
IIS 6.0 SMTP Service in-place upgrade to Windows Server 2022
This will be a “notes from the field” type of blog post where I will guide you to successfully execute an IIS 6.0 SMTP Service in-place upgrade to Windows Server 2022. In this case, the original operating system version is Windows Server 2019. However, these notes can be used for upgrades between other Windows Server versions as well.
Yes, there are still valid reasons to run an SMTP relay service today. I use SendGrid as a smart host with these and I actually have these setup behind a KEMP LoadMaster for High Availability.
What could go wrong?
What could go wrong? Well, nothing unless you didn’t plan certain things in advance. Below are the issues you will face. and need to prepare for and fix in order to perform an IIS 6.0 SMTP Service in-place upgrade to Windows Server 2022
- The IIS 6 Management Console will be missing
For some reason that gets dropped during the in-place upgrade. The fix is to reinstall it. Easy enough.
- Your SMTP Virtual services configuration will be wiped out during an in-place upgrade.
Yes, it will be a very empty console. Which is a scary experience if you did not prepare for it.
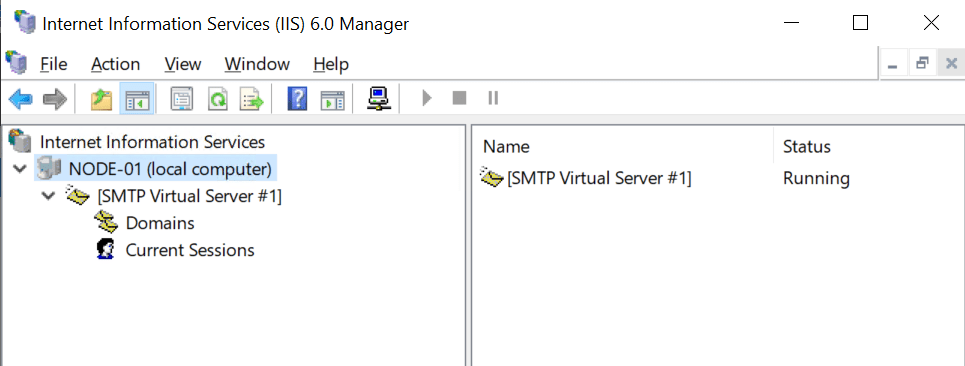
The trick is to create a backup and restore it. That way you get your configuration back. So, first of all, create a backup of your IIS configuration. We will go over this later. Secondly, before you can restore your backup you need to reinstall the IIS 6 Management Console as stated above. When you have restored the backup reboot the server, but before you do reconfigure the Simple Mail Transport Protocol service to start automatically.
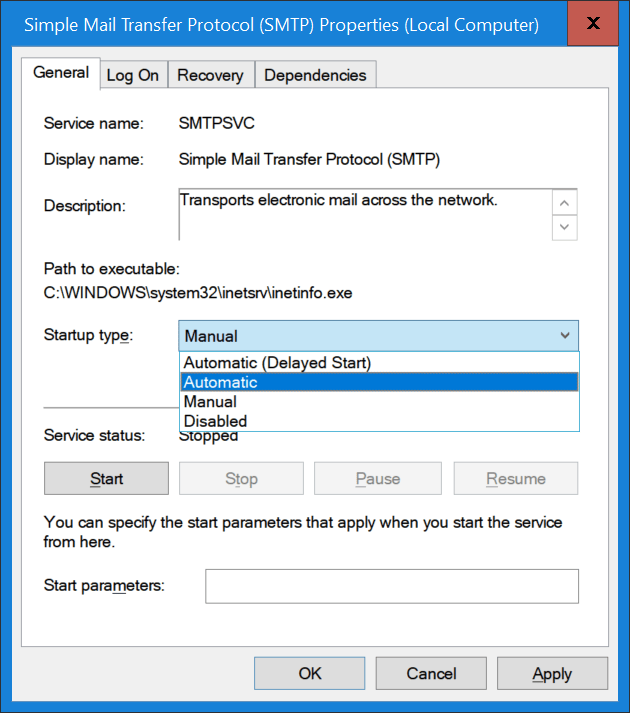
- Simple Mail Transport Protocol Service
The Simple Mail Transport Protocol Service will be set to reset to its default, which is to start manually start instead of automatically. This one is easily fixed but you need to remember to do so as your SMTP Virtual Servers will not be running after a restart. And as you keep your servers patched that will be at least once a month probably.
Step-by-step
- Backup the current configuration
The easiest way to do this is via appcmd. Open an elevated command prompt and navigate to C:\Windows\System32\inetsrv. Run the following command.
appcmd add backup MYBACKUPNAME

The backup is stored under C:\Windows\System32\inetsrv\Backups\MYBACKUPNAME. Verify it is there, it should contain the following files:
- administration.config
- applicationHost.config
- MBSchema.xml
- MetaBase.xml
- redirection.config
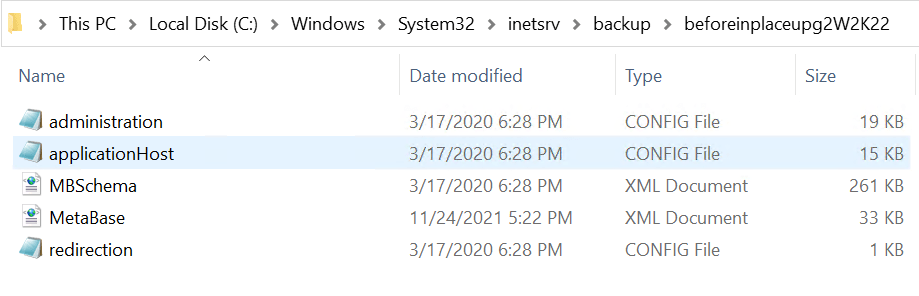
This folder is preserved during the upgrade but you can always grab a copy to be on the safe side.
