In Veeam Backup & Replication (VBR) v11 we have the new hardened repository host. I Have also shared some other findings in previous blogs. You add this to the Veeam managed servers via single-use credentials. These are not stored on the VBR server. That account only needs permission on the repository volumes after adding the repository server to the VBR managed servers. Let’s investigate how to change the service account on a Veeam hardened repository in case we ever need to. Warning, this early info and not official guidance.
Where is that account configured for use with Veeam?
Naturally, we created the account for adding the hardened repository to the Veeam managed servers. We also set the correct permission on the backup repository volumes. After adding the repository host to Veeam managed servers, with the single-use credential method, we removed this account from the sudo group and that’s it.
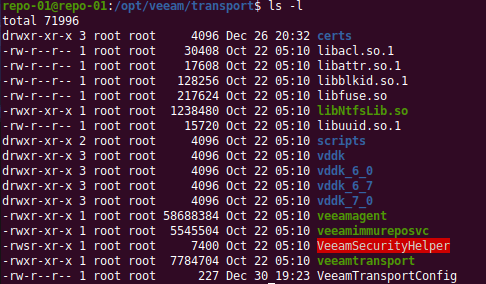
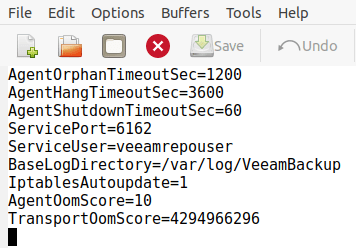
The VBR server itself does not hold the credentials. The credentials only live on the repository host. But where is that configured? Well under Under /opt/veeam/transport you will find a config file VeeamTransportConfig.
Under /opt/veeam/transport you find a config file VeeamTransportConfig
Open it up in your favorite editor and take a look.
ServiceUser is where the user account is configured
Change the service account on a Veeam hardened repository
From my testing, you can simply change the user account in the VeeamTransportConfig file if you ever need to. When you do, save the file and restart the veeamtransport service so it takes effect.
sudo service veeamtransport restart
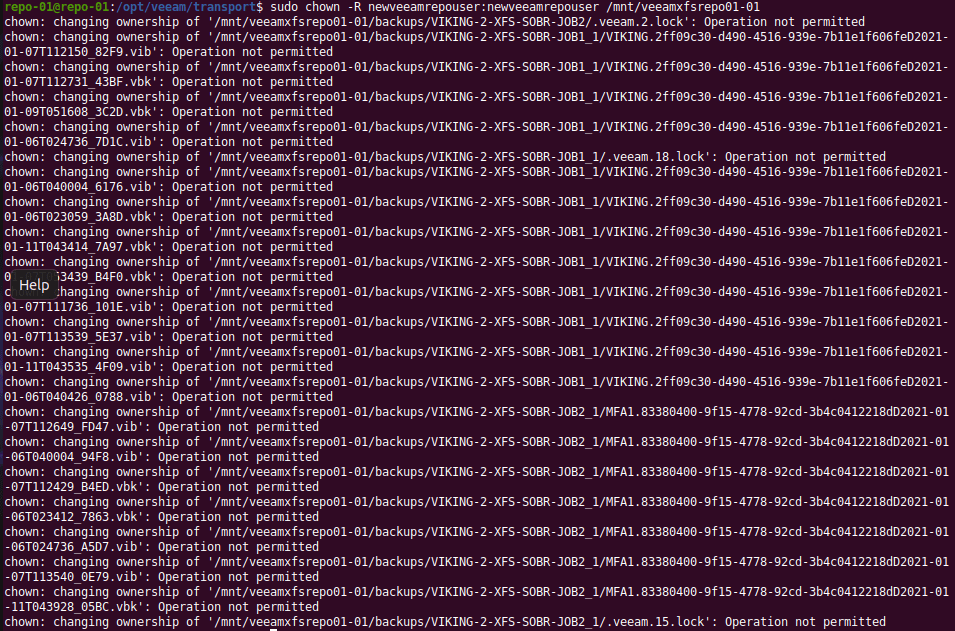
When you change this service user you must also take care of the permissions on the repository folder(s).
