Without any doubt, I find the hardened Linux repository Veeam introduces in Veeam Backup & Replication v11 one of the most fascinating new features to get my hands on. In the ever-escalating battle with ransomware and wipers, this is a very valuable option to have in your defensive arsenal. So, I grabbed the Beta 2 and got to work in the lab over the holidays to investigate and find out some details about the Immutability of Linux files on the Veeam hardened Linux repository.
Immutability of Linux files on the Veeam hardened Linux repository
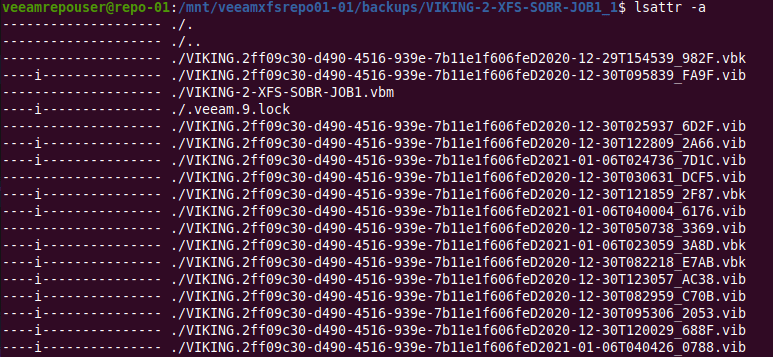
It’s quite easy to find the file attribute “i” that marks a file as immutable.
lsattr -a
lsattr -a also shows the hidden files
or
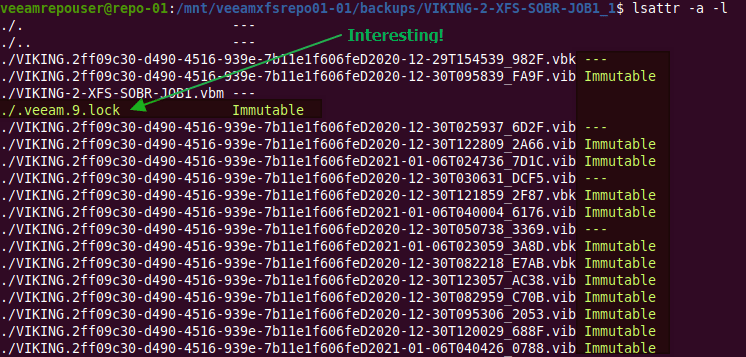
lsattr -a -l
lsattr -a -l list out the full name of the attribute.
Where is the information about the immutability actually stored? I mean, that “i” attribute is one thing but how do the Linux host and Veeam know from what time period this immutability is valid. In the end, the service has to clear it and know when to do this. Or is this only stored in the Veeam database or both?
How does it now from when till when a file must be immutable?
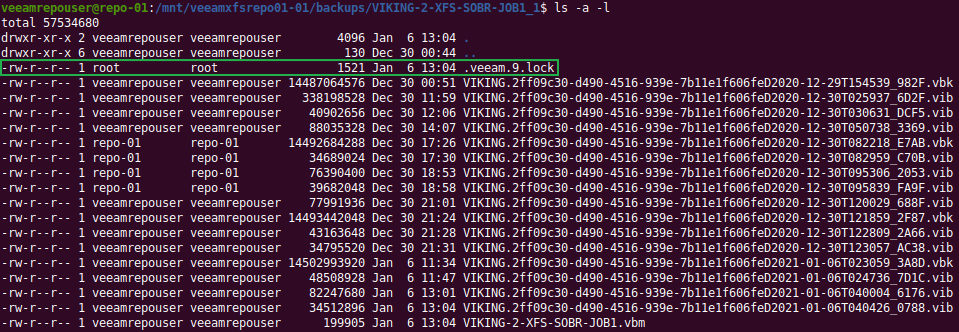
Digging around in the files and folders of the Veeam repository, I soon found the lock file “.veeam.x.lock” (see the green arrow in the image above) that is created by the veeamimmureposvc service. The owner is root, hence it is not created by the Veeam transport service. The veeamimmureposvc service is a local account with root access for managing the immutability. It only works locally and does not listen on any network port, hence it cannot be accessed remotely.
The veeamimmureposvc service controls the .veeam.x.lock file. the x is a number has increments with every backup job you run.
