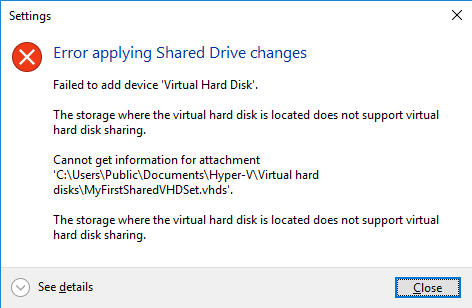
UPDATE 3: Bad and disappointing news. After update 2 we’ve seen DELL change the CSTA (CoPilot Services Technical Alert) on the customer website to “’will be fixed” in a future version. No according to the latest comment on this blog post that would be In Q1 2017. Basically this is unacceptable and it’s a shame to see a SAN that was one of the best when in comes to Hyper-V Support in Windows Server 2012 / 2012 R2 decline in this way. If 7.x is required for Windows Server 2016 Support this is pretty bad as it means early adopters are stuck or we’ll have to find an recommend another solution. This is not a good day for Dell storage.
UPDATE 2: As you can read in the comments below people are still having issues. Do NOT just update without checking everything.
UPDATE: This issue has been resolved in Storage Center 6.7.10 and 7.X
If you have 6.7.x below 6.7.10 it’s time to think about moving to 6.7.10!
No vendor is exempt form errors, issues, mistakes and trouble with advances features and unfortunately Dell Compellent has issues with Windows Server 2012 (R2) ODX in the current release of SCOS 6.7. Bar a performance issue in a 6.4 version they had very good track record in regards to ODX, UNMAP, … so far. But no matter how good your are, bad things can happen.

I’ve had to people who were bitten by it contact me. The issue is described below.
In SCOS 6.7 an issue has been determined when the ODX driver in Windows Server 2012 requests an Extended Copy between a source volume which is unknown to the Storage Center and a volume which is presented from the Storage Center. When this occurs the Storage Center does not respond with the correct ODX failure code. This results in the Windows Server 2012 not correctly recognizing that the source volume is unknown to the Storage Center. Without the failure code Windows will continually retry the same request which will fail. Due to the large number of failed requests, MPIO will mark the path as down. Performing ODX operations between Storage Center volumes will work and is not exposed to this issue.
You might think that this is not a problem as you might only use Compellent storage but think again. Local disks on the hosts where data is stored temporarily and external storage you use to transport data in and out of your datacenter, or copy backups to are all use cases we can encounter. When ODX is enabled, it is by default on Windows 2012(R2), the file system will try to use it and when that fails use normal (non ODX) operations. All of this is transparent to the users. Now MPIO will mark the Compellent path as down. Ouch. I will not risk that. Any IO between an non Compellent LUN and a Compellent LUN might cause this to happen.
The only workaround for now is to disable ODX on all your hosts. To me that’s unacceptable and I will not be upgrading to 6.7 for now. We rely on ODX to gain performance benefits at both the physical and virtual layer. We even have our SMB 3 capable clients in the branch offices leverage ODX to avoid costly data copies to our clustered Transparent Failover File Servers.
When a version arrives that fix the issue I’Il testing even more elaborate than before. We’ve come to pay attention to performance issues or data corruption with many vendors, models and releases but this MPIO issue is a new one for me.