This is a 2nd post in a series of 4. Here’s a list of all parts:
- Introducing 10Gbps Networking In Your Hyper-V Failover Cluster Environment (Part 1/4)
- Introducing 10Gbps With A Dedicated CSV & Live Migration Network (Part 2/4)
- Introducing 10Gbps & Thoughts On Network High Availability For Hyper-V (Part 3/4)
- Introducing 10Gbps & Integrating It Into Your Network Infrastructure (Part 4/4)
Introduction
In this post we continue along the train of thought we set in a previous blog post “Introducing 10Gbps Networking In Your Hyper-V Failover Cluster Environment (Part 1/4)”. Let’s say you want to set up a Hyper-V cluster for SQL Server virtualization. Your business & IT manager told you the need to provide them with the best performance you can get. They follow up on that statement with a real budget so you can buy high end servers (blades or rack) and spec them out optimally for SQL Server. You take into consideration NUMA issues, vCPU:pCPU ratios, SQL memory demands, the current 4 vCPU limit in hyper-V, etc. By the way, this will be > 16vCPU with Windows Server 8, which leads me to believe the 64GB memory ceiling for virtual machines will also be broken. But for now this means that with regard to CPU & memory you’ve done all you can. That leaves only networking and IO to deal with. Now the IO is food for another & very extensive discussion, but basically you have to design that around the needs of the application(s) or you’ll be toast. The network part is what we’ll tackle here.
Without going into details, what does a Hyper-V cluster need in terms of networking?
| Who/What |
Function |
Traffic |
Connection Type |
| Host Management |
Hyper-V host connectivity. |
Relatively low bandwidth. But don’t forget about deploying VMs or backups. |
Public |
|
|
|
|
| VM Network |
Provides network connectivity to the VMs |
Very dependent on the VMs using it. |
Dedicated Hyper-V |
| Cluster Heartbeat |
Internal cluster communication to determine the status of other cluster nodes |
Not much traffic but low latency or cluster might think it’s in trouble due to dropped packets. OK to combine with CSV. |
Private Cluster Network |
| Cluster Shared Volume (CSV) |
For updating CSM metadata & scenarios where redirected I/O is required |
Mostly idle. When in redirected I/O it demands high bandwidth & low latency required. |
Private Cluster Network |
| Live Migration |
Used to transfer the running VM’s from one cluster node to another |
Mostly idle. When Live Migrating it demands high bandwidth & low latency required. |
Private Cluster Network |
Host Management: It is fine to leave this on 1Gbps, unless you have a need to deploy massive amounts of VMs or you backups are consuming all bandwidth. If so consider dedicated NICs for those roles and/or 10Gbps. Also note that you might be able to leverage your SAN for virtual machine deployment / backups.
VM Network: Use multiple “single” NICs or NIC teams to spread both the load and the risk. Remember that you can lose the host management or CSV network of a node, without affecting your virtual machine connectivity but not the virtual machine network(s). So don’t put all your eggs in one basket. So do consider multiple NICs and NIC teaming. Do remember that there are other bottle necks than bandwidth to a virtual machine running apps so don’t go completely overboard as there is no single magic bullet here for virtual machine performance. 2 or 3 will do perfectly fine. What about backups in the guest? Yes, that’s an extra burden but there are better solutions than that and if you hit and bandwidth issue with guest based backups it’s time to investigate them seriously. As you will see in these series I’m not a mincer with NIC ports but there’s no need to have one for every 2 Virtual machines. If you have really high bandwidth needs consider 10Gbps, not a truck load of NIC ports.
Heartbeat: Due to the mostly moderate needs it is often combined with the CSV traffic.
Cluster Shared Volume (CSV): Well you have the need for metadata of the clustered shared volumes. But that’s not all. You also have redirected access when you’re doing backups, defragmenting your CSV storage or when the storage paths are unavailable. So go for 10Gbps when you can, especially since this is your backup path for Live Migration traffic!