Let’s look inside to see if we can read something there?
cat .veeam.9.lock
the lock file is an XML file containing all the date/time stamps for every file in that backup job.
When you open that file you will find it to be an XML file. Inside you’ll see the date and time stamp for every file in the backup chains for that job. That’s cool.
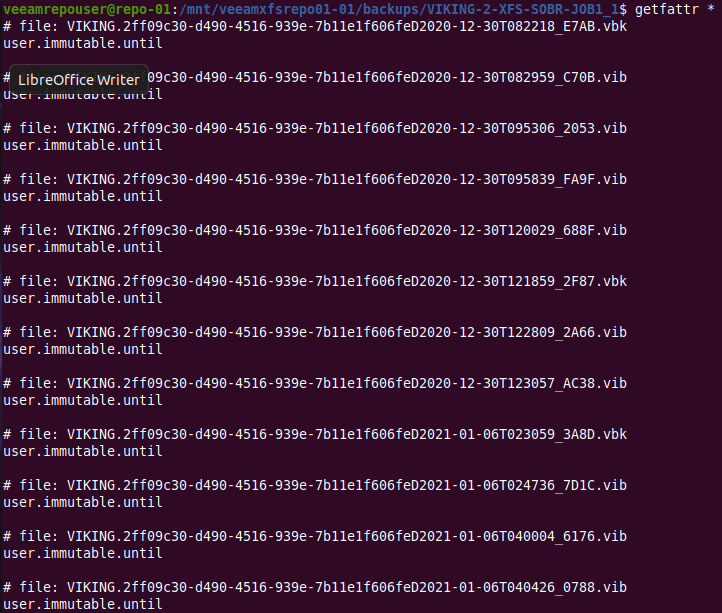
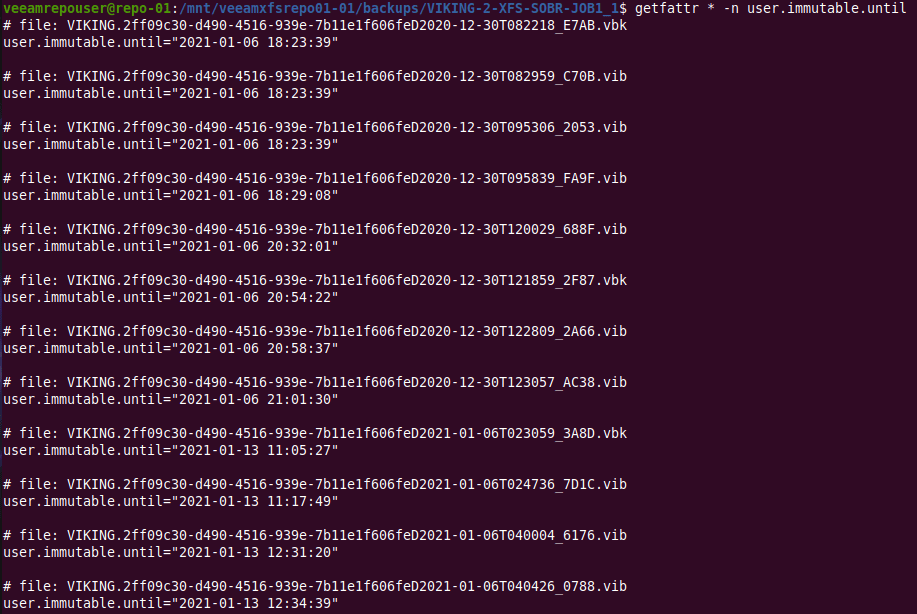
But there is more. When we run “getfattr *”to look for extend file attributes we find that every Veeam created file has a one called user.immutable.until.
The backup files all have an extended file attribute called user.immutable.until.
With that name, it is clear it can be of interest to us. If you look at what is in there, you’ll see it contains the date and time stamp for that file’s immutability period.
getfattr * -n user.immutable.until
The extended file attribute contains the timestamp until when that backup file is immutable!
That I find interesting. Veeam saves the information twice. Is that for redundancy or as some sort of checksum? Maybe it also has to do with the fact Veeam backup files are transportable and self-contained so that information is stored as an extended file attribute.
Conclusion
So there you have it. A small piece of information on where the immutability information is stored. The most surprising thing to me was that it is actual stored twice.
