Introduction
In this post, I will be discussing an issue we ran into when leveraging the instant recovery capability of Veeam Backup & Replication (VBR). The issue became apparent when we set up the preferred networks in VBR. The backup jobs and the standard restores both leveraged the preferred network as expected. We ran into an issue with instant recovery. While the mount phase leverages the preferred network this is not the case during the restore phase. That uses the default host management network. To make Veeam instant recovery use a preferred network we had to do some investigation and tweaking. This is what this blog post is all about.
Overview
We have a Hyper-V cluster, shared storage (FC), that acts as our source. We back up to a Scale Out Backup Repository that exists of several extend or standard repository. Next to the management network, all of the target and source nodes have connectivity to one or more 10/25Gbps networks. This is leveraged for CSV, live migrations, storage replication, etc. but also for the backup traffic via the Veeam Backup & Replication preferred network settings.
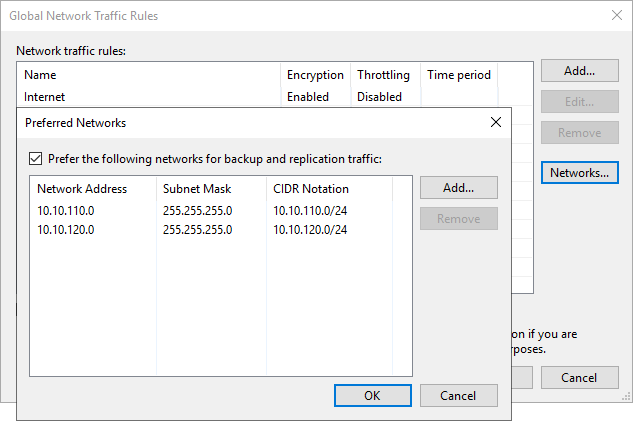
The IPs for the preferred networks are NOT registered in DNS. Note that the Veeam Backup & Replication server also has connectivity to the preferred networks. The reason for this is described in Optimize the Veeam preferred networks backup initialization speed.
As you might have guessed from the blog post title “Make Veeam Instant Recovery use a preferred network” this all worked pretty much as expected for the backup themselves and standard restores. But when it came to Instant Recovery we noticed that while the mount phase leveraged the preferred network, the actual restore phase did not.
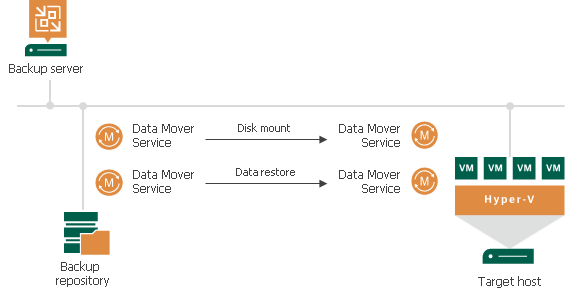
To read up on instant recovery go to Instant VM Recovery. But in this blog post, it is time to dive into the log files to figure out what is going on?
To solve the issue we dive into the VBR logs, but also into the logs on both the repository/extent and the Hyper-V server where we restore the VM to. The logs confirmed what we already noticed. For backups and normal restores, it correctly decides to use the preferred network. With instant recovery for some reason, in the restore phase, it selects the default host network which is 1Gbps.
Investigating the logs
Reading logs can seem an intimidating tedious task. The trick is to search for relevant entries and that is something you learn by doing. Combine that with an understanding of the problem and some common sense and you can quickly find what you need to look for. Than it is key to figure out why this could be happening. Sometimes that doesn’t work out. In that case, you contact Veeam support. That’s what I did as I knew well what the issue was and I could see this reflected in the logs. But I did not know how to handle this one.
We will look at the logs on the VBR Server, the repository where the backup files of the VM live, and the Hyper-V node where we restore the VM to investigate this issue.
The VBR log
Let’s look at the restore log of the virtual machine for which we perform instant recovery on the VBR server. We notice the following.

The repository logs
These are the logs of our repository or extent where the restore reads the backup data from. There are actually 2 logs. One is the mount log and the other is the restore log.
We first dive into the Agent.IR.DidierTest08.Mount.Backup-Side.log of our test VM instant recovery. Here we can see connections to our Hyper-V server node where instant recover the test VM over the preferred network. Note that is is the Hyper-V server node that acts as the client!

Let ‘s now parse the Agent.IR.DidierTest08.Restore.Backup-.Side.log of our test VM instant recovery. No matter how hard we look we cannot find any connection attempt, let alone a connection to a preferred network (10.10.110.0/24). We do see the restore work over the default management network (10.18.0.0/16). Also note here that it is the repository node that connects to the Hyper-V node (10.18.230.5), it acts as a client now.

