
Introduction
Let’s be honest: if you’re still relying on traditional backup strategies without immutability in today’s threat landscape, you’re playing a game of Russian roulette. Ransomware isn’t just a buzzword. It’s a business model. Insider threats aren’t hypothetical; they’re happening. And when the proverbial shit hits the fan, your backups are either your lifeline or your liability. Then there are wipers, who want to destroy data and your business, nothing else. They don’t ask for ransom payments, blackmail you to stop them from exposing your confidential files, or threaten to harm your personnel physically. Destruction and mayhem are all they care about. You need protection!

So, how do you prepare for that? You need a hardened repository, providing immutability and protection from deletion! Not just any Windows or generic Linux box with some tweaks, but a purpose-built, security-first solution. And suppose you want to avoid reinventing the wheel while staying compliant and operationally sane. In that case, the Veeam Hardened Repository ISO or its successor, Veeam Just Enough OS (Veeam JEOS), is the recommended approach.
Now, while I focus on the why related to Veeam’s Hardened Repository ISO, it is worth noting that an immutable repository does not exist in isolation. The 3-2-1-1-0 rule, CPU core and memory sizing, redundancy, high availability, IOPS, throughput, and storage and networking capacity matter! However, when it comes to the 3-2-1-1-0 rule, I have always stated that I don’t count the production workload as a copy. However, that one immutable copy is something I’m gradually changing into zero non-immutable and deletable copies.
Additionally, hardening any role in your backup fabric is now a must. Everything is a target, including your employees, via social engineering.
Hardened Linux Repository with immutability
Using a Hardened Linux Repository with immutability should be mandatory. None of this is about being paranoid; it’s about being prepared. Sure, you can laugh at me, say it is overkill or too expensive. Laughing is healthy, so keep doing that. But listen to me. It is not overkill and is not more costly. It is not even more cumbersome, except for the inevitable extra steps in a zero-trust workflow. There is even a bonus: when ransomware strikes, listening to me might keep that smile on your face!
You may have seen my blog post, Revised script for decrypting datacenter credentials from the Veeam Backup & Replication database | Working Hard In IT. That post does not mean Veeam or Windows cryptography implementations are inherently flawed; it highlights the inevitable consequences of having root access to your system. Hence, you can guess that you require any server role in your Veeam backup environment to be hardened as much as possible. Veeam is therefore also providing a Veeam Software Appliance (VeeamSoftwareAppliance_13.0.0.12109.BETA2.iso).
When you build your own Veeam Hardened Linux Repository, you must take technical measures and establish a process flow to service genuine requests and protect against both external and internal malicious actions. All that is taken care of by the Veeam appliance approach. Not too shabby, not too shabby at all!
A hardened Linux repository is a tactical and strategic asset in a backup fabric. It gives you a fighting chance and serves as an ark of Noah to start over from. Below, we will discuss why it should be a mandatory component in your architecture.

Immutability is essential
If your backups can be deleted, encrypted, or tampered with, you don’t have backups, but “hope”. You have a false sense of security. Immutability ensures that your backup data is locked down and protected from malware or rogue administrators.
Pre-Hardened OS
Security isn’t just about firewalls and antivirus. It’s about reducing your attack surface. A pre-hardened OS turns off unnecessary services, enforces strict access controls, and aligns with best practices from the outset. That means a lot of work and worrying that you don’t have to do.
STIG Compliance
Want to sleep better at night? Align with government-grade security standards. STIG compliance ensures your repository is secure, and you can reference Veeam to support that claim when needed.
Ransomware Resilience
Ransomware loves backup data. It’s the first thing attackers go after. A hardened repository isolates your backups and enforces immutability, making it a fortress against encryption attempts.
Auditability & Compliance
GDPR, HIPAA, and ISO 27001 compliance isn’t optional. Hardened repositories support forensic analysis, secure logging, and system integrity checks. You’re not just protected; you can prove to an auditor. Yes, compliance is a thing, and while the actual protection comes before compliance reports, we cannot ignore that.
Operational Stability
Misconfigurations are the silent killers of IT. A hardened repo minimizes that risk. With pre-applied security settings, even teams without deep Linux chops can deploy confidently.
Maintenance without effort
Security updates and patches? Streamlined. Veeam handles the OS and repo updates, so you don’t have to babysit your infrastructure. I still need to determine if the ISO can also handle firmware updates for you.
Insider Threat Mitigation
Not every threat comes from outside. Role-based access, BMC port protection, and restricted shell access help prevent internal sabotage, whether accidental or intentional.