We change the ownership recursively for the drive mount to that user.
The permissions for the user should still be what it needs to be (chmod 700)
Now, due to the immutability of the backup files changing the owner will fail on those files but that is OK.
Don’t panic, you’ll be fine. Backups & restores will work.
For reading and restoring then tests show that this still works. Backup wise this will run just fine. It is all pretty transparent from the Veeam Backup & Replication side of things. I used to think I would need to run a full backup afterward but Veeam seems to handle this like a champ and I do not have to take care of that it ssems. We’ll try to figure out more when V11 is generally available.
Now, you still might want to give Veeam support a call when you want or need to do this. Remember, this is just informational and sharing what I learn in the lab.
Conclusion
Normally you will not need to change this service account. But it might happen, either because of a policy that mandates this, etc. That is the reason I wanted to find out how to do this and if you can do this without breaking the backup cycles. I also think this is why you can convert an existing Linux repository to a hardened one.
As I have started to use XFS in bite-size deployments to gain experience with it I wanted to write up some of the toolings I found to manage XFS file systems. Here’s how to check/repair/defragment an XFS volume.
My main use case for XFS volumes is on hardened Linux repositories with immutability to use with Veeam Backup & Replication v11 and higher. It’s handy to be able to find out if XFS needs repairing and if they do, repair them. Another consideration is fragmentation. You can also check that and defrag the volume.
Check XFS Volume and repair it
xfs_repair is the tool you need. You can both check if a volume needs repair and actually repair it with the same tool. Note that the use of xfs_check has been depreciated or is not even available (anymore).
To work with xfs_repair you have to unmount the filesystem, so there will be downtime. Plan for a maintenance window.
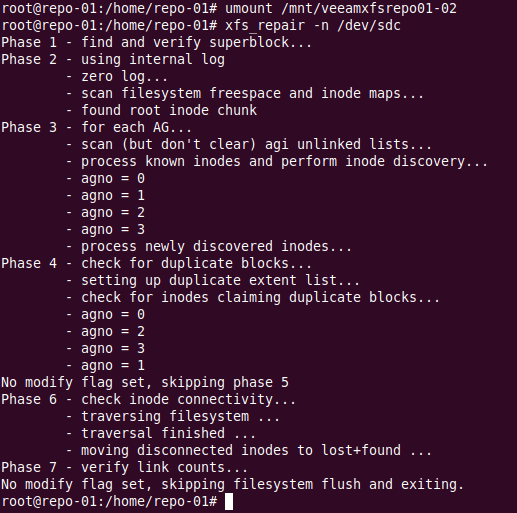
To check the file system use the -n switch
sudo xfs_repair -n /dev/sdc
Check, repair and defragment an XFS volumea dry run with xfs_repair -n
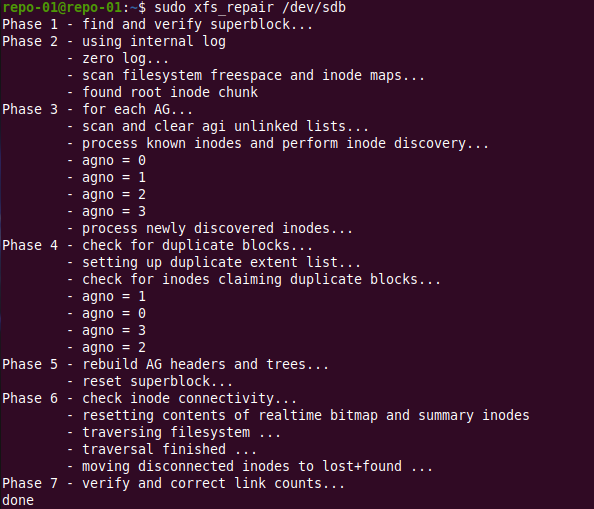
There is nothing much to do but we’ll now let’s run the repair.
sudo xfs_repair /dev/sdc
Repairing an XFS file system
The output is similar as for the check we did for anything to repair is basically a dry run of what will be done. In this case, nothing.
