Introduction
Before we talk about setting a static MAC address on a guest NIC team in Hyper-V. We go back to Ubuntu Linux. Do you remember my blog post about configuring an interface bond in a Ubuntu Hyper-V guest? If not, please read it as what I did there got me thinking about setting a static MAC address on a guest NIC team in Hyper-V.
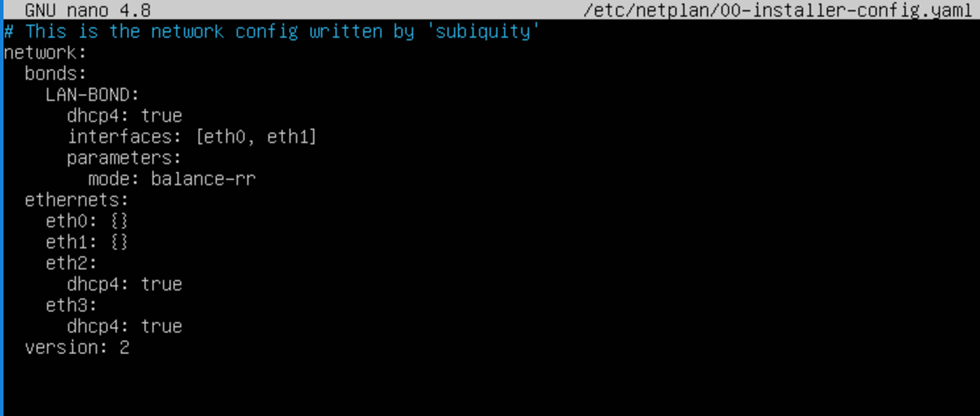
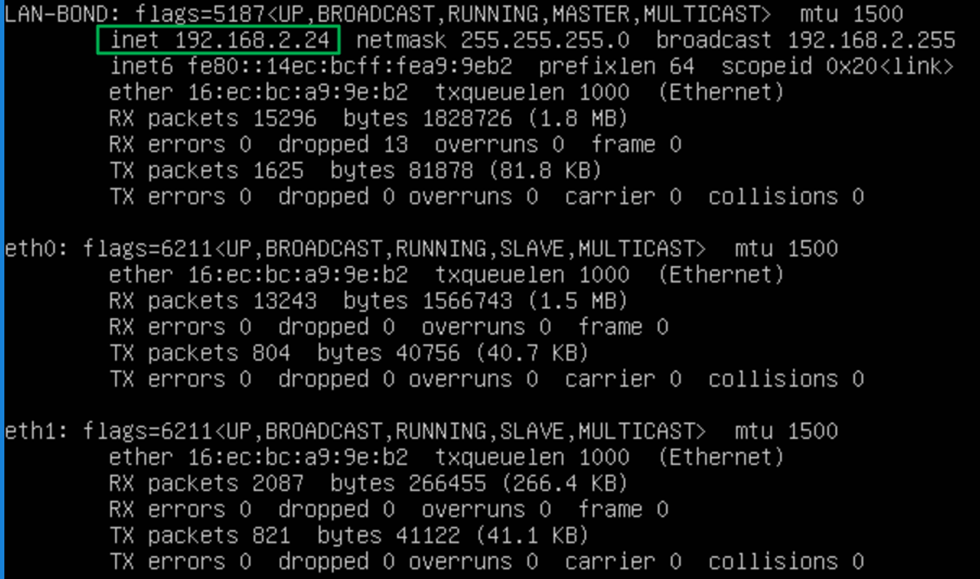
Ubuntu network bond
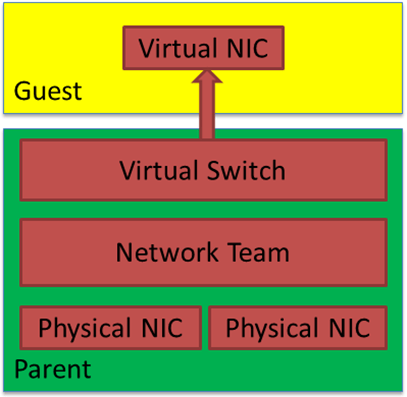
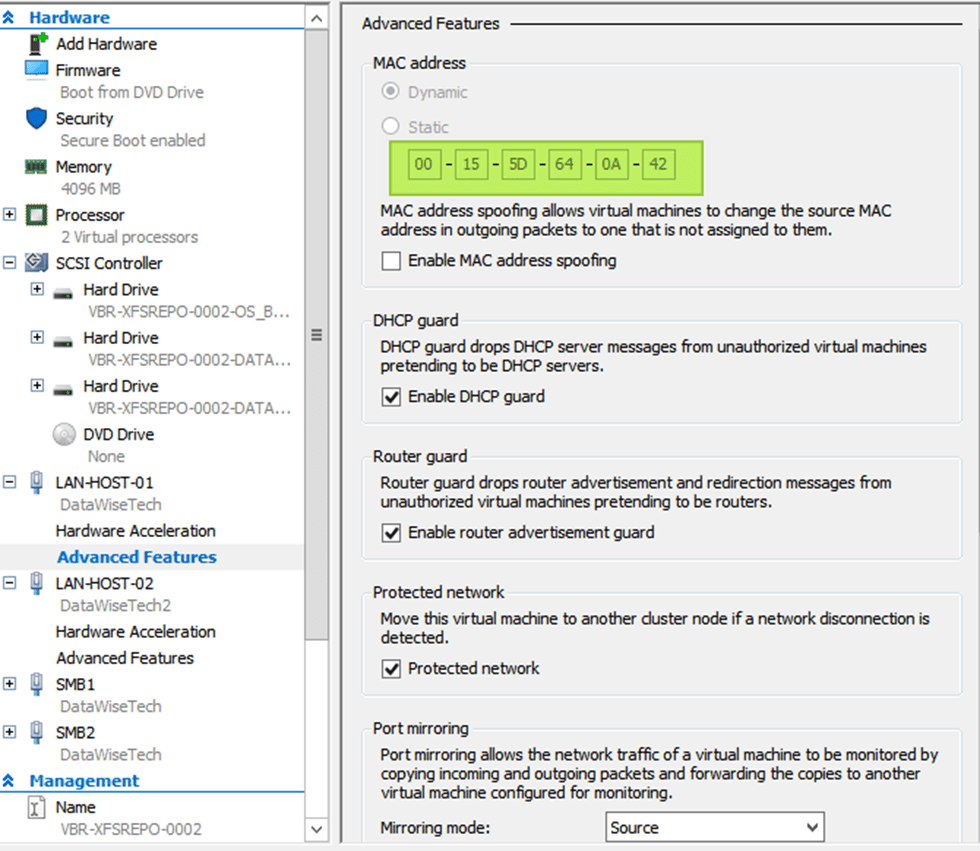
As you have read by now in the blog post I linked to above, we need to enable MAC Spoofing on both vNICs members of an interface bond in Ubuntu virtual machine on Hyper-V. Only then will you have