Introduction
In a previous blog post Veeam Backup & Replication leverages SMB Multichannel post we showed that Veeam backup & Replication leverages SMB multichannel when possible.
But what about Veeam Backup & Replication Preferred Subnet & SMB Multichannel, does that work? We mentioned that we wanted to answer the question what happens if we configure a preferred back-up network in Veeam Backup & Replication. Would this affect the operation of SMB multichannel at all? By that I means, would enabling a preferred network in Veeam prevent multichannel from using more than one NIC?
In this blog post we dive in to that question and some scenarios. We actually need to be able to deal with multiple scenarios. When you have equally capable NICs that are on different subnets you might want to make sure it uses only one. Likewise, you want both to be used whether they are or are not on the same subnet even if you set a preferred subnet in Veeam. The good news is that the nature of SMB Multichannel and how Veaam preferred networks work do allow for flexibility to achieve this. But it might not work like you would expect, unless you understand SMB Multichannel.
Veeam Backup & Replication Preferred Subnet & SMB Multichannel
For this blog post we adapt our lab networking a bit so that our non-management 10Gbps rNICs are on different subnets. We have subnet 10.10.110.0/24 for one set of NICs and 10.10.120.0/24 for the second set of NICs. This is shown in the figure below.

These networks can live in a separate VLAN or not, that doesn’t really matter. It does matter if to have a tagged VLAN or VLANS if you want to use RDMA because you need it to have the priority set.
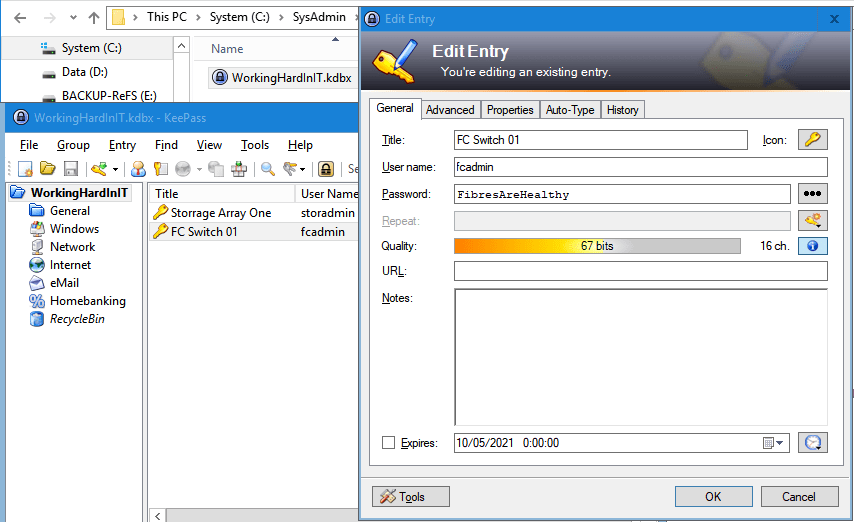
We now need to configure our preferred network in Veeam Backup & Replication. We go to the main menu and select Network Traffic Rules

In the Global Network Traffic Rules window, click Networks.

In the Preferred Networks window, select the Prefer the following networks for backup and replication traffic check box.

Click Add. We use the CIDR notation to fill out our preferred network or you can use the network mask and click OK.
To prove a point in regards to how Multichannel works isn’t affected by what you fill out here we add only one of our two subnets here. SMB will see where it can leverage SMB multichannel and it will kick in. Veeam isn’t blocking any of its logic.
So now we kick of a backup of our Hyper-V host to our SMB hare target backup repository. We can see multichannel work just fine.

Below is a screenshot on the backup target of the backup running over SMB multichannel, leveraging 2 subnets, while having set only one of those as the preferred network in Veeam Backup & Replication

Look at my backup fly … and this is only one host that’s being backup (4 VMs actually). Have I told you how much I love flash storage? And why I’m so interested in getting ReFS hybrid volumes with SSD/SATA disks to work as backup target? I bet you do!
Looking good and it’s easy, right? Well not so fast!
Veeam does not control SMB Multichannel
Before you think you’re golden here and in control via Veeam lets do another demo. In the preferred network, we enter a subnet available to both the source and the target server but that is an LBFO (teamed) NIC with to 1Gbps members (RSS is enabled).