I hope you fund this interesting. Poking around to figure out the how and what of things always helps me tremendously to learn and understand the technologies I want to work with. That leads to better decisions in design and implementation. It leads to both trust and confidence, which helps me decide where and when to leverage it. Finally it also, almost without, it is invaluable when supporting the technology.
Since diving into the Veeam Backup & Replication v11 Linux hardened repository I have started to use XFS in bite-size deployments to gain experience with it. One of the things that will certainly come in handy is extending a Veeam Repository XFS File System. In this blog post, I show to do that.
Mind you that I am doing this with a virtual machine on Hyper-V (Windows Server 2019) in the lab. Not every permutation of hardware and storage controllers you can find. But still, the procedure here will not differ that much.
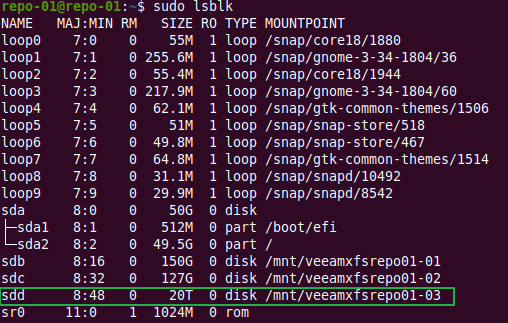
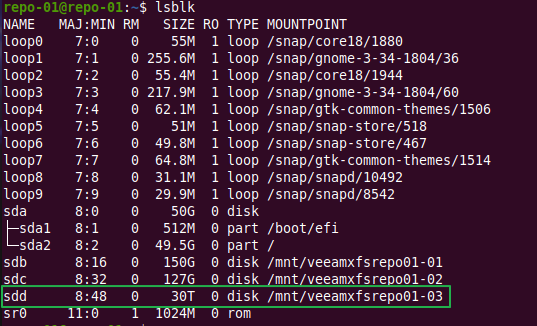
Determine the size of the current disk.
sudo slblk
Ours is the 20 TB disk, sdd, a SCSI disk.
Now take note of the bytes and sectors
sudo fdisk -l
We just notice the size, bytes and sectors to compare after we extended disk.
Expand the disk
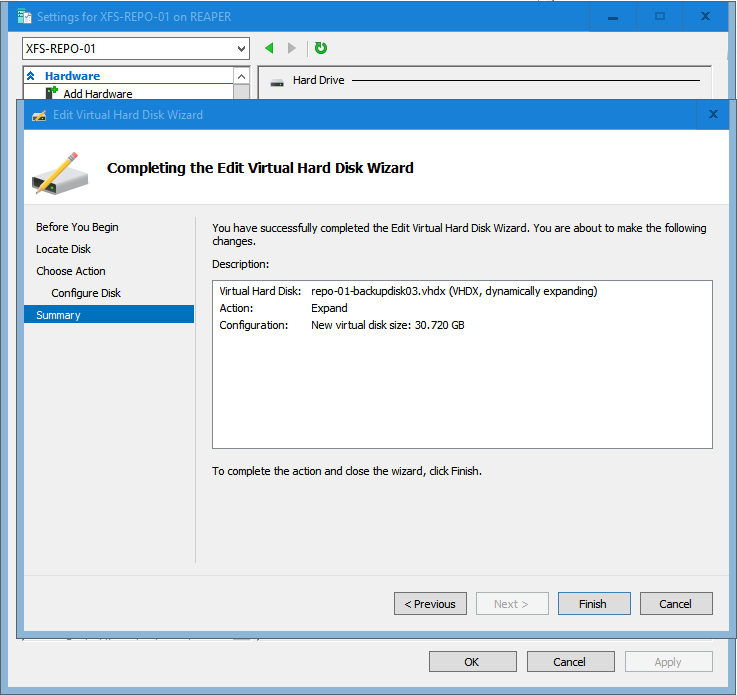
In the virtual machine settings I extend the virtual disk I want to grow with the required capacity.
Let’s add 20 TB and make it 30 TB in total.
In real life that might be you growing a raid controllers’ virtual disk by adding physical disks to the raid controller, you expanding the volume on the storage array or simply adding disks to the local server and adding them to the software-based raid solution you use.
