
Introduction
Recently I got to diagnose a really interesting Veeam Backup & Replication symptom. Imagine you have a backup environment that runs smoothly. All week long but then, suddenly, running backup jobs stall. News jobs that start do not make an ounce of progress. It is as the state of every job is frozen in time. Let’s investigate and dive into troubleshooting 100% stalled Veeam backup jobs.
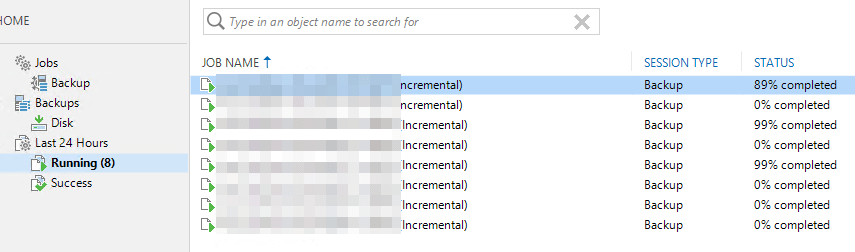
Troubleshooting 100% stalled Veeam backup jobs
When looking at the stalled jobs, nothing in the Veeam GUI indicates an error. Looking at the Windows event logs we see no warning, error, or critical messages. All seems fine. As this Veeam environment uses ReFS on storage spaces we are a bit weary. While the bugs that caused slowdowns have been fixed, we are still alert to potential issues. The difference with the know (fixed) ReFS issues that this is no slowdown, No sir, the Veeam backup jobs have literally frozen in time but everything seems to be functional otherwise.
Another symptom of this issue is that the synthetic full backups complete perfectly well, but they finfish with an error message none the less due to a time out. This has no effect on the synthetic backup result (they are usable) but it is disconcerting to see an issue with this.
On top of that, data copies into the ReFS volumes work just fine and at an excellent speed. Via performance monitor, we can see that the rotation of full regions from mirror to parity is also working well once the mirror tier has reached a specified capacity level.
Time to dive into the Veeam logs I would say.
Veeam backup job log
So the next stop is the Veeam logs themselves. While those can seem a little intimidating, they are very useful to scroll through. And sure enough, we find the following in one of the stalled jobs its backup log.
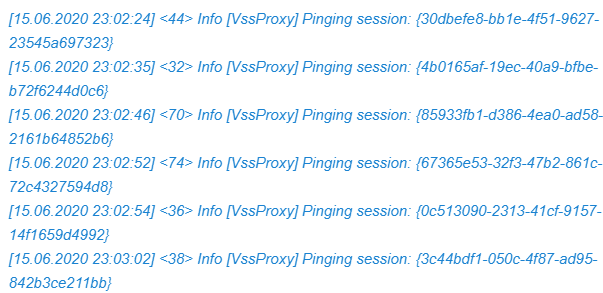
For hours on end … it goes on that way.
VIRTUAL MACHINE TASK LOGS 1
When we look at the task log of ar virtual machine that is still at 0% we see the same reflected there. Note that nothing happens between 22:465 and 05:30, that’s when I disabled and enabled the vNIC of the preferred networks in the VBR virtual machine and it all sprung back to life.

So it is clear we have a network issue of some sort. We checked the repository servers and the Hyper-V cluster but there everything is just fine. So where is it?