No let’s see what happens when we kick of a backup.

Well SMB multichannel just goes through its rules and decided to take the two best, equally capable NICs. These are still our two 10Gbps rNICs. Whatever you put in the preferred network is ignored.
This is neither good or bad but you need to be aware of this in order to arrange for backups to leverage the network path(s) you had in mind. This is to avoid surprises. The way to do that the same as you plan and design for all SMB multichannel traffic.
As stated in the previous blog post you can control what NICs SMB multichannel will use by designing around the NIC capabilities or if needed disabling or enabling some of these or by disabling SMB multichannel on a NIC. This isn’t always possible or can lead to issues for other workloads so the easiest way to go is using SMB Multichannel Constraints. Do note however that you need to take into consideration what other workloads on your server leverage SMB Multichannel when you go that route to avoid possible issues.
As an example, I disabled multichannel on my hosts. Awful idea but it’s to prove point. And still with our 10.10.0.0/16 subnet set as preferred subnet I ran a backup again.

As you can see the 2*1Gbps LBFO NIC is doing all the lifting on both hosts as it’s switch independent and not LACP load balancing mode we’re limited to 1Gbps.
So how do we control the NICs used with SMB multichannel?
Well SMB Multichannel rules apply. You use your physical design, the capabilities of the NICs and SMB constraints. In reality you’re better off using your design and if needed SMB multichannel constraints to limit SMB to the NICs you want it to use. Do not that disabling SMB Multichannel (client and or server) is a global for the host. Consider this as it affects all NICs on the host, not just the ones you have in mind for your backups. In most cases these NICs will be the same. Messing around with disabling multichannel or NIC capabilities (RSS, RDMA) isn’t a great solution. But it’s good to know the options and behavior.
Some things to note
Realize you don’t even have to set both subnets in the preferred subnets if they are different. SMB kicks of over one, sees it can leverage both and just does so. The only thing you manipulated here SMB multichannel wise is which subnet is used first.
If both of our rNICs would have been on the same subnet you would not even have manipulated this.
Another thing that’s worth pointing out that this doesn’t require your Veeam Backup & Replication VM to have an IP address in any of the SMB multichannel subnets. So as long as the source Hyper-V hosts and the backup target are connected you’re good to go.
Last but not least, and already mentioned in the previous blog post, this also leverages RDMA capabilities when available to help you get the best throughput, lowest latency and leave those CPU cycles for other needs. Scalability baby! No I realize that you might think that the CPU offload benefit is not a huge deal on your Hyper-V host but consider the backup target being hammered by several simultaneous backups. And also consider that some people their virtual machines look like below in regards to CPU usage, in ever more need of more vCPU and CPU time slices.

And that’s what the Hyper-V host looks like during a backup without SMB Direct (with idle VMs mind you).

All I’m saying here is don’t dismiss RDMA too fast, everything you can leverage to help out and that is available for free in the box is worth considering.
Note: I have gotten the feedback that Veeam doesn’t support SMB Direct and that this was confirmed by Veeam Support. Well, Veeam Backup & Replication leverages SMB 3 but that’s an OS feature. Veeam Backup & Replication will work with SMB Multichannel, Direct, Signing, Transparent Failover … It’s out of the Veeam Backup & Replication scope of responsibilities as we have seen here. You feel free to leverage SMB Direct whether that is using iWarp/Roce or Infiniband. This information was confirmed by Veeam and bears the “Anton Gostev seal of approval”. So if SMB Direct cause issues you have a configuration problem with that feature, it’s not Veeam not being able to support it, it doesn’t know or care actually.
Conclusion
The elegance and simplicity of the Veeam Backup & Replication GUI are deceiving. Veeam is extremely powerful and is surprisingly flexible in how you can leverage and configure it. I hope both my previous blog post and this one have given you some food for thought and ideas. There’s more Veeam goodness to come in the coming months when times allows. Many years ago, when SMB 3 was introduced I demonstrated the high availability capabilities this offered for Veeam backups. I’ll be writing about that in another blog post.