Now, don’t forget to mount the file system again!
sudo mount /dev/sdc /mnt/veeamsfxrepo01-02
Check a volume for fragmentation and defrag it
Want to check the fragmentation of an XFS volume? You can but again, with xfs_db. The file system has to be unmounted for that or you will get the error xfs_db: can’t determine device size. To check for fragmentation run the following command against the storage device /file system.
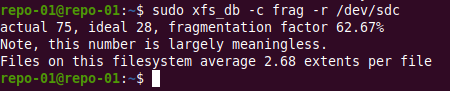
sudo xfs_db -c frag -r /dev/sdc
A lab simulation of sudo xfs_db -c frag -r /dev/sdc – Yeah know it’s meaningless 😉
Cool, now we know that we can defrag it online. For that we use xfs_fsr.
xfs_fsr /devsdc /mnt/veeamxfsrepo01-02
There is nothing to do in our example
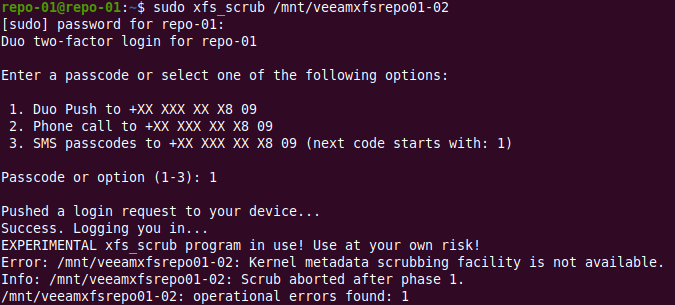
xfs_scrub – the experimental tool
xfs_scrub is a more recent addition but the program is still experimental. The good news is it will check and repair a mounted XFS filesystem. At least it sounds promising, right? It does, but it doesn’t work (Ubuntu 20.04.1 LTS).
No joy – still a confirmed bug – not assigned yet, importance undecided. Not yet my friends.
Conclusion
That’s it. I hope this helps you when you decide to take XFS for a spin for your storage needs knowing a bit more about the tooling. As said, for me, the main use case is hardened Linux repositories with immutability to use with Veeam Backup & Replication v11. In a Hyper-V environment of course.
A File-Level Restore in a hardened environment can trip you up. In Veeam Backup & Replication the ability to do file-level restores from virtual machine backups is a handy option to have. In secured environments with an isolated and protected Veeam backup fabric, this is not always a straightforward or fast process. Let’s look at this and make some suggestions for a solution or workarounds.
The Veeam Backup browser for File-Level Restores
Veeam File-Level Restore in a hardened environment
Nowadays, it is a common best practice that the Veeam Backup & Replication environment is isolated and independent from the fabrics it protects. It is even more than a best practice and ransomware educated many of us fast and hard on the need for this.
In such an environment every server in the Veeam backup fabric solution is isolated, with their own credentials and not joined or in any way dependent on the environment it is protecting. Dedicated accounts are used to run the actual backup jobs and these are not used for normal administrative or operational tasks.
The majority of Veeam functionality works just fine in such an environment. But there are some things that need to be addressed. One such thing is a file-level restore (FLR). In a secured and isolated environment, an FLR job cannot leverage admin shares to gain access to the virtual machine to where files are being restored or access the data in the backup. To work around this Veeam can leverage PowerShell Direct by which it can securely restore the files into the virtual machine anyway.
But leveraging PowerShell Direct comes at the cost of speed. 7 MB/s is okay for a small number of smaller files. It becomes frustratingly slow when it comes to restoring many and larger files. Minutes turn into hours. In some cases, this just won’t do. In our case, the DBA who needed to do the database restore was not happy and the developers waiting for the restored database were not overly pleased either.
So what other options do we have?
