Introduction
Recently I was implementing a high available Kemp LoadMaster X15 system. I prepared everything, documented the switch and LM-X15 configuration, and created a VISIO to visualize it all. That, together with the migration and rollback scenario was all presented to the team lead and the engineer who was going to work on this with us. I told the team lead that all would go smoothly if my preparations were good and I did not make any mistakes in the configuration. Well, guess what, I made a mistake somewhere and had to solve a Kemp LoadMaster ad digest – md2=[31084da3…] md=[20dcd914…] – Check vhid, password and virtual IP address log entry.
Check vhid, password and virtual IP address
As, while all was working well, we saw the following entry inundate the system message file log:
<date> <LoadMasterHostName> ucarp[2193]: Bad digest – md2=[xxxxx…] md=[xxxxx…] – Check vhid, password and virtual IP address
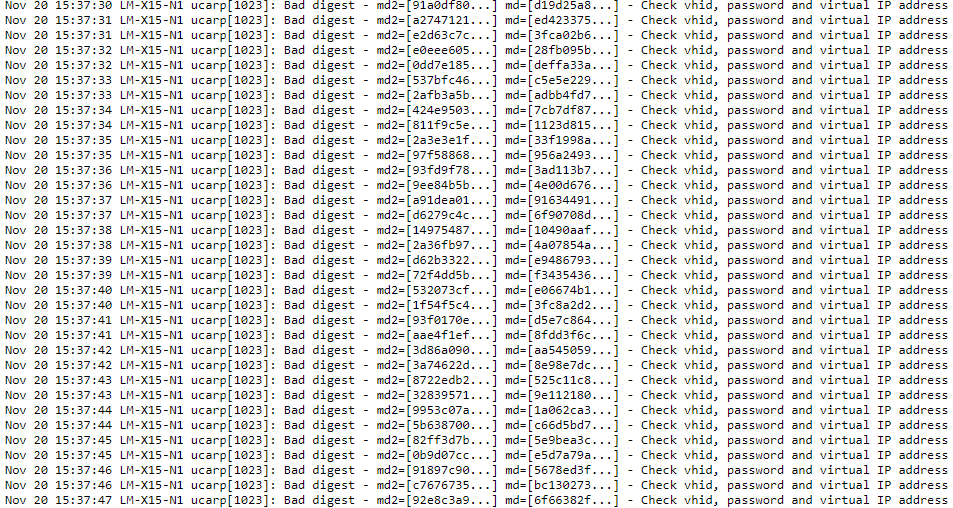
Wait a minute, as far as I know all was OK. The VHID was unique for the HA pair and we did not have duplicate IP addresses set anywhere on other network appliances. So what was this about?
Figuring out the cause
Well, we have a bond0 on eth0 and eth2 for the appliance management. We also have eth1 which is a special interface used for L1 health checks between the Loadmasters. We don’t use a direct link (different racks) so we configure them with an IP on a separate dedicated subnet. Then we have the bonds with the VLAN for the actual workloads via Virtual Services.
We have heartbeat health checks on bond0, eth1 and on at least one VLAN per bonds for the workloads.
Confirm that Promiscuous mode and PortFast are enabled. Check!
HA is configured for multicast traffic in our setup so we confirm that the switch allows multicast traffic. Check!
Make sure that switch configurations that block multicast traffic, such as ‘IGMP snooping’, are disabled on the switch/switch ports as needed. Check!
Now let’s look at possible causes and check our confguration:
So what else? The documentation states as possible other causes the following:
- There is another device on the network with the same HA Virtual ID. The LoadMasters in a HA pair should have the same HA Virtual ID. It is possible that a third device could be interfering with these units. As of LoadMaster firmware version 7.2.36, the LoadMaster selects a HA Virtual ID based on the shared IP address of the first configured interface (the last 8 bits). You can change the value to whatever number you want (in the range 1 – 255), or you can keep it at the value already selected. Check!
- An interface used for HA checks is receiving a packet from a different interface/appliance. If the LoadMaster has two interfaces connecting to the same switch, with Use for HA checks enabled, this can also cause these error messages. Disable the Use for HA checks option on one of the interfaces to confirm the issue. If confirmed, either leave the option disabled or move the interface to a separate switch.
I am sure there is no interference from another appliance. Check! As we had checked every other possible cause the line in red caught my attention. Could it be?
Time for some packet captures
So we took a TCP dump on bond0 and looked at it in Wireshark. You can make a TCP dump via debug options under System Log Files.
