Licensed Replay Manager Node Reports being unlicensed
I was doing a hardware refresh on a bunch of Hyper-V clusters. This meant deploying many new DELL PowerEdge R740 servers. In this scenario, we leverage SC Series SC7020 AFA arrays. These come with Replay Manager software which we use for the hardware VSS provider. On one of the replaced nodes, we ran into an annoying issue. Annoying in the fact that the licensed Replay Manager Node reports being unlicensed in the node’s application event log. The application consistent replays do work on that node. But we always get the following error in the application event log:
Product is not licensed. Use Replay Manager Explorer ‘Configure Server’ or PowerShell command ‘Add-RMLicenseInfo’ to activate product license.

On the Replay Manager Explorer, we just see that everything is fine and licensed. Via the GUI or via PowerShell we could not find a way to “re-license” an already installed server node.
What we tried but did not help
This is not a great situation the be in, therefore we need to fix it. First of all we removed the problematic node from Replay Manager explorer and tried to re-add it. That did not help to be able to relicense it. Uninstalling the service on the problematic node also did not work. Doing both didn’t fix it either. We need another approach.
The fix
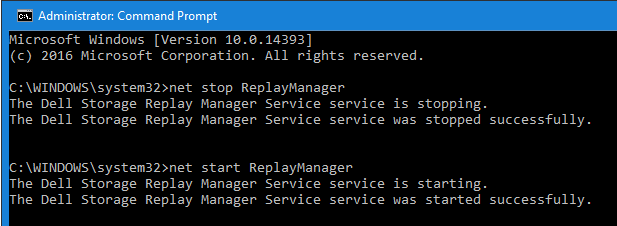
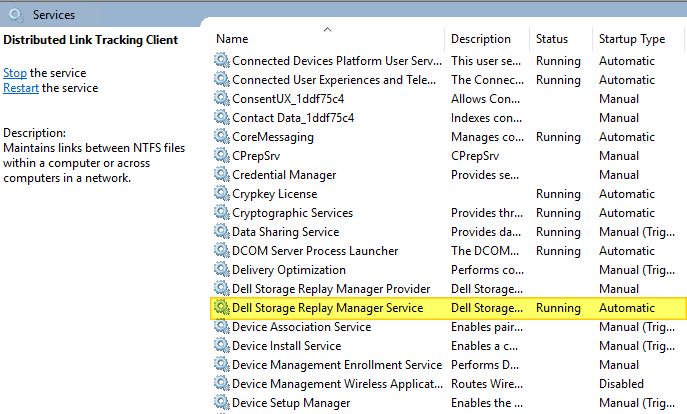
The trick to fixing the licensed Replay Manager Node reports being unlicensed is as follows. Stop the “Dell Storage Replay Manager Service” service.
Delete (or rename if you want to be careful) the Compellent folder under C:\ProgramData
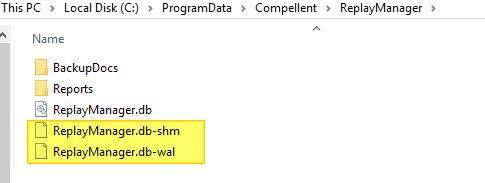
Restart the “Dell Storage Replay Manager Service” service. As a result you will see the folder and the files inside being regenerated. Wait until the temp files (ReplayManager.db-shm and ReplayManager.db-wal) of this process are gone.
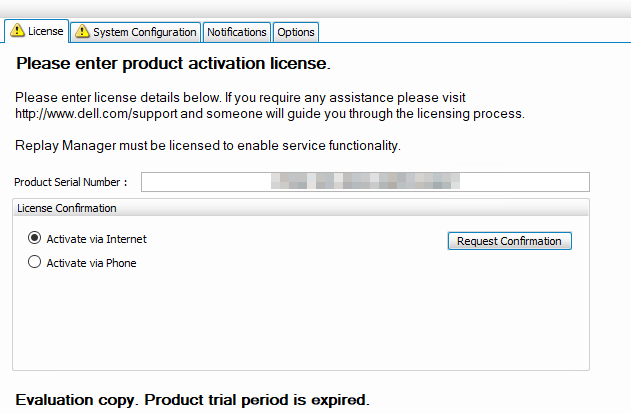
Open up Replay Manager Explorer or relaunch it for good measure if still open. Connect to the problematic node. Navigate to “Configure Server” On the license tab it reports that it is unlicensed. Now enter the license code and request confirmation (Activate via Internet) or Activate via phone.
The node is now licensed again.
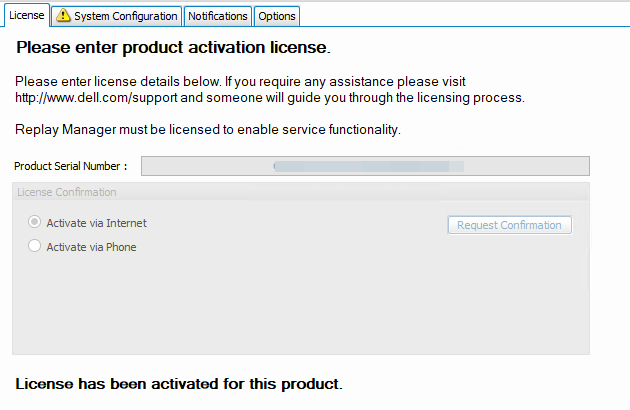
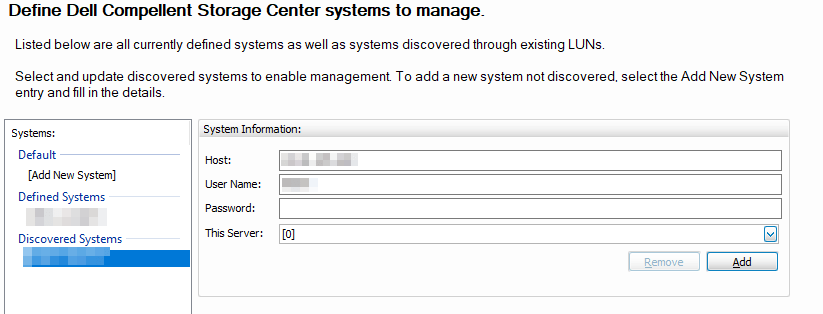
The image above shows the node is licensed again. You now need to configure the system again because that info is lost. For that, enter the username and password for your SC Arrays and add the correct node.
We now test creating a replay! Most importantly, we check the node’s application event log. The error Product is not licensed. Use Replay Manager Explorer ‘Configure Server’ or PowerShell command ‘Add-RMLicenseInfo’ to activate product license. has gone!
We only see the 3 informational entries (prepared, committed, successful) associated with a successful and completed replay.
Above all, I hope this helps others who run into this.