Active Directory Replication Status Tool’s rise, fall, and rebirth
For many years the Active Directory Replication Status Tool has been a trusty companion for many IT Pro. That includes seasoned systems engineers as well as accidental Active Directory administrators. It was an easy way to get a quick and good idea of the replication health of your Active Directory forest or domain.
Sure, repladm is our friend and keeps doing its job with us in the trenches. But I would say that the Active Directory Replication Status Tool is a lot less scary for people. Especially those who incidentally need to find out what issues to address where. It is a non-scarry, kind wrapper to visualize the results and see where we need to pay attention.
It had some quirks, like the ridiculous need to download it again when the license (certificate) expired (I never liked the Sirona DLL hack in a production environment). If other issues arose, I blogged on how to work around them, like in Microsoft Active Directory Replication Status Tool won’t upgrade – Working Hard In ITWorking Hard In IT. But that was minor compared to the sage of the last 18 months. Let’s quickly look at the Active Directory Replication Status Tool’s rise, fall, and rebirth.
The fall
Once in a while, an update to Windows or .NET broke the application. Normally, a fix would follow soon, and everyone was happy again. Last year in the spring or early summer of 2022, the tool was broken for months. Finally, somewhere in August 2022, we got a new version that worked, as far as my experience goes, for about 4 to 6 weeks, It then broke again, and all it ever did after was crash. The cert also expired again but who cared? It was no longer functional anyway,
Well, I cared, and I gave a lot of feedback via Twitter and to Microsoft via e-mail.
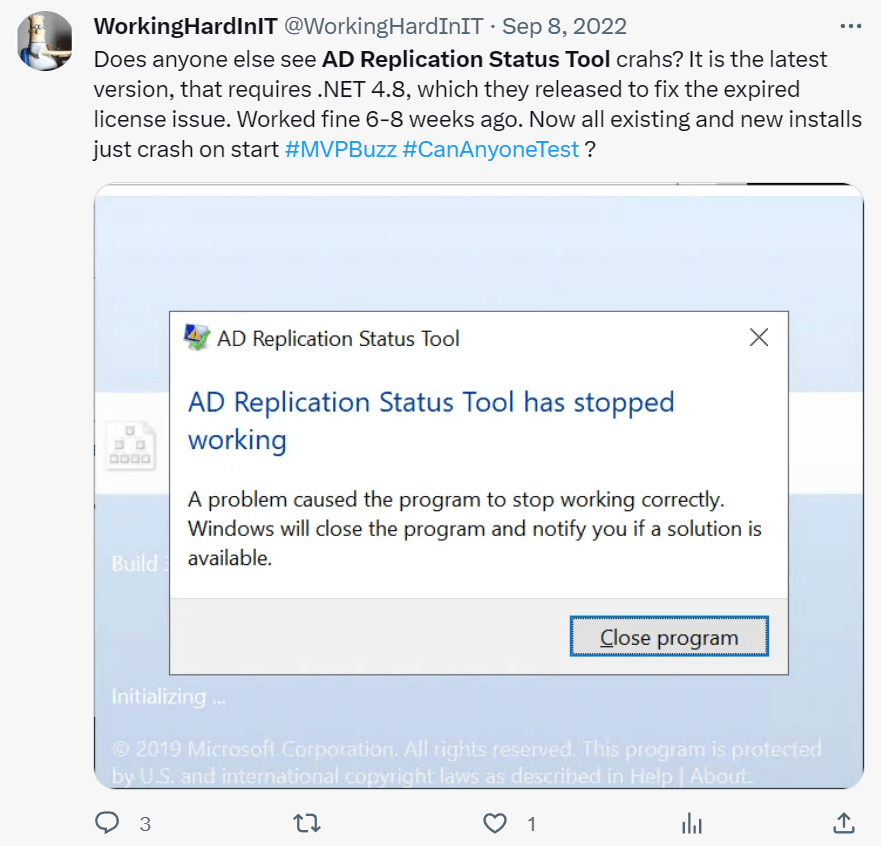
That went on for about 10 months without any progress! Then suddenly, I notice this: How to get and use the Active Directory Replication Status Tool – Windows Server | Microsoft Learn.

What!!??? Is this how it ends? Abandoned in a ditch somewhere?
Important
As of June 2nd, 2023, the Active Directory Replication Status Tool is no longer available for download. The following article is provided for historical purposes only.