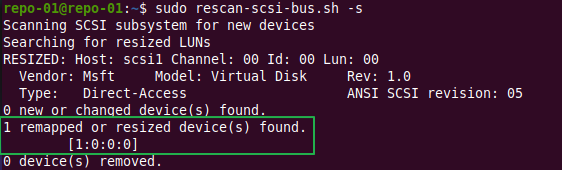
The virtual machine will pick up the extra capacity right away. For our UBUNTU 20.04.1 OS to see it up we’ll need to rescan the SCSI busses for change. In a virtual machine, this can be done via rescan-scsi-bus.sh, available scsitools that will need to be installed if not there.
Use the -s options as that will really show the resized disks.
Yup, that’s our disk on SCSI controller 1, location 0.
Now let’s check the disk size again
Yes, lsbsk shows 30 TB.fdisk -l confirms. Note the new bytes and sector values. It has gone up.
Extend the xfs volume to use the unallocated space
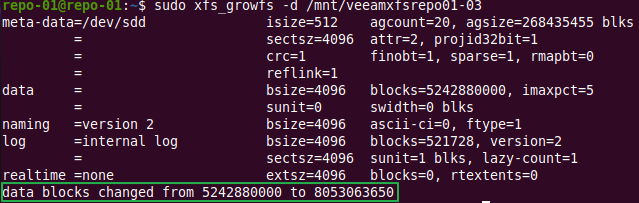
Now we need our xfs volume to use the unallocated capacity in this disk. We use -d as this will grow the file system to the largest possible size, 30 TB in our case.
Note: If you run the below command with -n instead of -d, this gives you the current information on your xfs volume with extending the filesystem yet.
Note: What I did find is that if you just expand the disk and than extend the xfs file system, it also works. It seems to just work without rescanning the disk after extending it! The disks size in df -h will show this space then as well.
Conclusion
That was it. Short and sweet. There is not much to it once you know how to do it. One thing to remember is that you cannot shrink an XFS file system. So, as always, start smaller and grow when needed. Always leave spare capacity to work with when needed. Yes, even in 2021 this is advice to live by in the storage world. For Veeam this means that multiple smaller repositories or extents give you more wiggle room than fewer very large ones. Leave capacity in reserve, either in a spare repository/extend or unallocated. This, especially combined with a scale-out backup repository in Veeam will allow you to work your self out of most capacity pickles you might find your self in.
In this blog post, I’ll look at how to set the Max Concurrent Tasks in Veeam with PowerShell. When configuring your Veeam backup environment for the best possible backup performance there are a lot of settings to tweak. The defaults do a good job to get you going fast and well. But when you have more resources it pays to optimize. One of the things to optimize is Max Concurrent Tasks.
NOTE: all PowerShell here was tested against VBR v10a
Where to set max concurrent tasks or task limits
There are actually 4 places (2 specific for Hyper-V) where you can set the this in Veeam for a Hyper-V environment.
Max Concurrent Tasks on an off-host proxyTask limit on the on-host Hyper-V proxyMax Concurrent tasks on a file proxy (V10)Limit maximum concurrent tasks on a repository or SOBR extent
Now, let’s dive into those a bit and show the PowerShell to get it configured.
Configuring the proxies
When configuring the on-host or off-host proxies, the max concurrent tasks are based on virtual disks. Let’s look at some examples. 4 virtual machines with a single virtual disk consume 4 concurrent tasks. A single virtual machine with 4 virtual disks also consumes 4 concurrent tasks. 2 virtual machines with 2 virtual disks each consumes, you guessed it, 4 concurrent tasks.
Note that it doesn’t matter if these VMs are in a single job or multiple jobs. The limits are set at the proxy level. So it is the sum of all virtual disks in the VMs of all concurrently running backup jobs. Once you hit the limit, as a result, the remainder of virtual disks (which might translate into complete VMs) will be pending.
