
First of all to be able to join in this little discussion you need to know what NUMA is and does. You can read up on that on the Intel (or AMD) web site like http://software.intel.com/en-us/blogs/2009/03/11/learning-experience-of-numa-and-intels-next-generation-xeon-processor-i/ and http://software.intel.com/en-us/articles/optimizing-software-applications-for-numa/. Do have a look at the following SQL Skills Blog http://www.sqlskills.com/blogs/jonathan/post/Understanding-Non-Uniform-Memory-AccessArchitectures-(NUMA).aspx which has some great pictures to help visualize the concepts.
What Is It And Why Do We Care?
We all know that a CPU contains multiple cores today. 2,4,6,8,12,16 etc. cores. So in terms of a physical CPU we tend to talk about a processor that fits in a socket and about cores for logical CPUs. When hyper-threading is enabled you double the logical processors seen and used. It is said that Hyper-V can handle hyper threading so you can leave it on. The logic being that it will never hurt performance and can help to improve it. I suggest you test it as there was a performance bug with it once. A processor today contains it own memory controller and access to memory from that processor is very fast. The NUMA node concept is older than the multi core processor technology but today you can state that a NUMA node translates to one processor/socket and all cores contained in that processor belong to the same NUMA node. Sometimes a processor contains two NUMA node like the AMD 12 core processors. In the future, with the ever-increasing number of cores, we’ll perhaps see even more NUMA nodes per processor. You can state that all Intel processors since Nehalem with Quick Path Interconnect and AMD processors with Hyper-Transport are NUMA processors. But To be sure, check with your vendors before buying. Assumptions right?
Beyond NUMA nodes there is also a thing called processor groups that help Windows to use more than 64 logical processors (its former limit) by grouping logical processors into groups of which Windows handle 4 meaning in total Windows today can support 4*64=256 logical processors. Due to the fact that memory access within a NUMA node is a lot faster than between NUMA nodes you can see where a potential performance hit is waiting to happen. I tried to create a picture of this concept below. Now you know why I don’t make my living as a graphical artist.
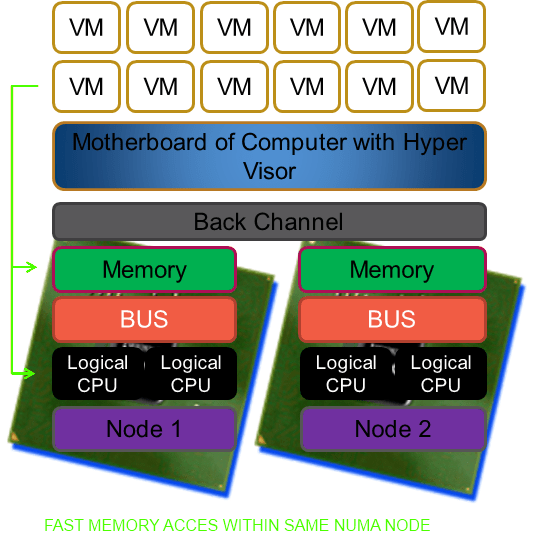
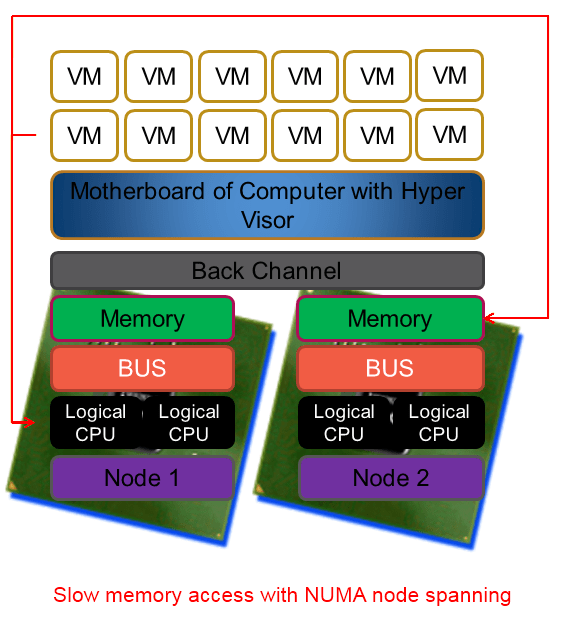 To make it very clear NUMA is great and helps us in a lot of ways. But under certain conditions and with certain applications it can cause us to take a (serious) performance hit. And if there is anything certain to ruin a system administrator’s day than it is a brand new server with a bunch of CPUs and loads of RAM that isn’t running any better (or worse?) than the one you’re replacing. Current hypervisors like Hyper-V are NUMA aware and the better servers like SQL Server are as well. That means that under the hood they are doing their best to optimize the CPU & memory usage for performance. They do a very good job actually and you might, depending on your environment, never ever know of any issue or even the existence of NUMA.