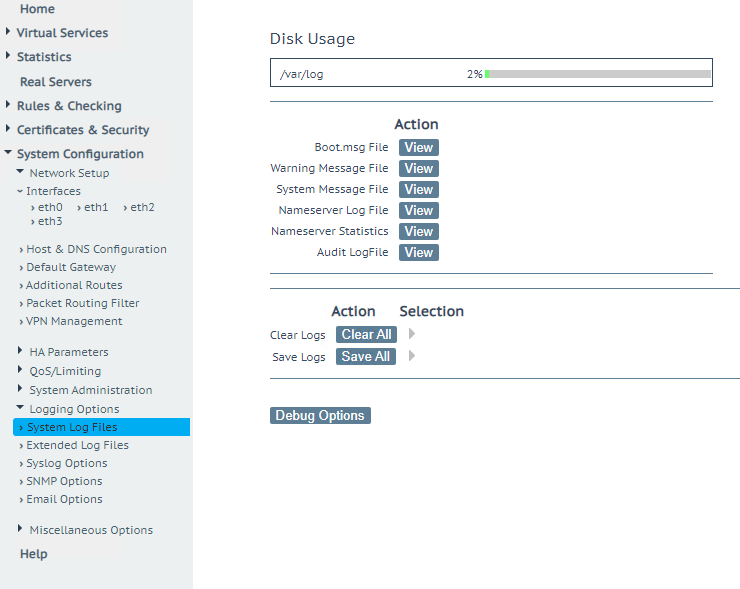
Select your interface, click start, after 10 seconds or so click stop and download the dump
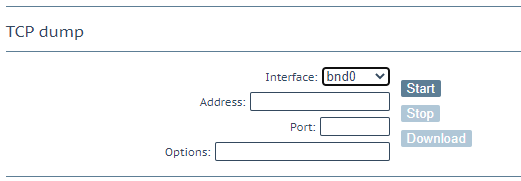
Do note that Wireshark identifies this as VRRP, but the LoadMaster uses CARP (open source) do set it to decode as CARP, that way you’ll see more interesting information in Info
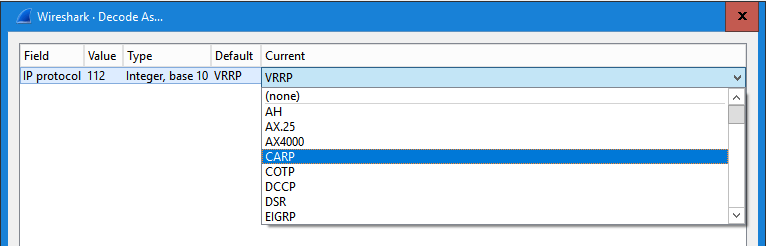
Also filter on ip.dst == 244.0.0.18 (multicast address). What we get here is that on eth0 we see multicasts from eth1. That is the case described in the documentation. Aha!
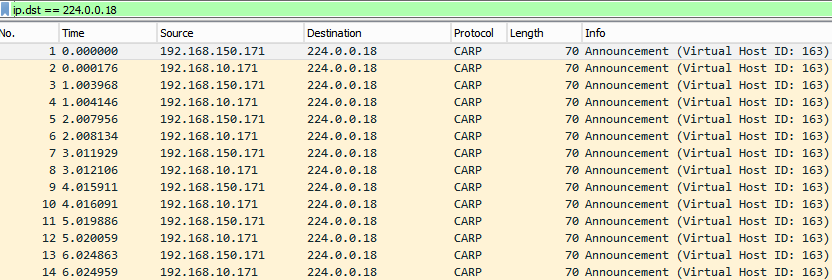
So now what, do we need to move eth1 to another switch to solve this? Or disable the HA check? No, luckily not. Read on.
The fix for Check vhid, password and virtual IP address
No, I did not use one or more separate switches just to plug in the heartbeat HA interfaces on the LoadMasters. What I did is create a separate VLAN for the eth0 HA heartbeat uplink interfaces on the switches. This way I ensure that they are in a separate unicast group from the management interface uplinks on the switches
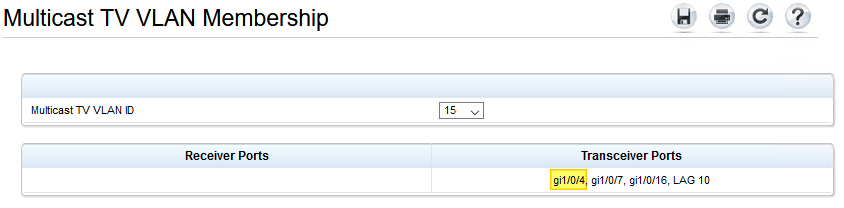
By default the Multicast TV VLAN Membership is per VLAN. The reason the actual workload interfaces did not cause an issue when we enabled HA checks is that these were trunk ports with a number of allowed VLANs, different from the management VLAN, which prevents this error being logged in the first place.
That this works was confirmed in the packet trace from the LM-X15 after making the change.

So that was it. The error was gone and we could move along with the project.
Conclusion
Well, I should have know as normally I do put those networks not just in a separate subnet but also make sure they are on different VLANs. This goes to show that no matter how experienced you are and how well you prepare you will still make mistakes. That’s normal and that’s OK, it means you are actually doing something. Key is how you deal with a mistake and that why I wrote this. To share how I found out the root cause of the issue and how I fixed it. Mistakes are a learning opportunity, use them as such. I know many organizations frown upon a mistake but really, these should grow up and don’t act this silly.