set the max concurrent tasks for on-host proxies
#We grab the Hyper-V on-host backup proxies. Note this code does not grab
#any other type of proxies. We set the MaxTasksCount and report back
$MaxTaskCountValueToSet = 12
$HvProxies = [Veeam.Backup.Core.CHvProxy]::GetAll()
$HvProxies.Count
Foreach ($Proxy in $HvProxies) {
$HyperVOnHostProxy = $proxy.Host.Name
$MaxTaskCount = $proxy.MaxTasksCount
Write-Host "The on-host Hyper-V proxy $HyperVOnHostProxy has a concurrent task limit of $MaxTaskCount" -ForegroundColor Yellow
$options = $Proxy.Options
$options.MaxTasksCount = $MaxTaskCountValueToSet
$Proxy.SetOptions($options)
}
#Report the changes
$HvProxies = [Veeam.Backup.Core.CHvProxy]::GetAll()
Foreach ($Proxy in $HvProxies) {
$HyperVOnHostProxy = $proxy.Host.Name
$MaxTaskCount = $proxy.MaxTasksCount
Write-Host "The on-host Hyper-V proxy $HyperVOnHostProxy has a concurrent task limit of $MaxTaskCount" -ForegroundColor Green
}
set THE MAX CONCURRENT TASKS for off-host proxies
#We grab the Hyper-V off-host backup proxies. Note this code does not grab
#any other type of proxies. We set the MaxTasksCount and report back
$MaxTaskCountValueToSet = 6
$HvOffHostProxies = Get-VBRHvProxy
foreach ($OffhostProxy in $HvOffHostProxies) {
$HvOffHostProxyName = $OffhostProxy.Name
$MaxTaskCount = $OffhostProxy.MaxTasksCount
Write-Host "The on-host Hyper-V proxy $HvOffHostProxyName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Yellow
$Options = $OffhostProxy.Options
$Options.MaxTasksCount = $MaxTaskCountValueToSet
$OffhostProxy.SetOptions($Options)
}
#Report the changes
foreach ($OffhostProxy in $HvOffHostProxies) {
$HvOffHostProxyName = $OffhostProxy.Name
$MaxTaskCount = $OffhostProxy.MaxTasksCount
Write-Host "The on-host Hyper-V proxy $HvOffHostProxyName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Green
}
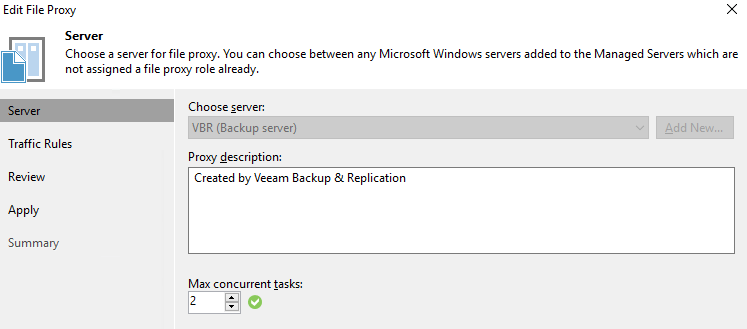
PowerShell code to set THE MAX CONCURRENT TASKS for file proxies
#We grab the file proxies. Note this code does not grab
#any other type of proxies. We set the MaxTasksCount and report back
$MaxTaskCountValueToSet = 12
$FileProxies = [Veeam.Backup.Core.CFileProxy]::GetAll()
Foreach ($FileProxy in $FileProxies) {
$FileProxyName = $FileProxy.Name
$MaxTaskCount = $FileProxy.MaxTasksCount
Write-Host "The file proxy $FileProxyName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Yellow
$options = $FileProxy.Options
$options.MaxTasksCount = $MaxTaskCountValueToSet
$FileProxy.SetOptions($options)
}
#Report the changes
$FileProxies = [Veeam.Backup.Core.CFileProxy]::GetAll()
Foreach ($FileProxy in $FileProxies) {
$FileProxyName = $FileProxy.Name
$MaxTaskCount = $FileProxy.MaxTaskCount
Write-Host "The file proxy $FileProxyName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Green
}
Last but not least, note that VBR v10 PowerShell also has the Get-VBRNASProxyServer and Set-VBRNASProxyServer commands to work with. However, initially, it seemed not to be reporting the name of the proxies which is annoying. But after asking around I learned it can be found as a property of the Server object it returns. While I was expecting $FileProxy. to exist (based on other Veeam proxy commands) I need to use Name$FileProxy.Server.Name
$MaxTaskCountValueToSet = 4
$FileProxies = Get-VBRNASProxyServer
foreach ($FileProxy in $FileProxies) {
$FileProxyName = $FileProxy.Server.Name
$MaxTaskCount = $FileProxy.ConcurrentTaskNumber
Write-Host "The file proxy $FileProxyName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Yellow