Side Note: Don’t say that Redirected Access over the CSV network will never happen when you have redundant storage paths. We’ve seen it happen in an environment with dual FC HBA cards, dual SAN controllers and the works. Redirected Access saved our service availability during that event! What happened exactly and how it all ties together is a long story and complicated but in essence an arbitrated loop management module when haywire and caused a loop, the root cause of this was a defective disk. When that event was over one of the controllers went nuts and decided this wasn’t his cup of tea and called it a day. Guess what? Some servers could not failover to the other controller as something went wrong in the internal workings of the SAN itself, dual HBA didn’t help here. How did our services stay available? Thanks to Redirected Access. It was at 1Gbps speeds so that hurt a little but we kept ‘m running. Our vendor worked through this with us but things where pretty bad and it was pucker time. However this is one example where we kept our services running for 24 hours (whilst working at the issue with the vendor) via redirected access. The bad thing was we needed to take the spare controller of line & restart both to get the replacement controller to be recognized, yes a complete shutdown of the cluster nodes to restart both SAN controllers. I still remember the mail I send and the call I made to management that is was shutting down the business for 30 minutes. But it was not because of Hyper-V, quite the opposite; it helped us out a lot!
Also note that when you run software VSS based backups and disk defragmentation on your CSV storage you’ll be running in Redirected Access mode. Also see https://blog.workinghardinit.work/2011/06/02/some-feedback-on-how-to-defrag-a-hyper-v-r2-cluster-shared-volume/ Some Feedback On How to defrag a Hyper-V R2 Cluster Shared Volume
Live Migration: The bigger and better the pipe the faster Live Migration gets done. With high density or resource (memory) intensive servers this becomes a lot more important. Think of SQL Server, Exchange consuming 16, 24, 32 or more GB of memory. So do consider 10Gbps.
iSCSI: As we are using Fiber Channel in our SAN we did not include iSCSI in the networking needs table above. Now I do want to draw your attention to the need for iSCSI in the virtual machines themselves. This is needed for clustering within the virtual machines. Today this is almost a requirement as clustering in the guest becomes more and more important. You’ll need at least two NIC ports in production for this, if possible in on two separate cards for ultimate redundancy. Now as a best practice we won’t share the iSCSI NICS between the hosts and the guests. I do this in the lab but won’t have it in production. So that could mean at least two more NIC ports. With 10Gbps you’ll have ample performance but depending on your IO needs you might want 4 if you’re using 1Gbps so those NIC numbers are rising fast.
| What |
Function |
Traffic |
Connection Type |
| iSCSI Guest |
Virtual machine shared storage. |
High bandwidth need, low latency is required to get good I/O |
Dedicated to Hyper-V |
| iSCSI host |
Host shared storage |
High bandwidth need, low latency is required to get good I/O |
Excluded from cluster, dedicated to the host. |
What to move to 10Gbps?
Cool, you think, let’s throw some 10Gbps NICs & switches into our network. After that, depending on the rest of your network equipment & components, your virtual machines might be able to talk to other virtual and physical servers on the network at speeds up to 10Gbps or at least 1Gbps. I kind of hope that none of you are running 100 Mbps in your server racks today. And last but not least, with your 10Gbps network you’ll be able to do get the best performance for your CSV and Live Migration traffic. Life is good!
Until your network engineer hears about your plans. All of a sudden it’s no so cool anymore. You certainly woke the network people up! They’re nervous now they have seen all the double (redundancy) lines you’ve drawn on your copy of the schema representing the rack / server room network. They start mumbling things about redundancy, loops, RSTP, MSTP, LAG, stacking and a boatload other acronyms that sound like you’ve heard ‘m before but can’t quite place. They also talk about doom and gloom scenarios that might very well bring down the network. So unless you are the network admin you should dust of your communication skills and get them on board. So for your sake I hope they’re not the kind of engineers that states that most network problems that can’t be solved by removing servers and applications that ruin the nirvana of their network design. If so they’ll be vary weary of that “virtual switch” you’re talking about as well.