The restore target log
This is the Hyper-V server to where we restore the virtual machine. There are multiple logs but we are most interested in the mount log and the restore log.
We first dive into the Agent.IR.DidierTest08.Mount.HyperV-Side.log of our test VM instant recovery.The mount log shows what we already know. It also shows that it is the Hyper-V server that initiates the connection. This does leverage the preferred network (10.10.110.0/24).

It also shows the mount phase does leverage the preferred network (10.10.110.0/24).

But when we look at the restore phase log Agent.IR.DidierTest08.Restore.HyperV-Side.log we again see that the default host management network is used instead of the preferred network.

Again, we see that the Hyper-V server node during the restore phase acts as the server while the repository is the client (10.18.217.5).
Summary of our findings
Based on our observations on the servers (networks used) and investigating the logs we conclude the following. During an instant recovery, the VM is mounted on the Hyper-V host (where the checkpoint is taken). During the mount phase, the Hyper-V host acts as the client, while the repository acts as the client. This leverages the preferred network. Now, during the restore phase, the repository acts as the client and connects to the Hyper-V host that acts as the server. This does not leverage the preferred network.
This indicates that the solution might lie in reversing the client/server direction for the restore phase of Instant Recovery. But how? Well, there is a setting in Veeam where we can do just this.
Make Veeam Instant Recovery use a preferred network
I have to thank the Veeam support engineer that worked on this with me. He investigated the logs that I sent him as well but with more insight than I have. Those were clean logs just showing reproductions of the issue in combination with a Camtasia Video of it all. That way I showed him what was happening and what I saw while he also had the matching logs to what he was looking at.
Sure enough, he came back with a fix or workaround if you like. To make sure instant recovery leverages the preferred network we needed to do the following. On each extent, in properties, under credentials go to network settings and check “Run server on this side” under “Preferred TCP connection role”.
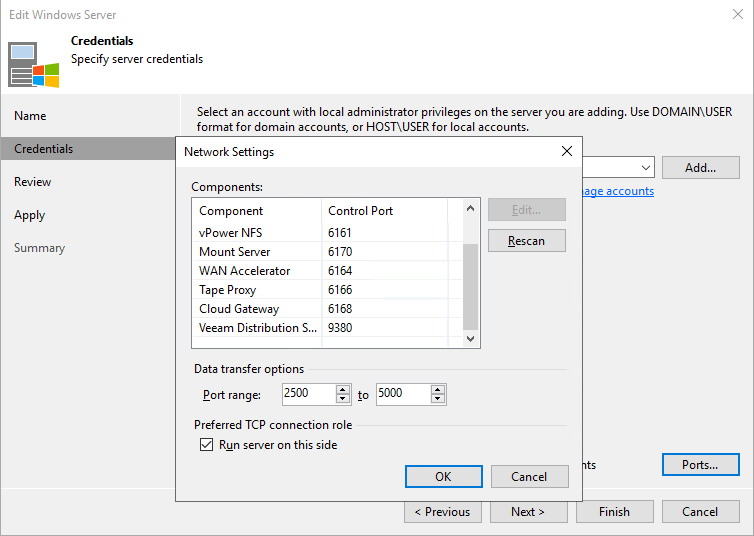
The “normal” use cases are for example when most the repository FQDN resolves into several IP addresses and Hyper-V FQDN is resolved into 1 only. This was not the case in our setup, the preferred networks are not registered in DNS. But here leveraging the capability to set “Run server on this side” solves our issue as well.
Parse the logs with “Run server on this side” enabled on the repository/extents
When we start a clean test and rerun an Instant Recovery of our test VM we now see that the restore phase does leverage the preferred network. The “Run server on this side” setting is also reflected in the restore phase logs on both the repository and the backup server.


In the VBR log itself, we notice the “Run server on this side” has indeed been enabled.
Host ‘REPOSITORYSERVER’ should be server, reversing connection
IR.DidierTest08.Mount.log
In the Agent.IR.DidierTest08.Restore.Backup-Side.log on the repository server, we also see this setting reflected.

Based on the documentation about “Run server on this side” in https://helpcenter.veeam.com/docs/backup/hyperv/hv_server_credentials.html?ver=95u4 you would assume this is only needed in scenarios where NAT is in play. But this doesn’t cover all use cases. Enabling this checkbox on a server means it does not initiate the connection but waits for the incoming connection from its partner. In our case that also causes the preferred network to be picked up. Apparently, all that is needed is to make sure the Hyper-V hosts to where we restore act as the client and initializes the connection to the server, our repository or extents in SOBR.
Conclusion
We achieved a successful result. Our instant recoveries now also leverage the preferred network. In this use case, this is really important as multiple concurrent instant recoveries are part of the recovery plan. That’s why we have performant storage solutions for our backup and source in combination with high bandwidth on a capable network. In the end, it all worked out well with a minor tweak to make Veeam Instant Recovery use a preferred network. This was however unexpected. I hope that Veeam dives into this issue and sees if the logic can be improved in future updates to make this tweak unnecessary. If I ever hear any feedback on this I will let you know.