Set-VBRNASProxyServer -ProxyServer $FileProxy -ConcurrentTaskNumber $MaxTaskCountValueToSet
}
#Report the changes
$FileProxies = Get-VBRNASProxyServer
foreach ($FileProxy in $FileProxies) {
$FileProxyName = $FileProxy.Server.Name
$MaxTaskCount = $FileProxy.ConcurrentTaskNumber
Write-Host "The file proxy $FileProxyName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Green
}
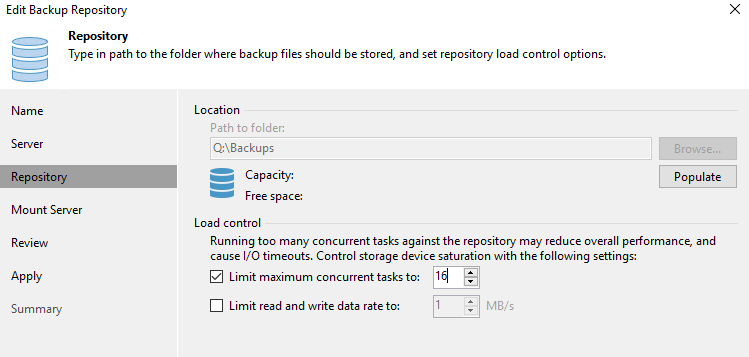
Configuring the repositories/SOBR extents
First of all, for Backup Repositories, the max concurrent tasks are not based on virtual disks but on backup files (.vbk, .vib & .vrb).
Secondly, you can use either per VM backup files or non-per VM backup files. In the per VM backup files every VM in the job will have its own backup file. So this consumes more concurrent talks in a single job than the non-per VM backup files mode where a single job will have a single file. Let’s again look at some examples to help clarify this. A single backup job in non-per VM mode will use a single backup file and as such one concurrent task regardless of the number of VMs in the job. A single backup job using per VM backup mode will use a single backup file per VM in the job.
What you need to consider with repositories is that synthetic tasks (merges, transformations, synthetic fulls) also consume tasks and count towards the concurrent task limit on a repository/etxent. So when setting it, don’t think is only related to running active backups.
Finally, when you combine roles, please beware the same resources (cores, memory) will have to be used towards those task limits. That also means you have to consider other subsystems like the storage. If that can’t keep up, your performance will suffer.
PowerShell code to set the task limit for a repository/extent
For a standard backup repositories this will do the job
I you put the output of Get-VBRBackupRepository in a foreach next you can also configuret/report on individual Backup repositories when requiered.
#We grab the repositories. Note: use -autoscale if you need to grab SOBR extents.
#We set the MaxTasksCount and report back
$MaxTaskCountValueToSet = 6
$Repositories = Get-VBRBackupRepository
foreach ($Repository in $Repositories) {
$RepositoryName = $Repository.Name
$MaxTaskCount = $Repository.Options.MaxTaskCount
Write-Host "The on-host Hyper-V proxy $RepositoryName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Yellow
Set-VBRBackupRepository -Repository $Repository -LimitConcurrentJobs -MaxConcurrentJob $MaxTaskCountValueToSet
}
#Report the changes
$Repositories = Get-VBRBackupRepository
foreach ($Repository in $Repositories) {
$RepositoryName = $Repository.Name
$MaxTaskCount = $Repository.Options.MaxTaskCount
Write-Host "The on-host Hyper-V proxy $RepositoryName has a concurrent task limit of $MaxTaskCount" -ForegroundColor Green
}
Conclusion
So I have shown you ways to automate. Similar settings for different purposes. The way off automating differs a bit depending on the type of proxy or if it is a repository. I hope it helps some of you out there.
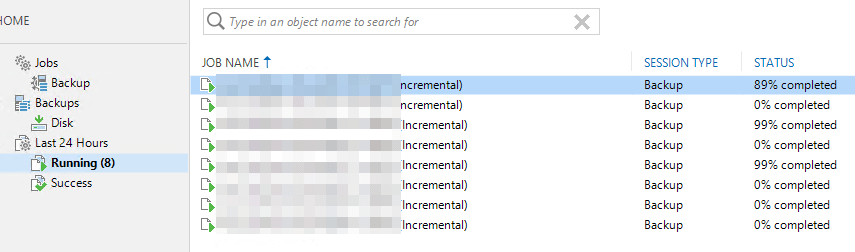
Recently I got to diagnose a really interesting Veeam Backup & Replication symptom. Imagine you have a backup environment that runs smoothly. All week long but then, suddenly, running backup jobs stall. News jobs that start do not make an ounce of progress. It is as the state of every job is frozen in time. Let’s investigate and dive into troubleshooting 100% stalled Veeam backup jobs.
