
Introduction
Time to take a first look at shared virtual disks in Windows Server 2016 and how they are set up. Shared VHDX was first introduced in Windows Server 2012 R2. It provides shared storage for use by virtual machines without having to “break through” the virtualization layer. This way is still available to us in Windows Server 2016. The benefit of this is that you will not be forced to upgrade your Windows Server 2012 R2 guest clusters when you move them to Windows Server 2016 Hyper-V cluster hosts.
The new way is based on a VHD Set. This is a vhds virtual hard disk file of 260 MB and a fixed or dynamically expanding avhdx which contains the actual data. This is the “backing storage file” in Microsoft speak. The vhds file is used to handle the coordination of actions on the shared disk between the guest cluster nodes?

Note that an avhdx is often associated with a differencing disk or checkpoints. But the “a” stands for “automatic”. This means the virtual disk file can be manipulated by the hypervisor and you shouldn’t really do anything with it. As a matter of fact, you can rename this off line avhdx file to vhdx, mount it and get to the data. Whether this virtual disk is fixed or dynamically expanding doesn’t matter.
You can create on in the GUI where it’s just a new option in the New Virtual Hard Disk Wizard.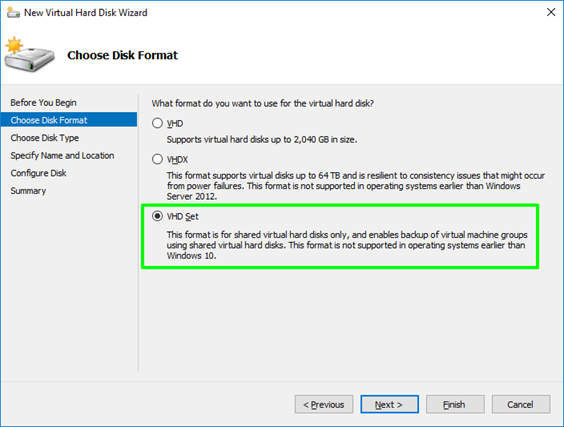
Or via PowerShell in the way you’re used to with the only difference being that you specify vhds as the virtual disk extension.

In both cases both vhds and avhdx are created for you, you do not need to specify this.
You just add it to all nodes of the guest cluster by selecting a “Shared Drive” to add to a SCSI controller …
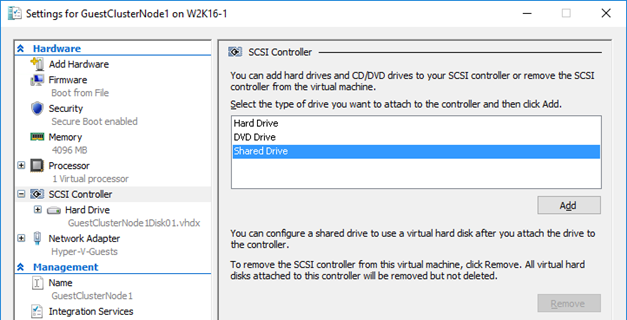
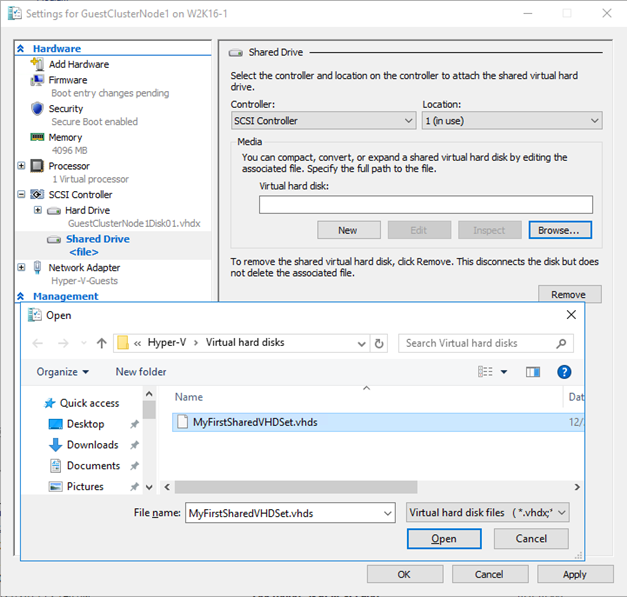
… browsing to the vhds , selecting it and applying the settings to the virtual machine. Do this for all guest cluster nodes
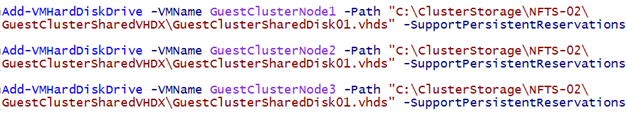
Naturally PowerShell is your friend, simple and efficient.
