Introduction
Occasionally, I hear comments like “Veeam is too expensive.” Sometimes, when combined with the remark, it has become overly complex. In this blog I will discuss why Veeam V13 delivers for everyone.
I understand and accept those remarks. I do not fully agree, though I sympathize with the fact that businesses face more threats and challenges than ever before. The cost of living and doing business has not declined in the last five years. But beyond bar inflation, supply chain issues, and political turmoil, there are other factors driving rising costs and a perception of greater complexity. The world is different, and you need to critically evaluate your own perception if that is your view.

I will discuss here why Veeam V13 isn’t only for the Fortune 500, their needs, and their pockets. It’s for any seized SMB that can’t afford a single day of downtime.
Complexity and Cost
While many products today include compliance checkboxes that vendors must complete to be selected, most items have a far better reason for their existence. They are necessary.
The visceral reaction that it has become too complex and/or expensive is dead wrong. A statement like “My small business running a few dozen virtual machines doesn’t need this complexity or cost” is easy to make but ignores some realities.
It’s an infrastructure-blind perspective that fails to factor in the modern operational risk profile. The technical advancements in the Veeam Data Platform (VDP V13) are fundamentally about addressing the need for operational simplification and providing (mandatory) cyber resilience (GDPR, NIS2, DORA). From that perspective, it is precisely what an SMB (like an enterprise) requires.
When budgets are tight, you need solutions that aggressively reduce TCO by minimizing administrative overhead and guaranteeing recovery. If you cannot guarantee recovery, you are just window dressing and cosplaying at data protection. And while I have seen that happen even in large organizations and with partners, that is a recipe for disaster. Veeam V13 delivers what you need to guarantee recovery, the very thing that you buy and implement it for.
Minimizing configuration complexity and OPEX
The high cost of software isn’t just the license fee; it’s the weekly administrative hours and the price of the OS and database licenses required to run it. V13 tackles both.
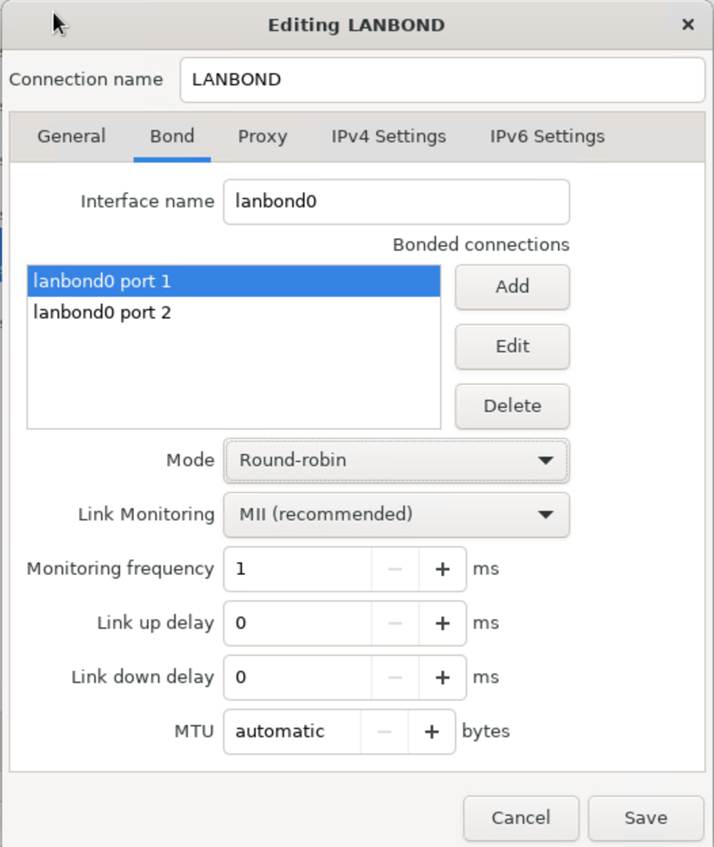
The Veeam Software Appliance (VSA) is a Game Changer
The Veeam Software Appliance is the most significant gift to small and medium businesses. The VSA is a hardened, Just Enough OS (JeOS) based on Linux.
- No Windows License Tax: You immediately eliminate the Windows Server OS license required for your backup repository server. That’s a direct, measurable savings on perpetual or subscription licensing. The same applies to the database: PostgreSQL incurs no license fee.
- Reduced Patching Cycle: The VSA is purpose-built. It automatically updates the core Veeam components, reducing required Linux OS maintenance. For a small team, this is an immediate, significant reduction in the security and patching OpEx drain. We are shifting from managing a full Windows Server install to managing a streamlined appliance.
- Immutability Baseline: It enforces immutability by default, providing an air-tight technical barrier against ransomware that could delete your backups. That isn’t a premium feature; it’s essential data-integrity engineering. You can’t afford to secure and audit a Windows repository to this standard manually.
VUL is protecting the infrastructure investment and adds flexibility
The Veeam Universal License (VUL) isn’t just flexible; it’s a TCO defense mechanism.
- Infrastructure Agnostic: Your license protects a VM, a Physical Server (via Agent), a Cloud VM (AWS/Azure), or even an M365 user.