To make it very clear NUMA is great and helps us in a lot of ways. But under certain conditions and with certain applications it can cause us to take a (serious) performance hit. And if there is anything certain to ruin a system administrator’s day than it is a brand new server with a bunch of CPUs and loads of RAM that isn’t running any better (or worse?) than the one you’re replacing. Current hypervisors like Hyper-V are NUMA aware and the better servers like SQL Server are as well. That means that under the hood they are doing their best to optimize the CPU & memory usage for performance. They do a very good job actually and you might, depending on your environment, never ever know of any issue or even the existence of NUMA.
But even with a NUMA knowledgeable hypervisor and NUMA aware applications you run the risk of having to go to remote memory. The introduction of Dynamic Memory in Windows 2008 R2 SP1 evens increases this likelihood as there is a lot of memory reassigning going on. Dynamic Memory actually educated a lot of Hyper-V people on what NUMA is and what to look out for. Until Dynamic Memory came on the scene, and the evangelizing that came with it by Microsoft, it was “only” the people virtualizing SQL Server or Exchange & other big hungry application that were very aware of NUMA with its benefits and potential drawbacks. If you’re lucky the application is NUMA aware, but not all of them are, even the big names.
A Peek Into The Future
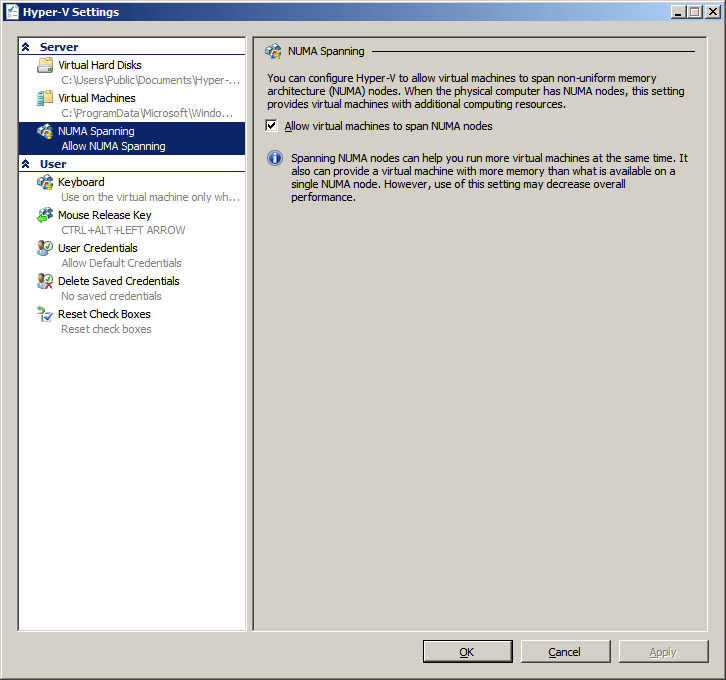
As it bears on this discussion, what is interesting that leaked screenshots from Hyper-V 3.0 or vNext … have NUMA configuration options for both memory and CPU at the virtual machine level! See Numa Settings in Hyper-V 3.0 for a picture. So the times that you had to script WMI calls (see http://blogs.msdn.com/b/tvoellm/archive/2008/09/28/looking-for-that-last-once-of-performance_3f00_-then-try-affinitizing-your-vm-to-a-numa-node-.aspx) to assign a VM to a NUMA node might be over soon (speculation alert) and it seems like a natural progression from the ability to disable NUMA with W2K8R2SP1 Hyper-V in case you need it to avoid NUMA issues at the Hyper-V host level. Hyper-V today is already pretty NUMA aware and as such it will try to get all memory for a virtual machine from a single NUMA node and only when that can’t be done will it span across NUMA nodes. So as stated, Hyper-V with Windows Server 2008 R2 SP1 can prevent this from happening as we can disable NUMA for a Hyper-V host now. The downside is that you can’t get more memory even if it’s available on the host.