The Easy Way Out – A Dedicated CSV & Live Migration Network
Let’s say that you need a lot more time to get to a fully integrated solution for the 10Gbps network architecture figured out and set up. But your manager states you need to improve the Live Migration and other cluster network speeds today. What are your options? Based on the above information your boss is right, the networks that will benefit the most from a move to 10Gbps are CSV and Live Migration (and Heart Beat that piggy backs along with CSV). Now you have to remember that those cluster networks (subnets/VLANs) are for the Heart Beat, CSV and Live Migration cluster traffic only. So basically the only requirement you have is that these run on separate subnets/VLANs (to present them as distinct networks to your failover cluster) and that every node of the cluster can communicate over those subnets/VLANs. This means that you can leave the switches for those networks completely isolated from the rest of the network as shown in the picture below. I used some very common and often used DELL PowerConnect switches (5424, 6248, 8024F) in some scenario drawings for this blog series. They could make that 8024F an unbeatable price/quality deal if they would make them stackable. The sweet thing about stackable switches is that you can do Active-Active NIC teaming across switches rather than active-passive. I never went that way as I’m waiting to see what virtual switch innovations Hyper-V 3.0 will bring us. You see I’m a little cheap after all
But naturally, feel free to think about these scenarios with your preferred ProCurves, CISCO, Juniper, NetGear … switches in mind.
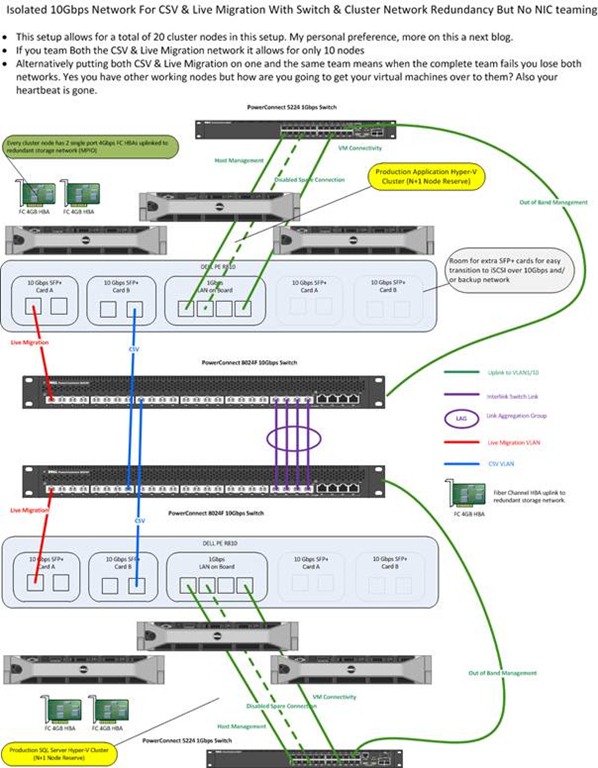
Suddenly things are cool again. The network people get time to figure out an integrated & complete long term solution and you can provide your nodes with 10Gbps for cluster only traffic. By a couple of 10Gbps switches & NICs and you’re on your way. Is this a good idea? I can’t make that call for you. I just provide some ideas. You decide.
The Case For Physically Isolating Them
Now you might wonder if this isn’t very wasteful in resources. Well not necessarily. If your cluster is big enough, let’s say 12-16 nodes or if you have a couple of clusters (4 clusters with 5 nodes for example) this might be not overly expensive. Unless you’re on a converged network, you do (I hope) the same for your storage networks, isolate them that is. You have to when you’re using fiber and you’d better do it when using iSCSI. It provides for the best performance and less complex switch configurations. Remember I mentioned that high availability requires some complexity. Try to keep that complexity as low as possible and when you introduce complexity make sure you can manage it. This serves two purposes. One is making sure that the complexity doesn’t ruin your high availability and two is that you’ll be happy you did it when it comes to troubleshooting and fixing issues. Now you might say that this ruins the concept of converged networks. Academically this is true but when you are filling up ports on switches for a single purpose there is no room for anything else anyway. Don’t lose sight of the aim of a converged network. That is to have the ability to use the same hardware/technology when possible for multiple needs. This gives you options and capabilities where and when needed. It’s not about always using all technology and protocols on each and every switch. Don’t forget also that you’ll need to address QOS/Performance on a converged network per type of traffic. There is also the fact that in brownfield scenario’s you’re dealing with replacing a part of the infrastructure and this example is a good way to get 10Gbps where needed and not making any change on the existing network infrastructure. This reduces risk and impact. As a matter of fact if you plan this right you can do this without service interruption. That means going node by node (maintenance mode, evacuate all VMs), moving the CSV network first for example, and only then the Live Migration network. You’re leveraging the ability of the cluster networks to take on each other’s role here to achieve this.
