beginning to the end.
As is the case with any process you should test and experiment to make sure you are familiar with the process. That makes it all a little easier and hurt a little less when the day comes you have to do it for real.
We hope the show cast helps you look into some of the capabilities and options you have with Veeam in regards to protecting any workloads. Long gone are the days that Veeam was only about protecting virtual Machines. Veeam is about protecting data where ever it lives. In VMs, physical servers, workstations, PCs, laptop, on-prem, in the cloud and Office 365. On top of that, you can restore it where ever you want to avoid lock-in and costly migration projects and tools. Check it out.
Conclusion
We will be doing more web casts on Veeam Backup & Replication v10 in 2020 as it will be generally available in Q1 as far I can guess.
But with Hyper-V Amigos Showcast Episode 20 and 21, that’s it for 2019. Enjoy the holidays during this festive season. The Hyper-V Amigos wish you a Merry X-Mas and a very happy New Year in 2020!