
Introduction
Over the last years, I have endured some blue screens on my personal travel laptop and those of some buddies. The common factors were various types of DELL XPS laptops and seemingly random Blue Screens of Death (BSOD) with irql_not_less_or_equal. The problem and cause are however not limited to these devices or brand. The cause, I found, very often was the Intel RST driver.
Trust me, there is nothing I find more annoying than a BSOD while I’m on the move and working in a train, airplane, attending a conference or in the speaker room of conference finishing my slides. Heaven forbid it happens while I am presenting. It is always annoying, but in my home
Diagnose the problem
To fix the issue we need to stop guessing and randomly upgrading or downgrading drivers in a trial and error fashion. Diagnose the problem properly. So what does a seasoned IT Pro do? The IT Pro copies the memory dump from the system and feeds it into WinDbg (download it here).
Be sure to work on a copy of the MEMORY.DMP if you run WinDbg on the problematic machine itself to prevent any permissions issues. Open it via the “File” menu and the option “Open Crash Dump”.
Select your copy of the MEMORY.DMP file.
Let it run and have some patience as it does its work. Pretty soon you’ll see output like below.
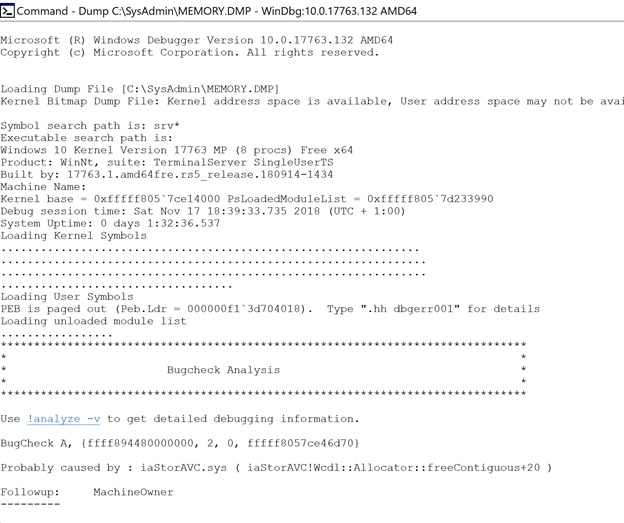
Probably caused by : iaStorAVC.sys ( iaStorAVC!Wcdl::Allocator::freeContiguous+20 )
When you run analyze -v you’ll get extra details but you already know what you need to know.
The outcome over the past years, in many (most) cases, pointed to iaStorAVC.sys more than anything else. This is the Intel Rapid Storage Technology (intel RST) driver. Your mileage may vary but I have seen the same cause on multiple XPS systems I figured I would blog it and save my future self (and maybe some of you) a ton of headaches. That said, when you get a BSOD you really must investigate the MEMORY.DMP file from that system yourself to see what driver is the culprit. But with an XPS, chances are iaStorAVC.sys is a reasonable candidate suspect. It has been a common issue over the past few years it seems.
Fine now we know what to fix. How to fix it is what we’ll look at next. I just wrote this blog for my own reference.
Fixing iaStorAVC.sys related BSOD
You have two possible approaches to fixing iaStorAVC.sys related BSODs.
- Get an updated Intel Rapid Storage Technology driver (this port)
- Move from RAID to AHCI without reinstalling
- Move from AHCI to RAID without reinstalling(handy when newer RST drivers are available and your want to test your luck).
We will look at all 3 options, staring with option 1 below.
For these operations make sure you have a (local) account with admin rights. These procedures should work with BitLocker enabled (my laptop has) but make sure you have your recovery keys at hand somewhere. Also, when using a PIN this won’t work in safe mode you know your username/password. The Barney Bear essentials for sysadmins who’ve been around the block a few times.
Get an updated Intel Rapid Storage Technology driver
This is pretty straightforward. Making sure all drivers are up to date is the 1st response to driver issues. No need to explain this in detail, just install them. If
As RAID mode is how the systems ships by default this is the easiest way to resolve the issue with DELL XPS Laptops and seemingly random Blue Screens of Death. Now if this doesn’t fix the issue or there is no newer driver to be found move on to option 2 and eventually maybe even 3. Those are other blog posts.
