If you ever get the following error while trying to create a Continuously Available File Share in Windows Server 2012 “The request is not supported”
If on top you find this entry in the Microsoft-Windows-SmbServer/Operational event log:
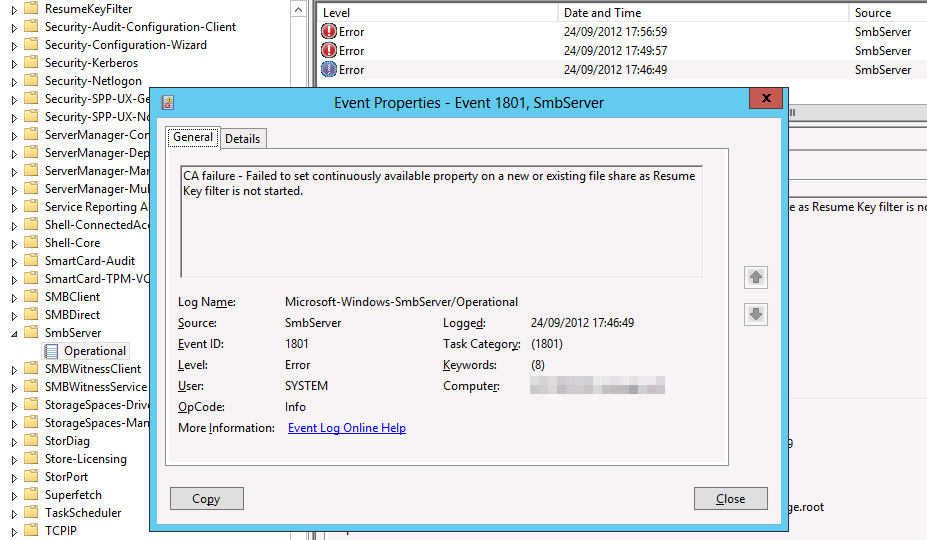
Log Name: Microsoft-Windows-SmbServer/Operational
Source: Microsoft-Windows-SmbServer
Date: 24/09/2012 17:56:59
Event ID: 1801
Task Category: (1801)
Level: Error
Keywords: (8)
User: SYSTEM
Computer: server1.lab.test
Description:
CA failure – Failed to set continuously available property on a new or existing file share as Resume Key filter is not started.
First of all check with fsutil if you have short file names enabled on the volumes on which you are trying to create the continuous available file share:
- Log on to the node running the File role and open a elevated command prompt to run the following on the volume/partition in play, F: in this example.
fsutil 8dot3name query F:
The volume state is: 0 (8dot3 name creation is enabled).
The registry state is: 2 (Per volume setting – the default).
Based on the above two settings, 8dot3 name creation is enabled on F:
- I chose to enable or disable short file names per volume
fsutil 8dot3name set 2
The registry state is now: 2 (Per volume setting – the default).
- Disable short file names on the volume at hand
fsutil 8dot3name set f: 1
Successfully disabled 8dot3name generation on f:
- Remove any short file names present on this volume
fsutil 8dot3name strip f:
Scanning registry…
Total affected registry keys: 0
Stripping 8dot3 names…
Total files and directories scanned: 6
Total 8dot3 names found: 3
Total 8dot3 names stripped: 3
For details on the operations performed please see the log:
“C:UsersUSER~1AppDataLocalTemp28dot3_removal_log @(GMT 2012-09-24 18-40-05).log”
- Now, move the role over to the next node to rinse & repeat
fsutil 8dot3name set 2
The registry state is now: 2 (Per volume setting – the default).
fsutil 8dot3name set f: 1
Successfully disabled 8dot3name generation on f:
fsutil 8dot3name query f:
The volume state is: 1 (8dot3 name creation is disabled).
The registry state is: 2 (Per volume setting – the default).
Based on the above two settings, 8dot3 name creation is disabled on f:
fsutil 8dot3name strip f:
Scanning registry…
Total affected registry keys: 0
Stripping 8dot3 names…
Total files and directories scanned: 6
Total 8dot3 names found: 0
Total 8dot3 names stripped: 0
For details on the operations performed please see the log:
“C:UsersUSER~1AppDataLocalTemp38dot3_removal_log @(GMT 2012-09-24 18-44-36).log”
I know this now because I hit the wall on this one and Claus Joergensen at Microsoft turned me to the solution. He actually blogged about this as well, but I never really registered this until today.
Disable 8.3 name generation
SMB Transparent Failover does not support cluster disks with 8.3 name generation enabled. In Windows Server 2012 8.3 name generation is disabled by default on any data volumes created. However, if you import volumes created on down-level versions of Windows or by accident create the volume with 8.3 name generation enabled, SMB Transparent Failover will not work. An event will be logged in (Applications and Services Log – Microsoft – Windows – ResumeKeyFilter – Operational) notifying that it failed to attach to the volume because 8.3 name generation is enabled.
You can use fsutil to query and setting the state of 8.3 name generation system-wide and on individual volumes. You can also use fsutil to remove previously generated short names from a volume.
There’s also a little note here http://support.microsoft.com/kb/2709568
SMB Transparent Failover
Both the SMB client and SMB server must support SMB 3.0 to take advantage of the SMB Transparent Failover functionality.
SMB 1.0- and SMB 2.x-capable clients will be able to connect to, and access, shares that are configured to use the Continuously Available property. However, SMB 1.0 and SMB 2.x clients will not benefit from the SMB Transparent Failover feature. If the currently accessed cluster node becomes unavailable, or if the administrator makes administrative changes to the clustered file server, the SMB 1.0 or SMB 2.x client will lose the active SMB session and any open handles to the clustered file server. The user or application on the SMB client computer must take corrective action to reestablish connectivity to the clustered file share.
Note SMB Transparent Failover is incompatible with volumes enabled for short file name (8.3 file name) support or with compressed files (such as NTFS-compressed files).
Frankly, all my testing of Continuous available share, from the BUILD conference till RTM setups have been green field, meaning squeaky clean, brand new LUNs. So this time, in real live with a LUN that has a history in a Windows 2008 R2 environment I got bitten.
So, read, read and than read some more  is my advise and be grateful for the help of patient and knowledgeable people.
is my advise and be grateful for the help of patient and knowledgeable people.
Anyway, It’s full steam ahead here once again getting the most out of our Software Assurance by leveraging everything we can out of Windows Server 2012.