Set up a secured file share in the protected environment
Below we will discuss the other options you have for a File-Level Restore in a hardened environment via FLR in Veeam Backup & Recovery. But first, we prepare a landing zone in the secured environment where we can copy restored files to. For this, we set up a restore share in the protected environment where a few admins that are responsible for backup and restores can write to. No one else can enumerate, read, or write to that share. When a file gets restored there they can copy it over to where the people that need it can access it. This helps protect and limit access to restored files to just the people that need to get to it. The accounts used to access that share from the isolated backup environment do not get admin permissions on the system where that share resides or anywhere else.
Providing a restore share in the protected environment is safe. You only allow certain admins to have access to it, no one else. Since the less trusted environment (the one we protect) allows access from a more secure environment (the backup environment) this does not expose the backup environment to extra danger. At no point does this allow any access to the backup environment from the protected environment.
Use the FLR wizard to copy the files
You can use the FLR wizard to copy the file locally in the secured Veeam backup environment.
File-Level Restore in a hardened environmentFLR, copy the file to restore to a local folder
From there you can copy it to the restore share in the protected environment. This is very fast as nothing is. On our network we get 230 MB/s.
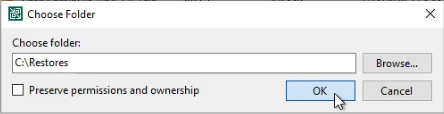
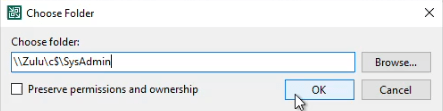
But what if you don’t have the space for that locally? Not everyone can have a large local restore disk onWould it not be handy to copy it to restore share in the protected environment directly? Well yes, you can try in the wizard and it will ask for the credentials to access the file share.
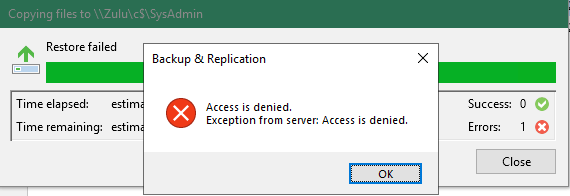
But it will fail to read and restore the backups but this will fail with an “Access is denied” error.
You could work around it if you use the account VBR uses to actually make the backups. But that won’t do. For one those credentials should be guarded and not use by anything or anyone but VBR. Secondly, it doesn’t work anyway.
So are you out of luck? The good news is no, you are not, so read on!
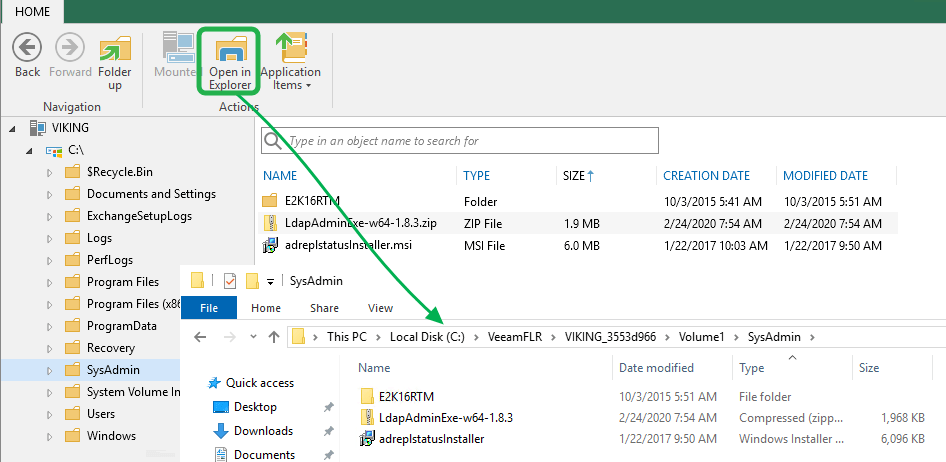
Copy the files directly from the VeeamFLR mountpoint
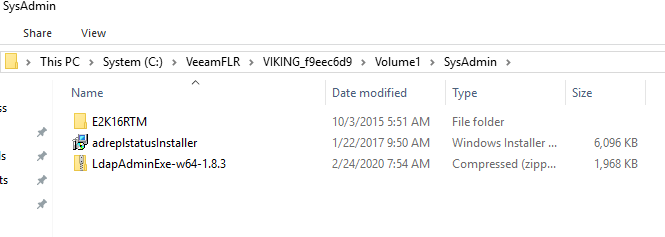
If you don’t have the space to restore the file locally in the secure backup environment, there is another trick. When you look at the restore log you will see what the mount server is. That is the node where you can find the C:\VeeamFLR folder, which is where the content of the virtual Machine VHDX volumes is being mounted. This means that on that node you can navigate to the folder or files you want to restore.