Another good reason to physically isolate the networks is security. There was an exploit for manipulating VMs during live migrations in 2008 (http://www.eecs.umich.edu/techreports/cse/2007/CSE-TR-539-07.pdf). You can protect against this via very careful switch configuration and VLAN design. But isolating the switches is very easy, clean, and effective as well. Overkill? I don’t know, but perhaps not if you do work for intelligence agencies.
Ethernet Out-of-Band (OOB) Port For Management
Don’t forget you still need to be able to manage those switches but today, in this class of equipment you get an Ethernet Out-of-Band (OOB) port for that. This one you can safely uplink to your regular management network. So if you really don’t need communication with the rest of the network you have no functional reason not to isolate them.
Money, Cost? No Value!
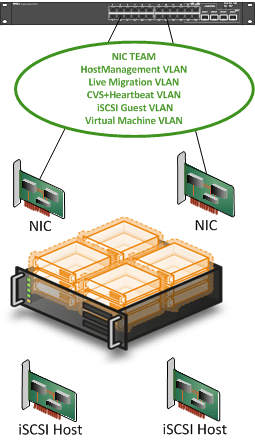
Still, you think, isn’t this very expensive? Well, look at the purpose. Manageable complexity, high availability, and your management stated to eliminate, where possible, any limitation on performance and approved the budget for it all. Put this into perspective. The SQL Server data center editions running on these clusters, combined with the cost of development & maintenance of the databases and applications relying on this infrastructure put that extra money spent on a couple of switches really into perspective. On top of that, you’re not wasting those switches. When the network people get their plans finished they’ll be integrated into the final solution if still needed and possible. Don’t forget that you might use all ports for just cluster traffic depending on the number of hosts you have! So even without integrating them into the rest of the network, you’re still getting very solid results. On top of that, sometimes you get to build solutions where budget is not the first, last, and only concern. Sweet! I do know some people who’ll call me a money-wasting nut case J. But get real, when you’re building highly available, highly performing failover clusters and you’re in a discussion about the cost of a couple of NIC ports and you are going to adjust your design over that, perhaps you have a sponsorship issue. Put this into perspective. Building a Hyper-V cluster is not a competition where the one who uses the least NIC ports/cards and switch ports/ switches win. That’s why it hurts when I see designs like this claiming victory:
What I want to see is more like this:
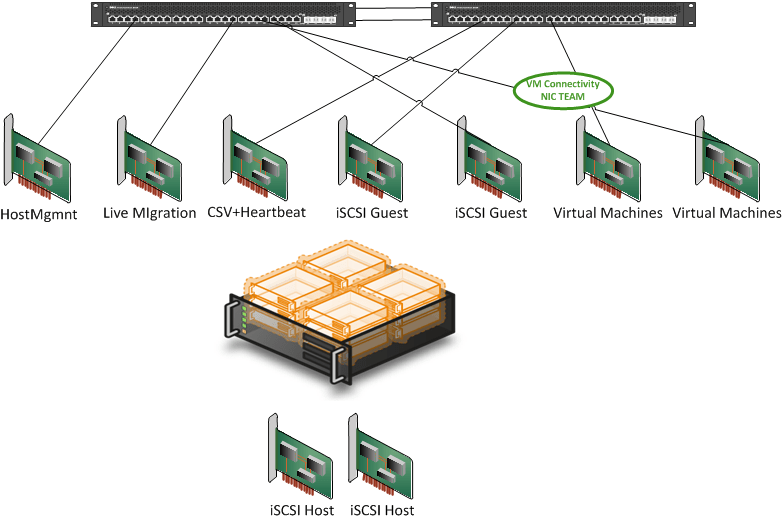
But that will never fit into a blade design! Really? Have you seen the blades like the DELL M910? It’s a beast, comparable to the R810. It’s was the first blade I really felt like buying. Cisco also entered that market with guns drawn and is pushing HP to keep performing. So Again put the NIC/Switch and NIC port/Switch Port count into perspective against what you’re trying to achieve. To quote Anton Ego “… you know what I’m craving? A little perspective, that’s it. I’d like some fresh, clear, well-seasoned perspective.”




