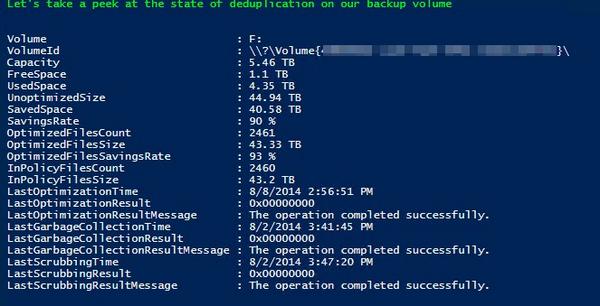
I’ve been leveraging Windows Server Data Deduplication since it became available with great results.
One of the enhanced features in Windows Server 2016 is Data Deduplication and it’s one I welcome very much. The improvements we’re getting mostly have to do with scale and performance. I’m quite pleased that Microsoft listened to our previous feedback on this.

You cannot imagine how much money on backup target storage we have saved by using this. So we’re very happy that Windows Server 2016 Data Deduplication scales and performs better. The fact that we can no get even better scale and performance is music to our ears. The Backup target servers are the first in line for an upgrade, that’s for sure! That’s the reason I mentioned it as a subject to look into in the Hyper-V amigos interview at Ignite!
Scale Improvement of the supported LUN sizes, up to 64TB
Actually I was already pushing this to 50TB  in some cases for testing but over all I used 6 to 10 TB volumes. But the support for bigger volumes is very welcome. Now, please not that you should NOT go any higher than 64TB (I actually stay below that) otherwise deduplication doesn’t work due to it’s dependency on VSS. Please read my blog
in some cases for testing but over all I used 6 to 10 TB volumes. But the support for bigger volumes is very welcome. Now, please not that you should NOT go any higher than 64TB (I actually stay below that) otherwise deduplication doesn’t work due to it’s dependency on VSS. Please read my blog
Windows 2012 R2 Data Deduplication Leverages Shadow Copies: “LastOptimizationResultMessage : A volume shadow copy could not be created or was unexpectedly deleted” on this subject.
In Windows 2012 R2 we were limited because data deduplication used a single-threaded job and I/O queue for each volume. That makes it wiser to have 10 target LUNS of 6TB than one huge 60TB LUN. The big issue otherwise is that large volumes could lead to the dedup processing keeping up with the rate of data changes (“churn”). Now your milage would very depending on the type of data and the delta. More info on this in the blog post:Sizing Volumes for Data Deduplication in Windows Server. It will help you size the volumes but note that in Windows Server 2016 the rules have changed 
The dedup optimization processing now runs multiple threads in parallel using multiple I/O queues on a single volume which gives you better performance and doesn’t incur the overhead of having to use more smaller LUNs.
File sizes up to 1TB are good for dedup
Windows Server 2012 R2 Data Deduplication supports the use of file sizes up to 1TB, but they are considered as “not good candidates” for dedup. So that DPM workaround of backing up to a truckload of virtual machines with 1TB virtual disks that are deduplicated is borderline. You can see one improvement in CPS v2 coming already (also see the next header). 1TB is now fully supported and a good candidate. I’ll be pushing it higher … in my opinion this is were the most work will need to be done for future improvements. It would allow for more scenarios (I have VMs that hold VHDX virtual disks of 2TB or more). Scale it something that helps keep things simple. Simple avoid costs & issue with complexity. That’s always a good thing if possible.
In Windows Server 2012 the algorithms can’t scale as well and performance suffers due to things like scanning for and inserting changes can slow down as the total data set increases. These processes have been redesigned in Windows Server 2016. It now uses new stream map structures and improved partial file optimization. As a result 1TB file sizes have become good candidates.
Virtualized backup is a new usage type
DPM is already leveraging deduplication of virtual machines (CPS drove that I think, see Deduplicating DPM Storage).

In Windows Server 2016 all the dedup configuration settings needed for the DPM backup scenario have been combined into a new usage type called “Backup”. This simplifies the deployment and helps “future proof” your setup as future changes can automatically be applied true this usage type.
Nano Server support
Data deduplication is (or will be) fully supported in Nano Server (new in TPv3). It’s not completely done yet so deduplication support in Nano Server still has a few restrictions:
- Support has only been validated in non-clustered configurations
- Deduplication job cancellation must be done manually (using the Stop-DedupJob PowerShell command)
Microsoft welcomes any feedback on the deduplication feature via an email sent to [email protected]. For me the standing order is to break through that 1TB barrier!
My take & Magic Ball
In combination with the right backup product it saves a ton of money. I have leveraged VEEAM and in the past Windows Backup (inbox) with great results. The benefit of these two is that you can backup to physical storage and leverage deduplication. Virtualized backup as a new usage type and makes live easier for the supported “workaround” around the limitations of DPM where normally they only support VDI for with deduplication. What I’m really curious about is another possible future usage type: “Virtual Servers” … I guess for that one deduplication support for the OS disk would be very beneficial for “cloud” providers. We’ll see