Virtual Machine task logs 2
We dive into the task log of one of the virtual machines who’s backing up and that is hanging at 88%. There we see one after the other reconnect to the repository IP (over the preferred network as defined in VB). That also happens all night long until we reset the VBR virtual machine’s preferred network vNICs. In the log snippet below notice the following:
Error A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond (System.Net.Sockets.SocketException)
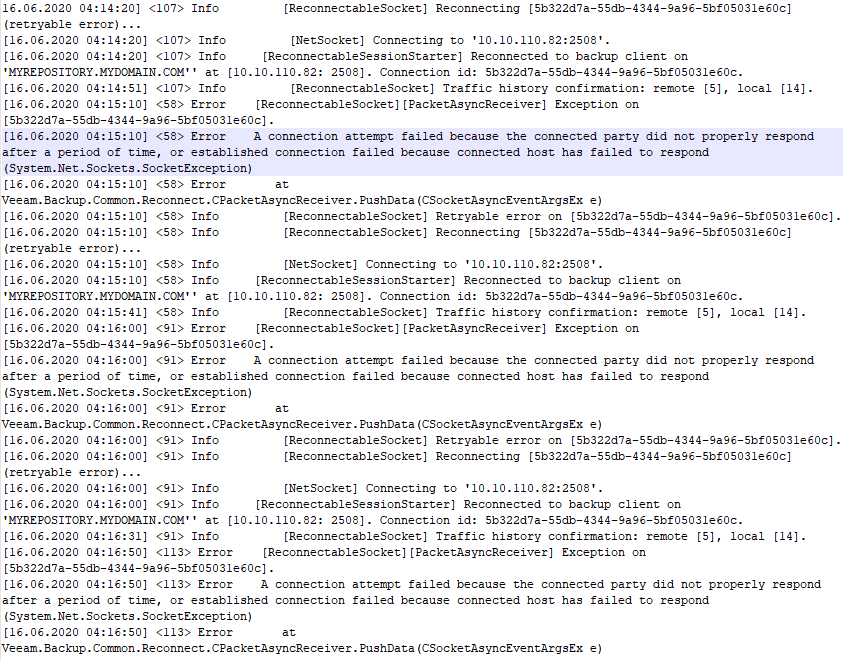
From the logs we deduct that the network error appears to be on the VBR virtual machine itself. This is confirmed by the fact that bouncing the vNICs of the preferred network (10.10.110.x is the preferred network subnet) on the VBR virtual machine kicks the jobs back into action. So what is the issue? So we start checking the network configurations and settings. The switch ports, pNICs, vNIC, vSwitches etc. to find out what’s going on, As it seems to work for days or a week before the issue shows up we suspect a jumbo frame issue so we start there.
The solution
While checking the configuration we to make sure jumbo frames are enabled on the vNIC and the pNICs of the vSwitch’s NIC team. That’s when we notice the jumbo frames are missing from those pNICs. So we set those again.
From the VBR virtual machine we run some ping tests. The default works fine.
When we test with jumbo frames however we notice something. The ping tests do not complain about jumbo frames being too large and that with the “do not fragment” option set the “Packet needs to be fragmented but DF set.” Note it just says “request timed out”. This indicates an issue right here, jumbo frames are set but they do not work.
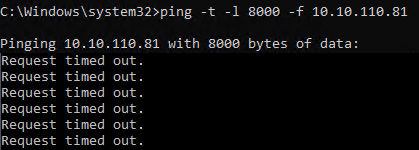
As the requests time out and the ping test does not complain about the jumbo frames we have another issue here than just the jumbo frame settings. It smells of a firmware and/or driver issue. So we dive a bit further. That’s when I notice the driver for the relevant pNICs (Broadcom) is the inbox Windows driver. That’s no good. The inbox drivers only exists to be able to go out and fetch the vendor’s driver and firmware when need, as a courtesy so to speak. We copy those to the hosts that require an update. In this case, the nodes where the VBR virtual machine can run. The firmware update requires a reboot. When the host is up and the VBR virtual machine is running I test again.
Bingo, now a ping test succeeds.
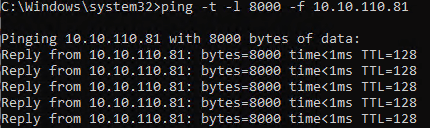
What happened?
So did we really forget to update the drivers? Did we walk out of the offices to go in lockdown for the Corona crisis and forget about it? In the end, it turned out they did run the updates for the physical hosts. But for some reason, the Broadcom firmware and drivers did not get updated properly. However, that failed update seems to have also removed the Jumbo frame settings from the pNICs that are used for the virtual switch. After fixed both of these we have not seen the issue return.
Remarks
The preferred networks do not absolutely have to be present on the VBR server itself. Define, yes, present, no. But it speeds up backup job initialization a lot when they are there present on the VBR server and Veeam also indicates to do so in their documentation.
Why jumbo frames? Ah well the networks we use for the preferred networks are end to end jumbo frame enabled. So we maintain this in to the VBR server. We might get away by not setting jumbo frames on the VBR server but we want to be consistent.
Conclusion
It pays to make sure you have all settings correctly configured and are running the latest and greatest known good firmware. But that should have been the case here. And it all worked so well for quite a while before the backup jobs stall. The issue can lie in the details and sometimes things are not what you assume they are. Always verify and verify it again.
I hope this helps someone out there if they are ever troubleshooting 100% stalled Veeam backup jobs If you need help, reach out in the comments. There are a lot of very experienced and respected people around in my network that can help. Maybe even I can lend a hand and learn something along the way.