- Perform the in-place upgrade
This is the normal process, nothing special about it unless you run into trouble, which is not very likely in well-maintained environments.
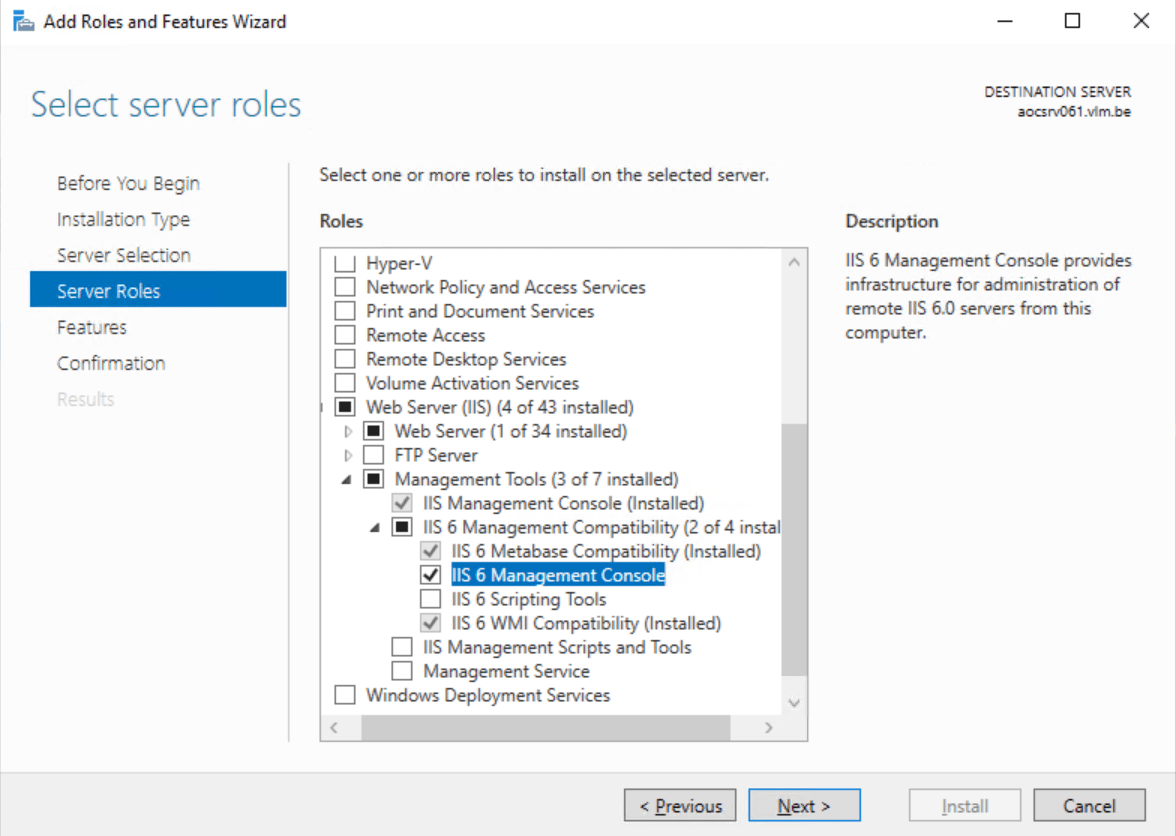
- Reinstall the IIS 6 Management console
This is easily done via the Add Roles and Features Wizard and does not require a reboot.
- Set the Simple Mail Transport Protocol service to start automatically
- Restore your IIS backup
Open an elevated command prompt and navigate to C:\Windows\System32\inetsrv. Run the following command.
appcmd restore backup MYBACKUPNAME

- Restart the server
When you have restarted the server open the IIS 6 Management console. Your SMTP virtual Services should be backup up and running.
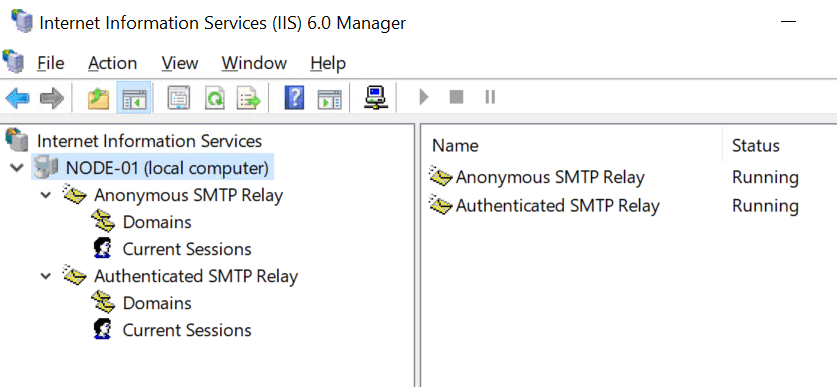
Test your SMTP functionality via a PowerShell script for example to verify all is well.
Conclusion
In-place upgrades work quite well but certain roles and configurations have their quirks and issues to solve. Some lab work to test scenarios and their outcome is helpful when preparing an in-place upgrade.
This is the case for IIS 6.0 based SMTP Service role. We have shown you how to work around this and successfully perform an IIS 6.0 SMTP Service in-place upgrade to Windows Server 2022. The thing is, this is not related to Windows Server 2022, it is an IIS 6.0 issue.
With virtual machines leverage the luxury of checkpoints for fast and easy recovery before you begin. Also, make sure you have a tested backup to restore. Always have options and avoid painting yourself into a corner.