That morning, the backup jobs had not made an ounce of progress since the night before and they never will, you can leave this for days sometimes a job in between does seem to work properly, but most often not so the job queue builds up.
Troubleshooting 100% stalled Veeam backup jobs
When looking at the stalled jobs, nothing in the Veeam GUI indicates an error. Looking at the Windows event logs we see no warning, error, or critical messages. All seems fine. As this Veeam environment uses ReFS on storage spaces we are a bit weary. While the bugs that caused slowdowns have been fixed, we are still alert to potential issues. The difference with the know (fixed) ReFS issues that this is no slowdown, No sir, the Veeam backup jobs have literally frozen in time but everything seems to be functional otherwise.
Another symptom of this issue is that the synthetic full backups complete perfectly well, but they finfish with an error message none the less due to a time out. This has no effect on the synthetic backup result (they are usable) but it is disconcerting to see an issue with this.
On top of that, data copies into the ReFS volumes work just fine and at an excellent speed. Via performance monitor, we can see that the rotation of full regions from mirror to parity is also working well once the mirror tier has reached a specified capacity level.
Time to dive into the Veeam logs I would say.
Veeam backup job log
So the next stop is the Veeam logs themselves. While those can seem a little intimidating, they are very useful to scroll through. And sure enough, we find the following in one of the stalled jobs its backup log.
This goes on all through the night …
For hours on end … it goes on that way.
VIRTUAL MACHINE TASK LOGS 1
When we look at the task log of ar virtual machine that is still at 0% we see the same reflected there. Note that nothing happens between 22:465 and 05:30, that’s when I disabled and enabled the vNIC of the preferred networks in the VBR virtual machine and it all sprung back to life.
notice the total stand still form 22:46 to 05:30 …
So it is clear we have a network issue of some sort. We checked the repository servers and the Hyper-V cluster but there everything is just fine. So where is it?
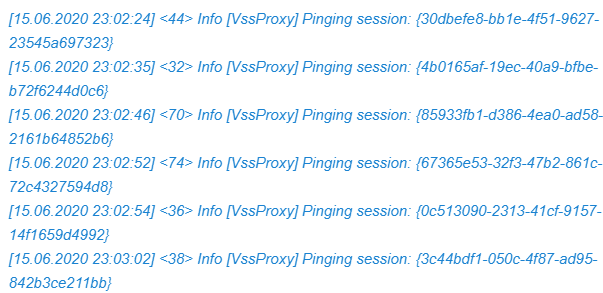
Virtual Machine task logs 2
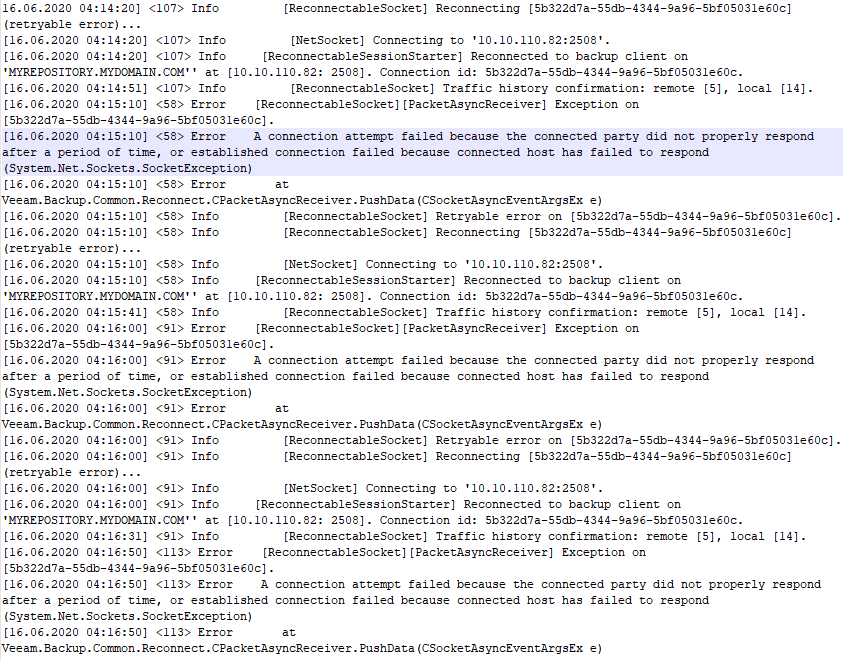
We dive into the task log of one of the virtual machines who’s backing up and that is hanging at 88%. There we see one after the other reconnect to the repository IP (over the preferred network as defined in VB). That also happens all night long until we reset the VBR virtual machine’s preferred network vNICs. In the log snippet below notice the following:
Error A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond (System.Net.Sockets.SocketException)
From the logs we deduct that the network error appears to be on the VBR virtual machine itself. This is confirmed by the fact that bouncing the vNICs of the preferred network (10.10.110.x is the preferred network subnet) on the VBR virtual machine kicks the jobs back into action. So what is the issue? So we start checking the network configurations and settings. The switch ports, pNICs, vNIC, vSwitches etc. to find out what’s going on, As it seems to work for days or a week before the issue shows up we suspect a jumbo frame issue so we start there.