Copy the files directly from the VeeamFLR mountpoint
Select the ones you want to recover and just copy them. Navigate to restore share in the protected environment. You just need to provide the credentials of the dedicated account with write access to that share. Those are the only rights you need on that share. The copy is again fast at 230 MB/s. That is a lot better than 7MB/s.
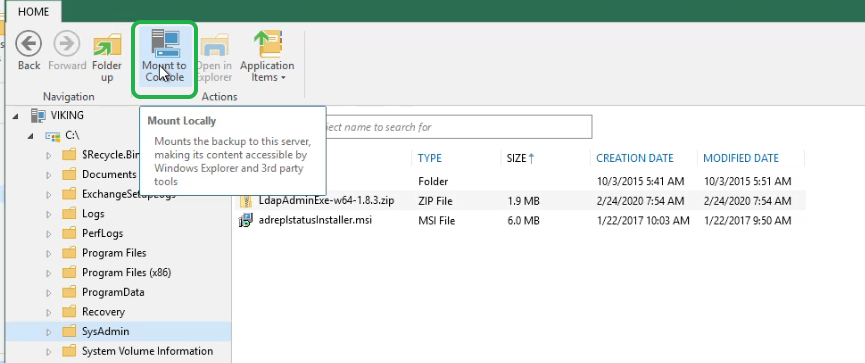
There is an issue with this, however. In this scenario, you need access to the server where the volumes of the virtual machine get mounted. Normally that would be the local repository where the backup files reside and guess what, you lock these down as much as possible and don’t log on to them unless needed. You could specify another, but then it needs to be a server where you have access to and it copies the data over the network, which is slower. With 10Gbps or more that’s not an issue but with 1Gbps, it can take a while with a lot of large files. Can we fix this? Yes. with Mount to Console!
Mount to Console to the rescue
But hey, this would not be Veeam if they did not have yet another option on their sleeve! You can use the Mount to Console button on the ribbon of the Veeam Backup browser to create an extra mount point on your VBR console server. From here you can copy the files to the restore file share in the protected environment a lot faster as well. All you need for this is a local user (non-administrator account) with the Veeam Restore Operator role.
Mount to console to the rescueEt voila, you can browse the files even if you don’t have space on your console server
Veeam Enterprise Manager addresses the challenges we worked around here. But you’ll need Enterprise (plus) to get full-featured use of that. It is nice as it takes care of the above scenario and you can have restore rights assigned to people without compromising your backup environments operational security. So, yes, use Enterprise Manager when possible. If not, see the above workarounds for other options.
Conclusion
Having some insights into how Veeam Backup & Replication works can be in handy at times. It also helps if you can think a bit outside the box and act on those insights to come up with some alternatives or workarounds. This is exactly what we did here with great results. The DBA could do his restores faster while the devs have the version of the database they needed. Do note that the correct answer lies in Veeam Enterprise manager, but lacking that. You now have some options. I hope these insights into a File-Level Restore in a hardened environment help you out someday.