Strategic Value
All the above is not just a technical and operational advantage. It’s a business win. A hardened repo ensures your backups are a reliable recovery point, even when everything else goes sideways. It is your Ark of Noah! And guess what? Have redundant Arks! One is none, two is one 😉.
Why Veeam’s Just Enough OS ISO Is a Game-Changer
You could build your own hardened Linux repo. I’ve done it. It works. But it’s not for everyone. Veeam’s Hardened Repository ISO (VeeamHardenedRepository_2.0.0.8_20250117.iso) streamlines the process, automates the hardening, and provides a vendor-backed solution that’s ready for production.
The future Veeam Just Enough OS hardened repository (VeeamJEOS_13.0.0.12109.BETA2.iso) is well locked down, and privileged actions require security officer approval. While that is essential in a zero-trust world, it also means you must have your processes streamlined and communication lines open. When people need to reset a password or require root access for troubleshooting, they cannot wait until the next business day when the security officer is at work, let alone a week, because somebody has to bring it up at the weekly CISO approval board.
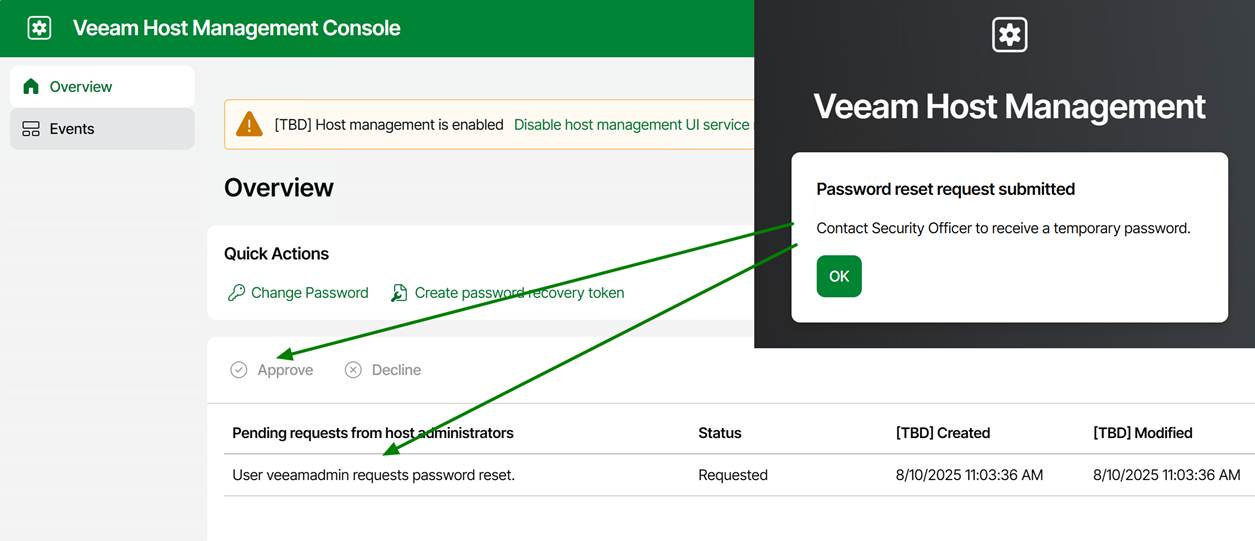
Look, you can roll your hardened repository if you have the skills, time, and appetite for ongoing maintenance. I have done that and might still do so depending on the environment and requirements. However, if you’re looking for a secure, compliant, and low-maintenance solution that works, Veeam Hardened Repository ISO or its successor, Veeam Just Enough OS, is the answer. By starting today, testing these solutions, you gain insights and experience using them, and will be optimally prepared for when Veeam Backup & Replication v13 becomes available. The Veeam Hardened Repository ISO has experimental support, enabling its use in production environments. At the very least, you can store one backup copy on it today. If you are interested in this for future use, consider Veeam Just Enough OS (VeeamJEOS_13.0.0.12109.BETA2.iso) as part of the future V13 release. However, that one is not yet production-ready. But it won’t be long now when we look at the post by Anton Gostev on LinkedIn! At the time of writing this post, it should be less than a month.
Conclusion
The above is not paranoia, and it’s not just about ticking boxes for compliance. It’s about building a backup strategy that survives real-world threats. And in that world, immutability isn’t optional. It’s your insurance policy. Look, I have seen the devastation ransomware causes. It is a horrible place to be. I don’t want you to be in that world of hurt. However, we cannot prevent it. You are a target, and you will get hit. It is a question of when, not if. So make sure you have the means to come out on top!