The solution
While checking the configuration we to make sure jumbo frames are enabled on the vNIC and the pNICs of the vSwitch’s NIC team. That’s when we notice the jumbo frames are missing from those pNICs. So we set those again.
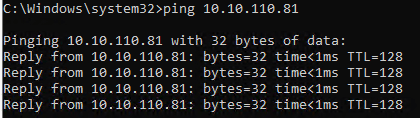
From the VBR virtual machine we run some ping tests. The default works fine.
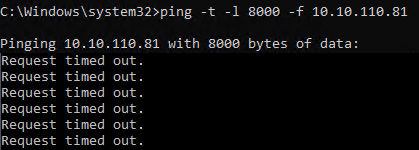
When we test with jumbo frames however we notice something. The ping tests do not complain about jumbo frames being too large and that with the “do not fragment” option set the “Packet needs to be fragmented but DF set.” Note it just says “request timed out”. This indicates an issue right here, jumbo frames are set but they do not work.
So the requests time out, it does not complain about the jumbo frames … so we have another issue here than just the jumbo frame settings
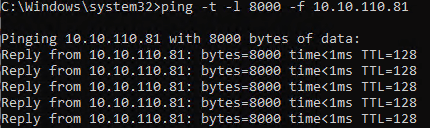
As the requests time out and the ping test does not complain about the jumbo frames we have another issue here than just the jumbo frame settings. It smells of a firmware and/or driver issue. So we dive a bit further. That’s when I notice the driver for the relevant pNICs (Broadcom) is the inbox Windows driver. That’s no good. The inbox drivers only exists to be able to go out and fetch the vendor’s driver and firmware when need, as a courtesy so to speak. We copy those to the hosts that require an update. In this case, the nodes where the VBR virtual machine can run. The firmware update requires a reboot. When the host is up and the VBR virtual machine is running I test again.
Bingo, now a ping test succeeds.
Success
What happened?
So did we really forget to update the drivers? Did we walk out of the offices to go in lockdown for the Corona crisis and forget about it? In the end, it turned out they did run the updates for the physical hosts. But for some reason, the Broadcom firmware and drivers did not get updated properly. However, that failed update seems to have also removed the Jumbo frame settings from the pNICs that are used for the virtual switch. After fixed both of these we have not seen the issue return.
Remarks
The preferred networks do not absolutely have to be present on the VBR server itself. Define, yes, present, no. But it speeds up backup job initialization a lot when they are there present on the VBR server and Veeam also indicates to do so in their documentation.
Why jumbo frames? Ah well the networks we use for the preferred networks are end to end jumbo frame enabled. So we maintain this in to the VBR server. We might get away by not setting jumbo frames on the VBR server but we want to be consistent.
Conclusion
It pays to make sure you have all settings correctly configured and are running the latest and greatest known good firmware. But that should have been the case here. And it all worked so well for quite a while before the backup jobs stall. The issue can lie in the details and sometimes things are not what you assume they are. Always verify and verify it again.
I hope this helps someone out there if they are ever troubleshooting 100% stalled Veeam backup jobs If you need help, reach out in the comments. There are a lot of very experienced and respected people around in my network that can help. Maybe even I can lend a hand and learn something along the way.