Recently I got to diagnose a really interesting Veeam Backup & Replication symptom. Imagine you have a backup environment that runs smoothly. All week long but then, suddenly, running backup jobs stall. News jobs that start do not make an ounce of progress. It is as the state of every job is frozen in time. Let’s investigate and dive into troubleshooting 100% stalled Veeam backup jobs.
That morning, the backup jobs had not made an ounce of progress since the night before and they never will, you can leave this for days sometimes a job in between does seem to work properly, but most often not so the job queue builds up.
Troubleshooting 100% stalled Veeam backup jobs
When looking at the stalled jobs, nothing in the Veeam GUI indicates an error. Looking at the Windows event logs we see no warning, error, or critical messages. All seems fine. As this Veeam environment uses ReFS on storage spaces we are a bit weary. While the bugs that caused slowdowns have been fixed, we are still alert to potential issues. The difference with the know (fixed) ReFS issues that this is no slowdown, No sir, the Veeam backup jobs have literally frozen in time but everything seems to be functional otherwise.
Another symptom of this issue is that the synthetic full backups complete perfectly well, but they finfish with an error message none the less due to a time out. This has no effect on the synthetic backup result (they are usable) but it is disconcerting to see an issue with this.
On top of that, data copies into the ReFS volumes work just fine and at an excellent speed. Via performance monitor, we can see that the rotation of full regions from mirror to parity is also working well once the mirror tier has reached a specified capacity level.
Time to dive into the Veeam logs I would say.
Veeam backup job log
So the next stop is the Veeam logs themselves. While those can seem a little intimidating, they are very useful to scroll through. And sure enough, we find the following in one of the stalled jobs its backup log.
This goes on all through the night …
For hours on end … it goes on that way.
VIRTUAL MACHINE TASK LOGS 1
When we look at the task log of ar virtual machine that is still at 0% we see the same reflected there. Note that nothing happens between 22:465 and 05:30, that’s when I disabled and enabled the vNIC of the preferred networks in the VBR virtual machine and it all sprung back to life.
notice the total stand still form 22:46 to 05:30 …
So it is clear we have a network issue of some sort. We checked the repository servers and the Hyper-V cluster but there everything is just fine. So where is it?
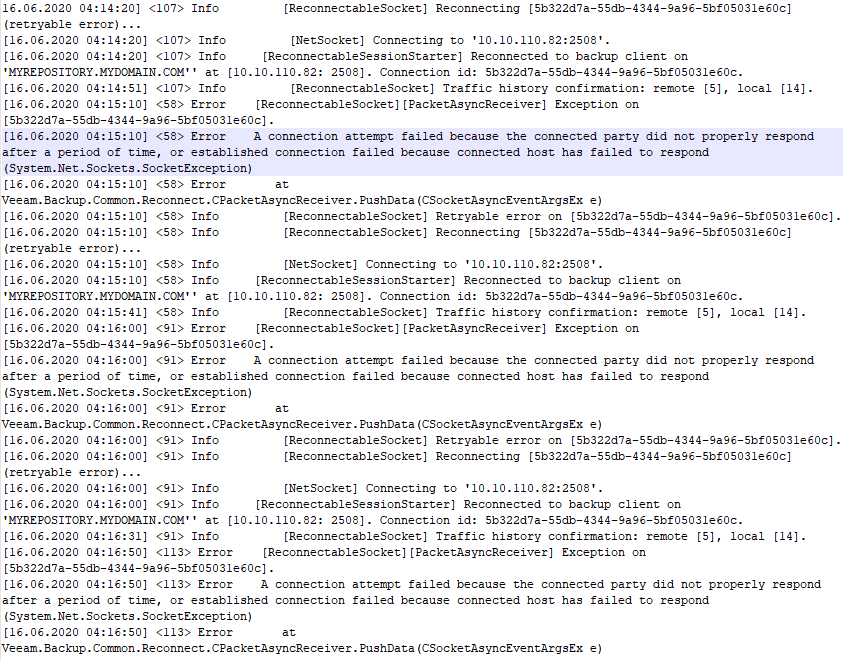
Virtual Machine task logs 2
We dive into the task log of one of the virtual machines who’s backing up and that is hanging at 88%. There we see one after the other reconnect to the repository IP (over the preferred network as defined in VB). That also happens all night long until we reset the VBR virtual machine’s preferred network vNICs. In the log snippet below notice the following:
Error A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond (System.Net.Sockets.SocketException)
From the logs we deduct that the network error appears to be on the VBR virtual machine itself. This is confirmed by the fact that bouncing the vNICs of the preferred network (10.10.110.x is the preferred network subnet) on the VBR virtual machine kicks the jobs back into action. So what is the issue? So we start checking the network configurations and settings. The switch ports, pNICs, vNIC, vSwitches etc. to find out what’s going on, As it seems to work for days or a week before the issue shows up we suspect a jumbo frame issue so we start there.
