
Introduction
In this blog post, I will give you a script to create virtual machines for a Veeam hardened repository lab.
Some of you have asked me to do some knowledge transfer about configuring a Veeam hardened repository. For lab work virtualization is your friend. I hope to show you some of the Ubuntu Linux configurations I do. When time permits I will blog about this and you can follow along. I will share what I can on my blog.
Running the script
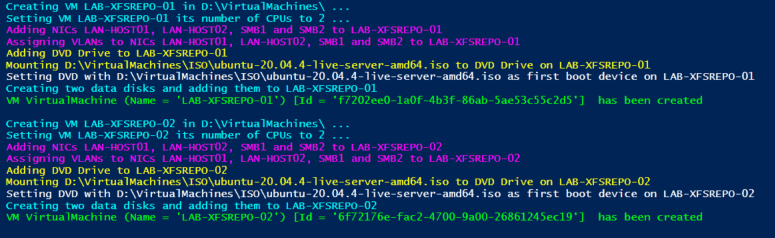
Now, if you have Hyper-V running on a lab node or on your desktop or laptop you can create virtual machines for a Veeam hardened repository lab with the PowerShell script below. Just adjust the parameters and make sure you have the Ubuntu 20.04 Server ISO in the right place. The script creates the virtual machine configuration files under a folder with the name of the virtual machine in the path you specify in the variables The VM it creates will boot into the Ubuntu setup and we can walk through it and configure it.
Pay attention to the -version of the virtual machine. I run Windows Server 2022 and Windows 11 on my PCs so you might need to adjust that to a version your Hyper-V installation supports.
Also, pay attention to the VLAN IDs used. That suits my lab network. It might not suit yours. Use VLAN ID 0 to disable the VLAN identifier on a NIC.
Clear-Host
$VMPrefix = 'AAAA-XFSREPO-0'
$Path = "D:\VirtualMachines\"
$ISOPath = 'D:\VirtualMachines\ISO\ubuntu-20.04.4-live-server-amd64.iso'
$NumberOfCPUs = 2
$Memory = 4GB
$vSwitch = 'DataWiseTech'
$NumberOfVMs = 2
$VlanIdTeam = 2
$VlanIDSMB1 = 40
$VlanIdSMB2 = 50
$VmVersion = '10.0'
ForEach ($Counter in 1..$NumberOfVMs) {
$VMName = $VMPrefix + $Counter
$DataDisk01Path = "$Path$VMName\Virtual Hard Disks\$VMName-DATA01.vhdx"
$DataDisk02Path = "$Path$VMName\Virtual Hard Disks\$VMName-DATA02.vhdx"
Write-Host -ForegroundColor Cyan "Creating VM $VMName in $Path ..."
New-VM -Name $VMName -path $Path -NewVHDPath "$Path$VMName\Virtual Hard Disks\$VMName-OS.vhdx" `
-NewVHDSizeBytes 65GB -Version 10.0 -Generation 2 -MemoryStartupBytes $Memory -SwitchName $vSwitch| out-null
Write-Host -ForegroundColor Cyan "Setting VM $VMName its number of CPUs to $NumberOfCPUs ..."
Set-VMProcessor –VMName $VMName –count 2
Write-Host -ForegroundColor Magenta "Adding NICs LAN-HOST01, LAN-HOST02, SMB1 and SMB2 to $VMName"
#Remove-VMNetworkAdapter -VMName $VMName -Name 'Network Adapter'
Rename-VMNetworkAdapter -VMName $VMName -Name 'Network Adapter' -NewName LAN-HOST-01
#Connect-VMNetworkAdapter -VMName $VMName -Name LAN -SwitchName $vSwitch
Add-VMNetworkAdapter -VMName $VMName -SwitchName DataWiseTech -Name LAN-HOST-02 -DeviceNaming On
Add-VMNetworkAdapter -VMName $VMName -SwitchName $vSwitch -Name SMB1 -DeviceNaming On
Add-VMNetworkAdapter -VMName $VMName -SwitchName $vSwitch -Name SMB2 -DeviceNaming On
Write-Host -ForegroundColor Magenta "Assigning VLANs to NICs LAN-HOST01, LAN-HOST02, SMB1 and SMB2 to $VMName"
Set-VMNetworkAdapterVlan -VMName $VMName -VMNetworkAdapterName LAN-HOST-01 -Access -VLANId $VlanIdTeam
Set-VMNetworkAdapterVlan -VMName $VMName -VMNetworkAdapterName LAN-HOST-02 -Access -VLANId $VlanIdTeam
Set-VMNetworkAdapterVlan -VMName $VMName -VMNetworkAdapterName SMB1 -Access -VLANId $VlanIdSMB1
Set-VMNetworkAdapterVlan -VMName $VMName -VMNetworkAdapterName SMB2 -Access -VLANId $VlanIdSmb2
Set-VMNetworkAdapter -VMName $VMName -Name LAN-HOST-01 -DhcpGuard On -RouterGuard On -DeviceNaming On -MacAddressSpoofing On -AllowTeaming On
Set-VMNetworkAdapter -VMName $VMName -Name LAN-HOST-02 -DhcpGuard On -RouterGuard On -MacAddressSpoofing On -AllowTeaming On
Set-VMNetworkAdapter -VMName $VMName -Name SMB1 -DhcpGuard On -RouterGuard On -MacAddressSpoofing Off -AllowTeaming off
Set-VMNetworkAdapter -VMName $VMName -Name SMB2 -DhcpGuard On -RouterGuard On -MacAddressSpoofing Off -AllowTeaming off
Write-Host -ForegroundColor yellow "Adding DVD Drive to $VMName"
Add-VMDvdDrive -VMName $VMName -ControllerNumber 0 -ControllerLocation 8
Write-Host -ForegroundColor yellow "Mounting $ISOPath to DVD Drive on $VMName"
Set-VMDvdDrive -VMName $VMName -Path $ISOPath
Write-Host -ForegroundColor White "Setting DVD with $ISOPath as first boot device on $VMName"
$DVDWithOurISO = ((Get-VMFirmware -VMName $VMName).BootOrder | Where-Object Device -like *DVD*).Device
Set-VMFirmware -VMName $VMName -FirstBootDevice $DVDWithOurISO `
-EnableSecureBoot On -SecureBootTemplate MicrosoftUEFICertificateAuthority
Write-Host -ForegroundColor Cyan "Creating two data disks and adding them to $VMName"
New-VHD -Path $DataDisk01Path -Dynamic -SizeBytes 150GB | out-null
New-VHD -Path $DataDisk02Path -Dynamic -SizeBytes 150GB | out-null
Add-VMHardDiskDrive -VMName $VMName -ControllerNumber 0 `
-ControllerLocation 1 -ControllerType SCSI -Path $DataDisk01Path
Add-VMHardDiskDrive -VMName $VMName -ControllerNumber 0 `
-ControllerLocation 2 -ControllerType SCSI -Path $DataDisk02Path
$VM = Get-VM $VMName
write-Host "VM $VM has been created" -ForegroundColor green
write-Host ""
}
Conclusion
In conclusion, that’s it for now. Play with the script and you will create virtual machines for a Veeam hardened repository lab in no time. That way you are ready to test and educate yourself. Don’t forget that you need to have sufficient resources on your host. Virtualization is cool but it is not magic.
Some of the settings won’t make sense to some of you, but during the future post, this will become clear. These are specific to Ubuntu networking on Hyper-V.
I hope to publish the steps I take in the coming months. As with many, time is my limiting factor so have patience. In the meanwhile, you read up about the Veeam hardened repository.