- Future-Proofing the Budget: If you decide to ditch VMware for Hyper-V or move 10 VMs to Azure next year, your license stack does not change. You avoid the capital expense of acquiring new platform-specific licenses and maintain vendor leverage. VUL protects your budget against unforeseen architectural changes. You can switch between hypervisors and on-prem/hybrid/cloud at your discretion.
You can migrate to a hypervisor of your choice or to the cloud and continue using your existing licenses. Veeam has been adding support for additional providers as the market has become more volatile again.
Risk Mitigation
Backups must be restorable to justify the time and effort you invest.
- The cost of VDP Essentials is insurance against the cost of failure. A single ransomware event or hardware failure can bankrupt an SME, even if it results in only a multi-day outage. Veeam focuses on assuring recoverability and crushing the RTO (Recovery Time Objective).
- Instant VM Recovery: This technology means your RTO can be minutes, not hours, even for large VMs. You boot the VM directly from the deduplicated backup file while the permanent restoration occurs in the background. If you can’t afford to be down for four hours, this feature is worth its weight in gold.
- SureBackup Validation: No professional IT operation should ever expect its backups to work. SureBackup automatically verifies the image file’s integrity and restorability, validating RPO/RTO goals with no administrative effort. It provides the definitive technical proof that your backup chain is good.
There is free functionality via Community Editions
For the absolute tightest budgets, the Community Editions are a technical lifeline, providing the production-grade core engine at zero cost.
| Product | Capacity Constraint | Essential Technical Functionality |
| VBR Community Edition | 10 Instances (VMs, Servers, or 3 Workstations per instance). | Full Instant VM Recovery, Veeam Explorers (granular recovery for AD/Exchange/SQL), Scheduled Jobs, Backup Copy support (for 3-2-1 rule). |
| Veeam Backup for M365 CE | 10 Users / 10 Teams / 1TB SharePoint. | Granular recovery for all M365 workloads. Essential for closing the M365 retention gap and protecting against rogue admins/ransomware. |
| Cloud-Native Editions | 10 Instances per cloud (AWS, Azure, Google Cloud). | Policy-based, native snapshot management and data protection for cloud-resident workloads. |
The Bottom Line
Veeam designed V13 for maximum security and minimal operational overhead. At an SMB, you don’t have the resources to secure complex systems manually. The VDP Essentials product, paired with the VSA, delivers a hardened, low-maintenance, recovery-guaranteed system that significantly lowers your operational risk profile, making it a sound, justifiable technical investment. Veeam hides the complexity of its deployment; the simplicity you experience daily comes from adopting and running it. Once you have that base, you can enhance and expand your cyber resilience as your needs demand and budgets allow. But if you do not get the basics right, you are not in a good place to begin with.
Why are we at this point?
It isn’t 2015 anymore. The amount, diversity, and sophistication of threats are staggering. Moving from basic “set and forget” backups to a Zero Trust Data Resilience (ZTDR) architecture isn’t free. There are financial and engineering efforts to make it happen. That comes at a cost.
Transitioning from a simple backup job to a hardened, ransomware-proof posture involves more moving parts. You’re dealing with hardened repositories, MFA for everything, service account isolation, automated verification, and early-detection capabilities. If anyone tells you that adding immutability and Zero Trust doesn’t increase your operational footprint, they are paper architects who never have to live with their grand designs, let alone that they have never managed a production environment in the past few decades.
However, we need to distinguish between complex overhead and necessary engineering to keep you safe and keep it operationally manageable. Let’s discuss this a little bit more, without going into too much detail.
Hardware and storage costs
People will spend money on hyperconverged storage solutions with 25/50/100 Gbps networking, often all-flash, and with relatively low net usable capacity, yet then complain about having to use one or more dedicated storage servers to store and protect their backups. That is nothing new. Will have to invest in sufficient storage on a dedicated box as a backup target and/or use Veeam Data Cloud Vault, keeping it hardened and protected from other workloads.
That comes at a cost, especially if you need the performance to run Instant VM Recovery effectively. You should run your VBR Server on a VM on a different host, but most mini servers running a hypervisor can handle that for you. While you end up with a slightly higher BOM (Bill of Materials), you do get a backup fabric that can actually survive a scorched-earth ransomware attack.
The Configuration Burden
Implementing Zero Trust means keeping your backup fabric isolated, separate, and independent of the production workloads it protects, with only the minimal connectivity required to function. That means authentication and authorization must be performed securely (MFA, certificates), with immutability and hardened hosts. That used to be a lot of work and required extra effort, as it involves additional layers that complicate setup and configuration. But the payoff is a secured fabric that prevents a single compromised credential from wiping out your entire company’s history. And guess what? The Veeam VSA/JeOS handles most of that complexity for you. It is actually a complete TCO win that provides a level of protection many would never achieve on their own! You can automate restore testing and sleep easier: your backups are not a soft target, and you actually know restores work!
Conclusion
Yes, V13 requires a more disciplined approach to IT operations. Yes, there is some “overhead” in terms of ensuring your architecture follows the 3-2-1-1-0 rule. But that is no different than it was in V12, V11, … In an era where an SME is just as likely to be targeted as a global bank. Veeam designed V13 not only for “enterprise requirements and budgets”; they aim for professional-grade survival, no matter what size of business, so your company doesn’t close down for good in the event of a cybersecurity incident.