The solution
While checking the configuration we to make sure jumbo frames are enabled on the vNIC and the pNICs of the vSwitch’s NIC team. That’s when we notice the jumbo frames are missing from those pNICs. So we set those again.
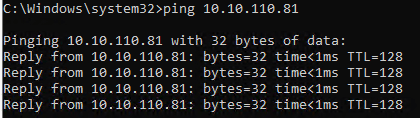
From the VBR virtual machine we run some ping tests. The default works fine.
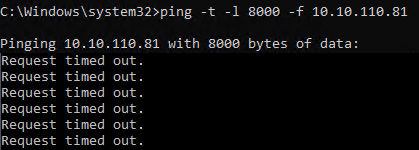
When we test with jumbo frames however we notice something. The ping tests do not complain about jumbo frames being too large and that with the “do not fragment” option set the “Packet needs to be fragmented but DF set.” Note it just says “request timed out”. This indicates an issue right here, jumbo frames are set but they do not work.
So the requests time out, it does not complain about the jumbo frames … so we have another issue here than just the jumbo frame settings
As the requests time out and the ping test does not complain about the jumbo frames we have another issue here than just the jumbo frame settings. It smells of a firmware and/or driver issue. So we dive a bit further. That’s when I notice the driver for the relevant pNICs (Broadcom) is the inbox Windows driver. That’s no good. The inbox drivers only exists to be able to go out and fetch the vendor’s driver and firmware when need, as a courtesy so to speak. We copy those to the hosts that require an update. In this case, the nodes where the VBR virtual machine can run. The firmware update requires a reboot. When the host is up and the VBR virtual machine is running I test again.
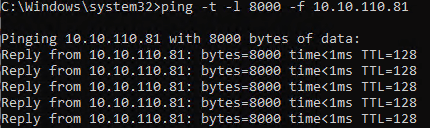
Bingo, now a ping test succeeds.
Success
What happened?
So did we really forget to update the drivers? Did we walk out of the offices to go in lockdown for the Corona crisis and forget about it? In the end, it turned out they did run the updates for the physical hosts. But for some reason, the Broadcom firmware and drivers did not get updated properly. However, that failed update seems to have also removed the Jumbo frame settings from the pNICs that are used for the virtual switch. After fixed both of these we have not seen the issue return.
Remarks
The preferred networks do not absolutely have to be present on the VBR server itself. Define, yes, present, no. But it speeds up backup job initialization a lot when they are there present on the VBR server and Veeam also indicates to do so in their documentation.
Why jumbo frames? Ah well the networks we use for the preferred networks are end to end jumbo frame enabled. So we maintain this in to the VBR server. We might get away by not setting jumbo frames on the VBR server but we want to be consistent.
Conclusion
It pays to make sure you have all settings correctly configured and are running the latest and greatest known good firmware. But that should have been the case here. And it all worked so well for quite a while before the backup jobs stall. The issue can lie in the details and sometimes things are not what you assume they are. Always verify and verify it again.
I hope this helps someone out there if they are ever troubleshooting 100% stalled Veeam backup jobs If you need help, reach out in the comments. There are a lot of very experienced and respected people around in my network that can help. Maybe even I can lend a hand and learn something along the way.