Are you kidding me? There went another e-mail right to Redmond! Was this the sad end? I got a reply that not all was lost with a link.
The rebirth
The link I got is this one GitHub – ryanries/ADReplStatus: AD Replication Status Tool. People meet Ryan Ries, an Escalation Engineer at Microsoft who has some very useful and handy private projects to share with the world. ADReplStatus is one of the more recent ones.
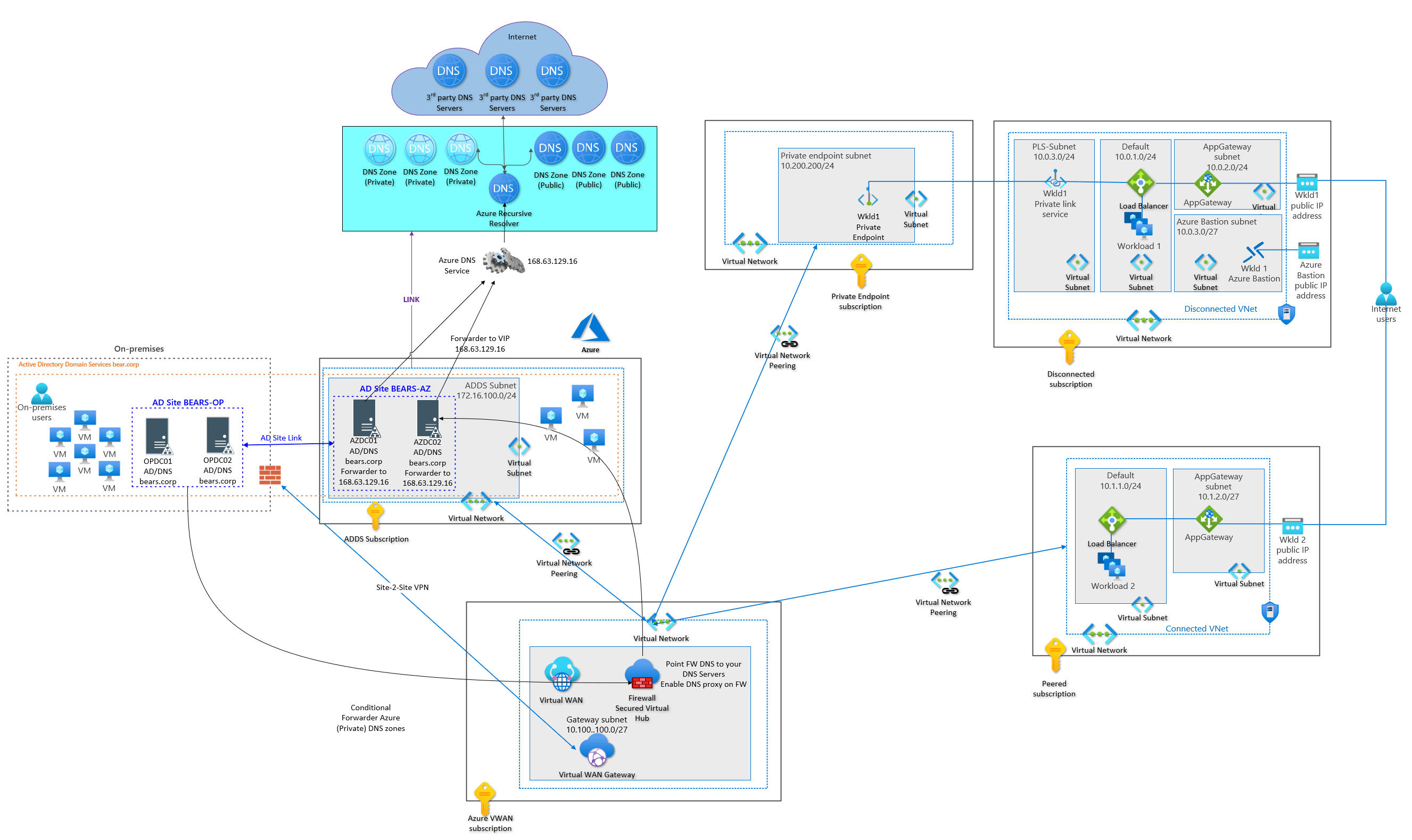
I downloaded it and started testing it in the lab. That went well and has already found its way to two production environments. Here is a screenshot from my lab environment!