Rules & Restrictions
As before shared virtual disk files have to be attached to a vSCSI controller in the virtual machines that access it and it needs to be stored on a CSV. Both block level storage or a SMB 3 file share on a Scale Out File Server will do for this purpose. If you don’t store the shared VHDX or VHD Set on a CSV you’ll get an error.
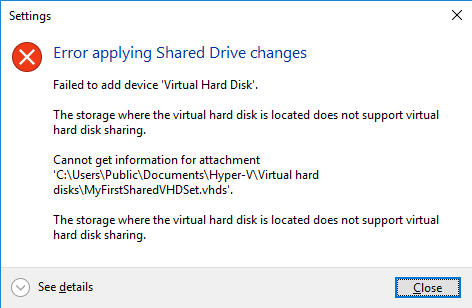
Sure for lab purposes you can use an non high available SMB 3 share “simulating” a real SOFS share but that’s only good for your lab or laptop.
The virtual machines will see this shared VHDX as shared storage and as such it can be used as cluster storage. This is an awesome concept as it does away with iSCSI or virtual FC to the virtual machines in an attempt to get shared storage when SMB 3 via SOFS is not an option for some reason. Shared VHDX introduces operational ease as it avoids the complexities and drawbacks of not using virtual disks with iSCSI or vFC.
In Windows Server 2012 R2 we did miss some capabilities and features we have come to love and leverage with virtual hard disks in Hyper-V. The reason for this was the complexity involved in coordinating such storage actions across all the virtual machines accessing it. These virtual machines might be running on different hosts and, potentially the shared VHDX could reside on different CSVs. The big four limitations that proved to be show stopper for some use cases are in my personal order of importance:
- No host level backup
- No on line dynamic resize
- No storage live migration
- No checkpoints
- No Hyper-V Replica support
I’m happy to report most of these limitations have been taken care of in Windows Server 2016. We can do host level backups. We can online resize a shared VHDX and we have support for Hyper-V replica.
Currently in 2016 TPv4 storage live migration and checkpoints (both production and standard checkpoints) are still missing in action but who knows what Microsoft is working on or has planned. To the best of my knowledge they have a pretty good understanding of what’s needed, what should have priority and what needs to be planned in. We’ll see.
Other good news is that shared VHDX works with the new storage resiliency feature in Windows Server 2016. See Virtual Machine Storage Resiliency in Windows Server 2016 for more information. Due to the nature of clustering when a virtual machine loses access to a shared VHDX the workload (role) will move to another guest cluster node that still has access to the shared VHDX. Naturally if the cause of the storage outage is host cluster wide (the storage fabric or storage array is toast) this will not help, but other than that it provides for a good experience. The virtual machine guest cluster node that has lost storage doesn’t go into critical pause but keeps polling to see if it regains access to the shared VHDX. When it does it’s reattached and that VM becomes a happy fully functional node again.
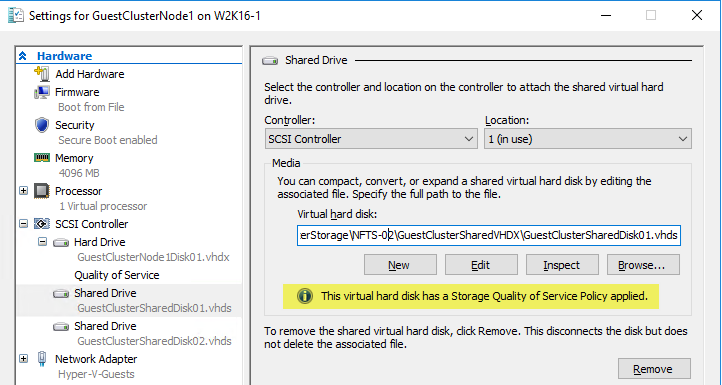
It also supports the new Storage Qos Policies in Windows Server 2016, which is something I’ve found during testing.
Thanks for reading!


