Introduction
A File-Level Restore in a hardened environment can trip you up. In Veeam Backup & Replication the ability to do file-level restores from virtual machine backups is a handy option to have. In secured environments with an isolated and protected Veeam backup fabric, this is not always a straightforward or fast process. Let’s look at this and make some suggestions for a solution or workarounds.
Veeam File-Level Restore in a hardened environment
Nowadays, it is a common best practice that the Veeam Backup & Replication environment is isolated and independent from the fabrics it protects. It is even more than a best practice and ransomware educated many of us fast and hard on the need for this.
In such an environment every server in the Veeam backup fabric solution is isolated, with their own credentials and not joined or in any way dependent on the environment it is protecting. Dedicated accounts are used to run the actual backup jobs and these are not used for normal administrative or operational tasks.
The majority of Veeam functionality works just fine in such an environment. But there are some things that need to be addressed. One such thing is a file-level restore (FLR). In a secured and isolated environment, an FLR job cannot leverage admin shares to gain access to the virtual machine to where files are being restored or access the data in the backup. To work around this Veeam can leverage PowerShell Direct by which it can securely restore the files into the virtual machine anyway.
But leveraging PowerShell Direct comes at the cost of speed. 7 MB/s is okay for a small number of smaller files. It becomes frustratingly slow when it comes to restoring many and larger files. Minutes turn into hours. In some cases, this just won’t do. In our case, the DBA who needed to do the database restore was not happy and the developers waiting for the restored database were not overly pleased either.
So what other options do we have?
Set up a secured file share in the protected environment
Below we will discuss the other options you have for a File-Level Restore in a hardened environment via FLR in Veeam Backup & Recovery. But first, we prepare a landing zone in the secured environment where we can copy restored files to. For this, we set up a restore share in the protected environment where a few admins that are responsible for backup and restores can write to. No one else can enumerate, read, or write to that share. When a file gets restored there they can copy it over to where the people that need it can access it. This helps protect and limit access to restored files to just the people that need to get to it. The accounts used to access that share from the isolated backup environment do not get admin permissions on the system where that share resides or anywhere else.
Providing a restore share in the protected environment is safe. You only allow certain admins to have access to it, no one else. Since the less trusted environment (the one we protect) allows access from a more secure environment (the backup environment) this does not expose the backup environment to extra danger. At no point does this allow any access to the backup environment from the protected environment.
Use the FLR wizard to copy the files
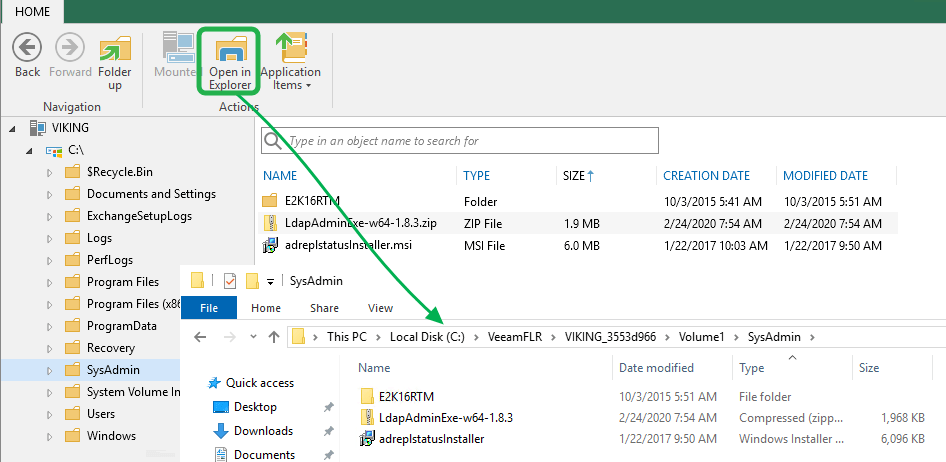
You can use the FLR wizard to copy the file locally in the secured Veeam backup environment.
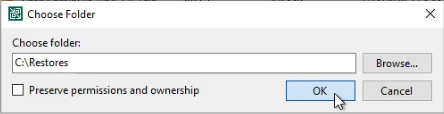
From there you can copy it to the restore share in the protected environment. This is very fast as nothing is. On our network we get 230 MB/s.