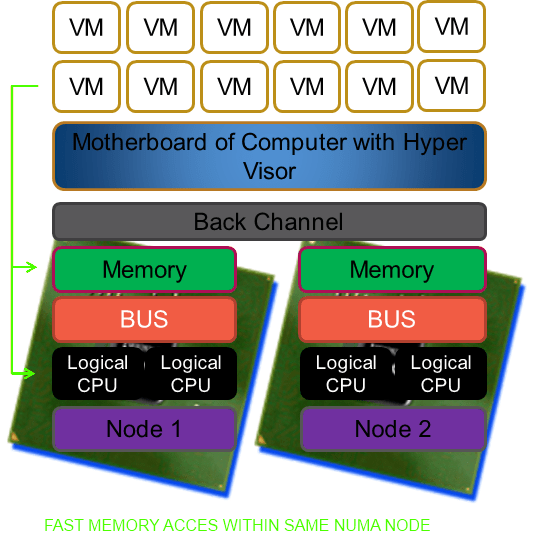
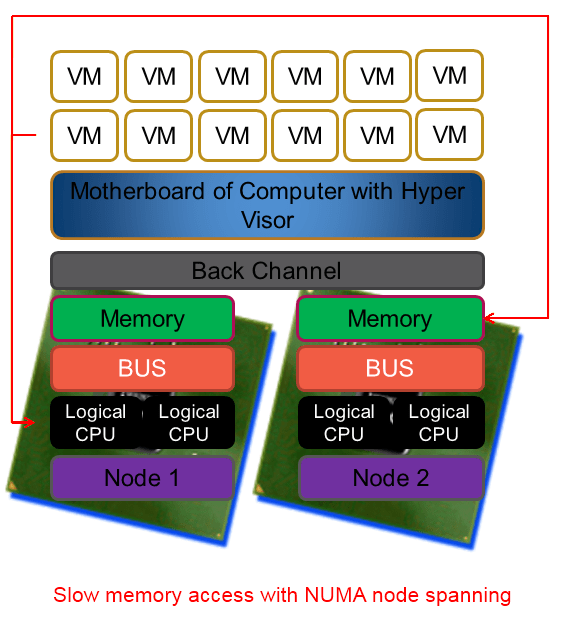 To make it very clear NUMA is great and helps us in a lot of ways. But under certain conditions and with certain applications it can cause us to take a (serious) performance hit. And if there is anything certain to ruin a system administrator’s day than it is a brand new server with a bunch of CPUs and loads of RAM that isn’t running any better (or worse?) than the one you’re replacing. Current hypervisors like Hyper-V are NUMA aware and the better servers like SQL Server are as well. That means that under the hood they are doing their best to optimize the CPU & memory usage for performance. They do a very good job actually and you might, depending on your environment, never ever know of any issue or even the existence of NUMA.
To make it very clear NUMA is great and helps us in a lot of ways. But under certain conditions and with certain applications it can cause us to take a (serious) performance hit. And if there is anything certain to ruin a system administrator’s day than it is a brand new server with a bunch of CPUs and loads of RAM that isn’t running any better (or worse?) than the one you’re replacing. Current hypervisors like Hyper-V are NUMA aware and the better servers like SQL Server are as well. That means that under the hood they are doing their best to optimize the CPU & memory usage for performance. They do a very good job actually and you might, depending on your environment, never ever know of any issue or even the existence of NUMA.