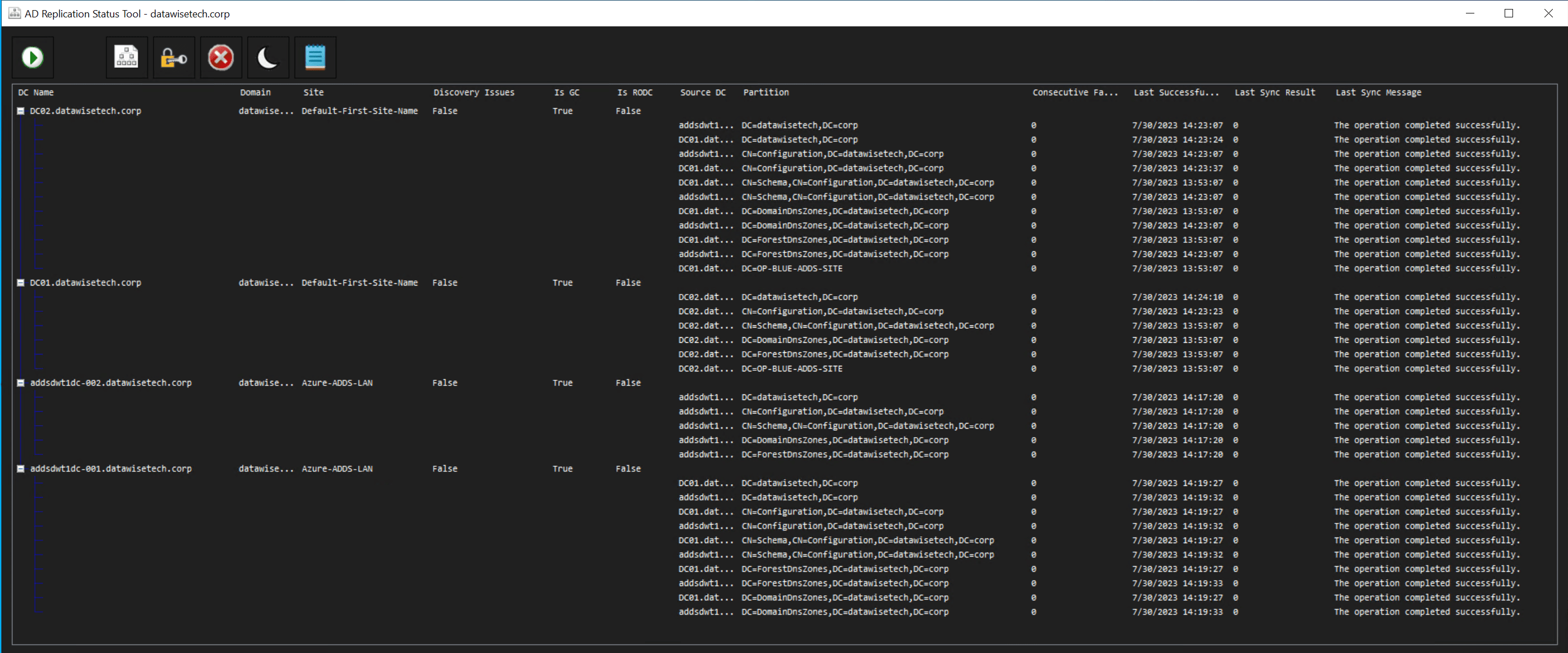
Thank you, Ryan Ries, for helping your customers in your free time with your private projects. You have made my IT Pro existence a bit easier again instead of more difficult. It is appreciated! Thank you, Ned Pyle, for bringing this GitHub repo to my attention. Download your copy here Release v1.3.1 · ryanries/ADReplStatus · GitHub.
What I did find interesting was that the cert expiration time bomb was also an internal issue. That and the fact that the application had no maintainers. But that was obvious to us all.
The old version of the tool had a time bomb in it – an expiring SSL certificate – that rendered the app unusable sometime around September 2022. Only through great effort internally were we able to periodically renew this certificate and republish the app, and the app was architected in such a way that excising the signing certificate check was more work than just rewriting the whole thing. (I know about the Sirona DLL hack, but still.)
The old tool had no active maintainers and no one who was still around was familiar with the app’s internals or source code.
Things are tough all over, it seems.