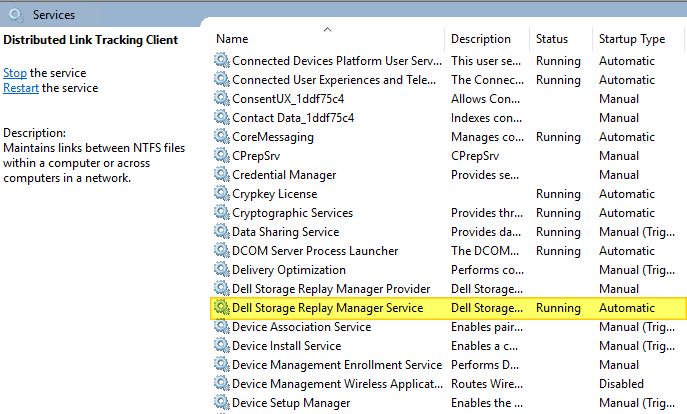
Veeam Hardened Repositories on DELL R740XD2 Servers
Recently I got the opportunity to build Veeam Hardened Repositories on DELL R740XD2 Servers. Those repositories were needed to deploy a Veeam Scaleout Backup Repository (SOBR). Yes, Linux systems leveraging XFS for Fast Clone and immutability.
Technologies used
Veeam Backup & Replication
First of all, you need Veeam Backup & Replication (VBR) v11a or later. I run VBR on Windows Server 2022 at the time of writing.
Linux operating system
Next to that, I use Ubuntu 20.04 LTS for the Veeam hardened repositories. While the release of 22.04 LTS imminent at the time of writing this, with OEM hardware support as a requirement I stick to 20.04 for now. The file system is XFS with Fast Cloning enabled.
Servers with Direct Attached Storage (DAS)
I leverage RAID 60 on Dell EMC R740-DX2 servers. The servers boot from mirrored BOSS SSDs and have a PERC H740P raid controller with 8GB of cache and 26 3.5″ HDD attached. We need to optimize for both cost and capacity, therefore we use 3.5″ drives. With disk sizes ranging from 8TB to 16TB, this brings us real-world usable storage from 145TB to 290TB with two global hot spares.
Now the RAID 60 is one big virtual disk group containing all disks bar the 2 assigned as global hot spares. This makes sure we engage all disks to help with IOPS, latency, throughput. The 8Gbps helps smooth things out. Depending on the scale of your deployment you can create one VEEAM SOBR extent per server of carve multiple VDISKS out of the available storage.
You also have the option to leverage LVM on linux if that suits your need, but in that case I do it only for volume management, dat protection comes from the physical RAID controller.
There is not right or wrong way there. Select what suits you best, but the golden rule is to keep it simple.
Networking
Networking is 1Gbps for DRAC/Host connectivity and dual 10Gbps or 25Gbps for backup traffic. The switches are Dell EMC PowerSwitch S52XXF-ON series. Awesome kit!
Extra Security
Finally, I provide some extra security. I use DUO as an MFA provider as they have an excellent pam_duo module. We often use our smartphones for MFA. But there are plenty of use cases for using security keys. For those, I like the FEITIAN biometric models such as the K27 (USB-A )and the K26 (USB-C).

The Journey of building Veeam Hardened Repositories on DELL R740XD2 Servers
Maybe you are interested in how I set up these Veeam Hardened Repositories on DELL R740XD2 Servers? If so, you might be in luck. I hope to blog about this journey for both my own reference to share the experience. This will take several blog posts and in those, I will highlight different parts of the solution. If you want to learn more about the Veeam hardened Repository I recommend you read my blog series I did last year:
Veeam Hardening Linux Repository – Part 1 | StarWind Blog (starwindsoftware.com)., Veeam Hardening Linux Repository – Part 2 | StarWind Blog (starwindsoftware.com), Veeam Hardening Linux Repository – Part 3 | StarWind Blog (starwindsoftware.com)
As I realize not all of you will get your hands on such hardware I have a PowerShell script that creates Hyper-V virtual machines to use in the lab and practice with. Those VMs emulate the DELL hardware setup.