A working approach to reduce possible NUMA overhead is to limit the number of CPUs to 2 as this gives the largest amount of memory to the CPUs, in this case, 50%. 4 CPUs only control 25%, etc. So with more CPU (and NUMA nodes), the risk of NUMA spanning is getting bigger very fast. For memory-intensive applications scaling out is the way to go. Actually, you could state that we do scale up the NUMA nodes per socket (lots of cores with the most amount of directly accessible memory possible) and as such do not scale up the server. If you can keep your virtual machines tied to a single CPU on a dual-socket server to try and prevent any indirect memory access and thus a performance hit. But that won’t always work. If you ever wondered when an 8/12/16 core CPU comes in handy, well voila … here a perfect case: packing as many cores on a CPU becomes very handy when you want to limit sockets to prevent NUMA issues but still need plenty of CPU cycles. This should work as long as you can address large amounts of RAM per socket at fast speeds and the CPU internally isn’t cut up into too many multiple NUMA nodes, which would be scaling out NUMA node in the same CPU and we don’t want that or we’re back to a performance penalty.
Stacking The Deck
One way of stacking the deck in your favor is to keep the heavy apps on their own Hyper-V cluster. Then you can tweak it all you want to optimize for SQL Server, Exchange, … etc. When you throw these virtual machines in your regular clusters or for crying out loud on a VDI cluster you’re going to wreak havoc on the performance. Just like mixing server virtualization & VDI is a bad idea (don’t do it), throwing vCPU hungry, memory-hogging servers on those clusters is just killing of performance and capacity of a perfectly good cluster. I have gotten into arguments over this as something one giant cluster for whatever need is better. Well no, you’ll end up micromanaging placement of VM with very different needs on that cluster effectively “cutting” it up in smaller “cluster parts”. Now is separate clusters for different needs always the better approach? No, it depends, If you only have some small SQL Server needs you get away with one nice cluster. It depends, I know, the eternal consultant’s answer, but I have to say it. I don’t want to get angry emails from managers because someone set up a 6 node cluster for a couple of SQL Server Express databases. There are also concepts called testing, proof of concept, etc. It’s called evidence-based planning. Try it, it has some benefits that become very apparent when you’re going to virtualize beefy SQL Server, SharePoint, and Exchange servers.
How do you even know it is happening apart from empirical testing. Aha, excellent question! Take a look at the “Hyper-V VM Vid Numa Node” counter set and read this blog entry by on this subject http://blogs.msdn.com/b/tvoellm/archive/2008/09/29/hyper-v-performance-counters-part-five-of-many-hyper-vm-vm-vid-numa-node.aspx. And keep an eye on the event log for http://technet.microsoft.com/hi-in/library/dd582929(en-us,WS.10).aspx (for some reason there is no comparable entry for W2K8R2 on TechNet)
Conclusions
To conclude, all of the above is why I’m interested in some of the latest generation of servers. The architecture of the hardware allows for the processor to address twice the “normal” amount of memory when you only put dual CPUs on a quad-socket motherboard. The Dell PowerEdge R810 and the M910 have this and it’s called a FlexMemory Bridge and that allows more memory to be available without a performance hit. They also allow for more memory per socket at higher speeds. If you put a lot of memory directly addressable to one CPU you see a speed drop. A DELL R710 with 48 GB of RAM runs at 1033 MHZ but put 96 GB in there and you fall back to 800 Mhz. So yes, bring on those new quad-socket motherboards with just 2 sockets used, a bunch of fast direct accessible memory in a neat 2 unit server package with lost of space for NIC cards & FC HBAs if needed. Virtualization heaven 🙂 That’s what I want so I can give my VMs running SQL Server 2008 R2 & “Denali” (when can I call it SQL Server 2012?) a bigger amount of directly accessible memory form their NUMA node. This can be especially helpful if you need to run NUMA unaware applications like SAP or such. Testing is the way to go for knowing how well a NUMA aware hypervisor and a NUMA aware application figure out the best approach to optimize the NUMA experience together. I’m sure we’ll learn more about this as more and more information becomes available and as technology evolves. For now, we optimize for performance with NUMA where we can, when we can with what we have 🙂 For Exchange 2010 (we even have virtualization support for DAG mailbox servers now as well) scaling out is easier as we have all the neatly separate roles and control just about everything down to the mail client. With SQL Server applications this is often less clear. There is a varied selection of commercial and homegrown applications out there and a lot of them can’t even scale out, only up. So your mileage of what you can achieve may vary. But for resource & memory heavy applications under your control, for now, scaling out is the way to go.
Pingback: Thinking About Windows 8 Server & Hyper-V 3.0 Network Performance | Working Hard In IT