But what if you don’t have the space for that locally? Not everyone can have a large local restore disk onWould it not be handy to copy it to restore share in the protected environment directly? Well yes, you can try in the wizard and it will ask for the credentials to access the file share.
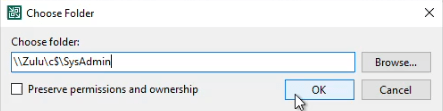
But it will fail to read and restore the backups but this will fail with an “Access is denied” error.
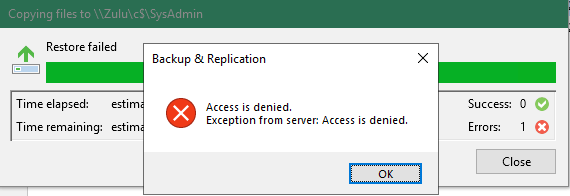
You could work around it if you use the account VBR uses to actually make the backups. But that won’t do. For one those credentials should be guarded and not use by anything or anyone but VBR. Secondly, it doesn’t work anyway.
So are you out of luck? The good news is no, you are not, so read on!
Copy the files directly from the VeeamFLR mountpoint
If you don’t have the space to restore the file locally in the secure backup environment, there is another trick. When you look at the restore log you will see what the mount server is. That is the node where you can find the C:\VeeamFLR folder, which is where the content of the virtual Machine VHDX volumes is being mounted. This means that on that node you can navigate to the folder or files you want to restore.
Select the ones you want to recover and just copy them. Navigate to restore share in the protected environment. You just need to provide the credentials of the dedicated account with write access to that share. Those are the only rights you need on that share. The copy is again fast at 230 MB/s. That is a lot better than 7MB/s.
There is an issue with this, however. In this scenario, you need access to the server where the volumes of the virtual machine get mounted. Normally that would be the local repository where the backup files reside and guess what, you lock these down as much as possible and don’t log on to them unless needed. You could specify another, but then it needs to be a server where you have access to and it copies the data over the network, which is slower. With 10Gbps or more that’s not an issue but with 1Gbps, it can take a while with a lot of large files. Can we fix this? Yes. with Mount to Console!
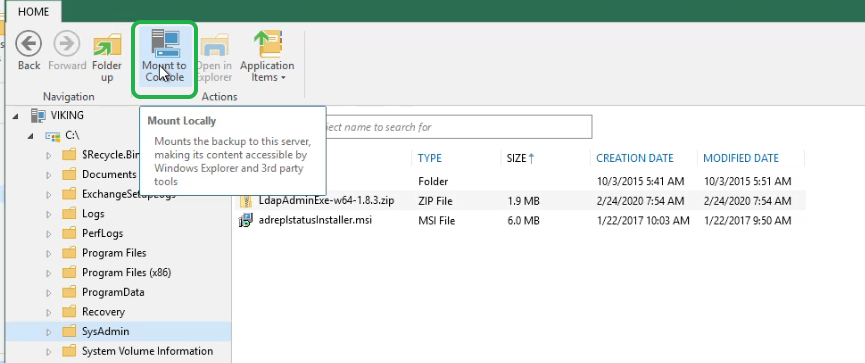
Mount to Console to the rescue
But hey, this would not be Veeam if they did not have yet another option on their sleeve! You can use the Mount to Console button on the ribbon of the Veeam Backup browser to create an extra mount point on your VBR console server. From here you can copy the files to the restore file share in the protected environment a lot faster as well. All you need for this is a local user (non-administrator account) with the Veeam Restore Operator role.
See https://helpcenter.veeam.com/docs/backup/hyperv/guest_restore_save_hv.html?ver=100 for more information on this.
The correct answer is Veeam Enterprise Manager
Veeam Enterprise Manager addresses the challenges we worked around here. But you’ll need Enterprise (plus) to get full-featured use of that. It is nice as it takes care of the above scenario and you can have restore rights assigned to people without compromising your backup environments operational security. So, yes, use Enterprise Manager when possible. If not, see the above workarounds for other options.
Conclusion
Having some insights into how Veeam Backup & Replication works can be in handy at times. It also helps if you can think a bit outside the box and act on those insights to come up with some alternatives or workarounds. This is exactly what we did here with great results. The DBA could do his restores faster while the devs have the version of the database they needed. Do note that the correct answer lies in Veeam Enterprise manager, but lacking that. You now have some options. I hope these insights into a File-Level Restore in a hardened environment help you out someday.