
Introduction
As I have started to use XFS in bite-size deployments to gain experience with it I wanted to write up some of the toolings I found to manage XFS file systems. Here’s how to check/repair/defragment an XFS volume.
My main use case for XFS volumes is on hardened Linux repositories with immutability to use with Veeam Backup & Replication v11 and higher. It’s handy to be able to find out if XFS needs repairing and if they do, repair them. Another consideration is fragmentation. You can also check that and defrag the volume.
Check XFS Volume and repair it
xfs_repair is the tool you need. You can both check if a volume needs repair and actually repair it with the same tool. Note that the use of xfs_check has been depreciated or is not even available (anymore).
To work with xfs_repair you have to unmount the filesystem, so there will be downtime. Plan for a maintenance window.
To check the file system use the -n switch
sudo xfs_repair -n /dev/sdc
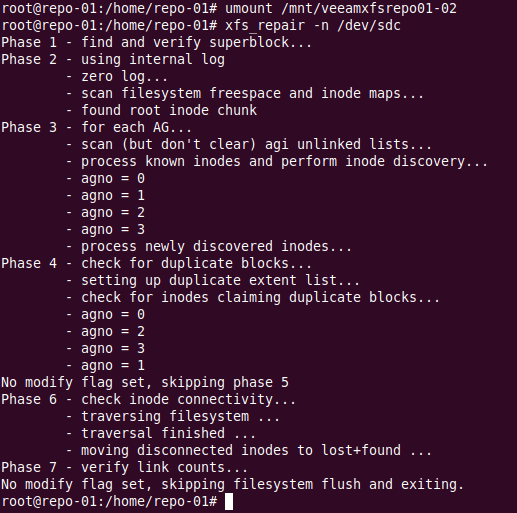
There is nothing much to do but we’ll now let’s run the repair.
sudo xfs_repair /dev/sdc
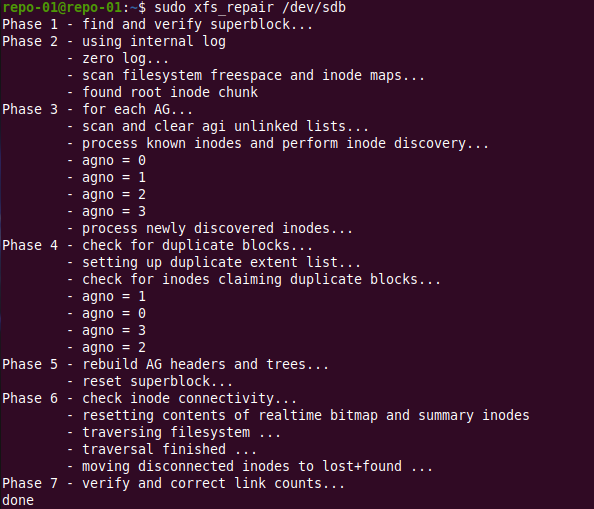
The output is similar as for the check we did for anything to repair is basically a dry run of what will be done. In this case, nothing.
Now, don’t forget to mount the file system again!
sudo mount /dev/sdc /mnt/veeamsfxrepo01-02
Check a volume for fragmentation and defrag it
Want to check the fragmentation of an XFS volume? You can but again, with xfs_db. The file system has to be unmounted for that or you will get the error xfs_db: can’t determine device size. To check for fragmentation run the following command against the storage device /file system.
sudo xfs_db -c frag -r /dev/sdc
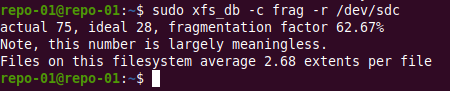
Cool, now we know that we can defrag it online. For that we use xfs_fsr.
xfs_fsr /devsdc /mnt/veeamxfsrepo01-02

xfs_scrub – the experimental tool
xfs_scrub is a more recent addition but the program is still experimental. The good news is it will check and repair a mounted XFS filesystem. At least it sounds promising, right? It does, but it doesn’t work (Ubuntu 20.04.1 LTS).
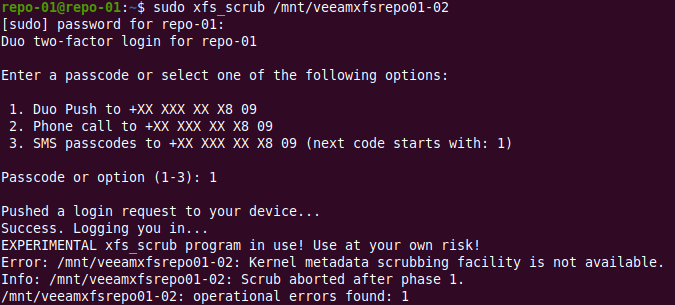
Conclusion
That’s it. I hope this helps you when you decide to take XFS for a spin for your storage needs knowing a bit more about the tooling. As said, for me, the main use case is hardened Linux repositories with immutability to use with Veeam Backup & Replication v11. In a Hyper-V environment of course.