network connectivity and are you able to get a DHCP address. On Ubuntu (or Linux in general), the bond interface has a generated MAC address assigned. It does not take one of the MAC addresses of the member vNICs. That is why we need MAC spoofing enabled on both member vNIC in the Hyper-V settings for this to work! In a Windows guest, you will find that the MAC address for the LBFO team gets one of the MAC addresses of its member vNICs assigned. As such, this does not require NIC spoofing. During failover, it will swap to the other one.
Setting a static MAC address on a guest NIC team in Hyper-V
In Ubuntu, you can set a chosen static MAC address on a bond and on the member interfaces inside the guest operating system. Would we be able to do the same with a NIC team in a Windows Server guest virtual machine? Well, yes! It sounds like a dirty hack inspired by Linux bonding, which might be way beyond anything resembling a supported configuration. But, if it is allowed for Linux, why not leverage the same technique in Windows?
Configuration walkthrough
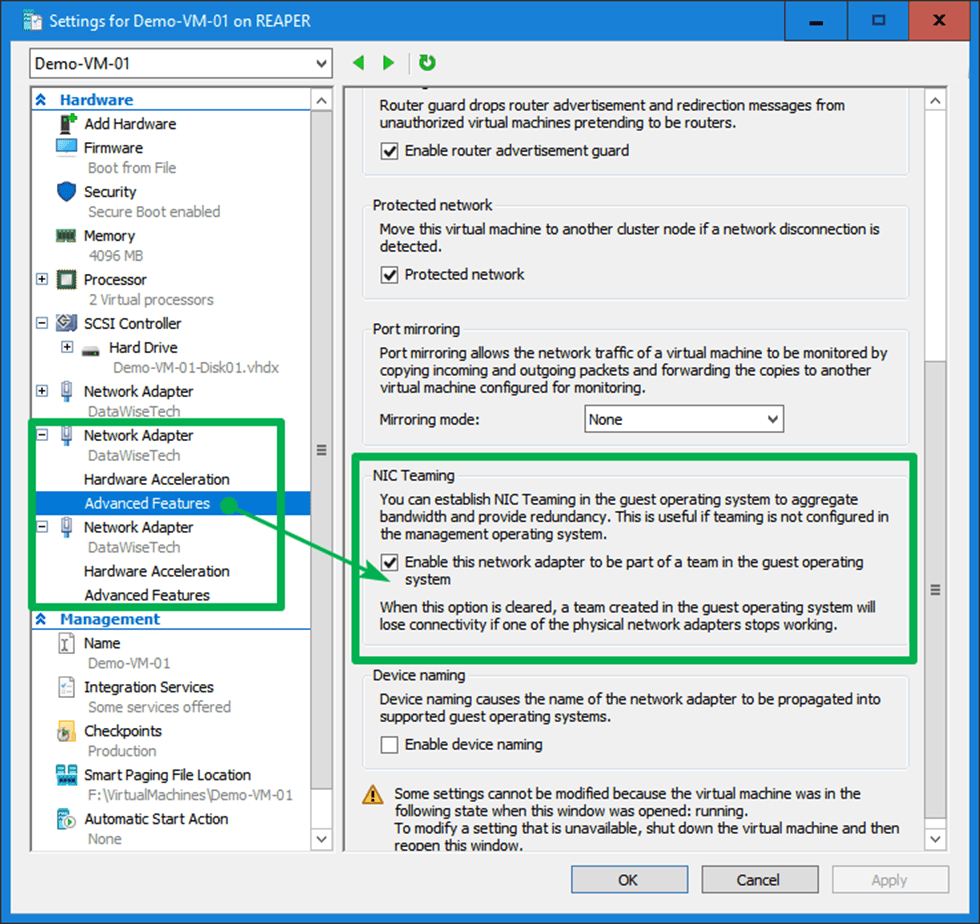
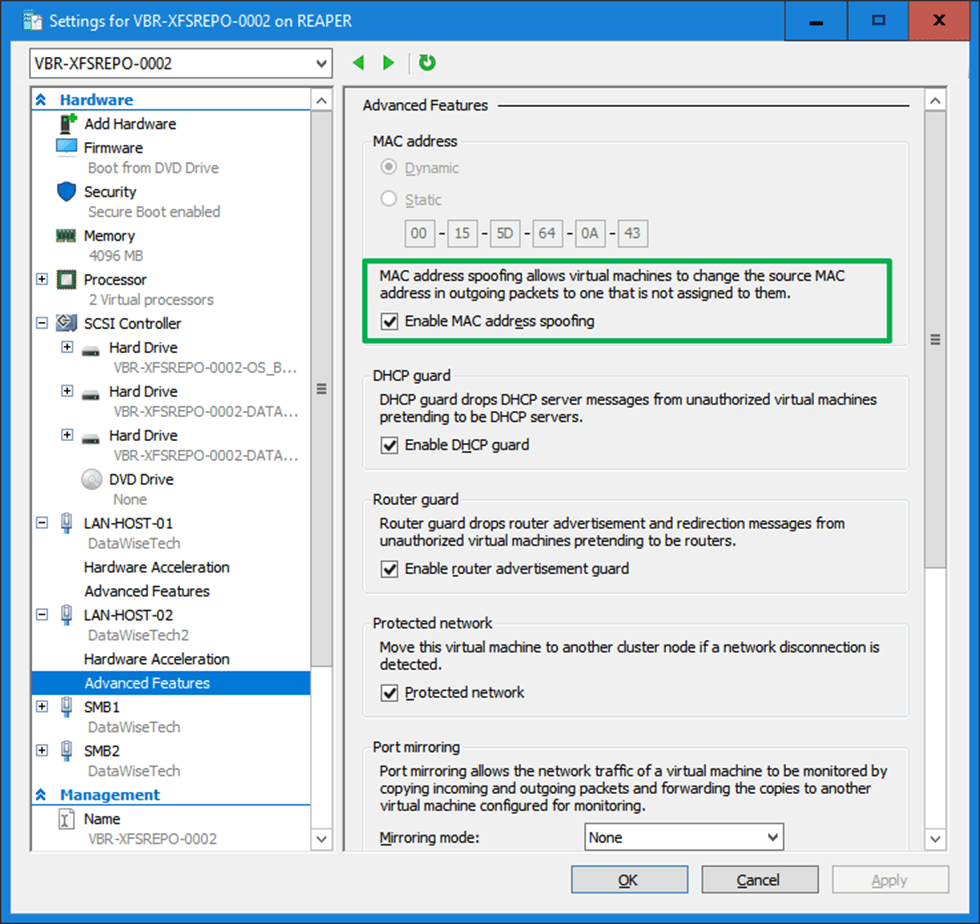
We use a mix of MAC address spoofing on the member vNICs with “enable this network adapter to be part of a team in the guest operating system” checked (not actually needed in this case) and a hardcoded MAC address on the team NIC and both member NICs inside the virtual machine. The same MAC address!
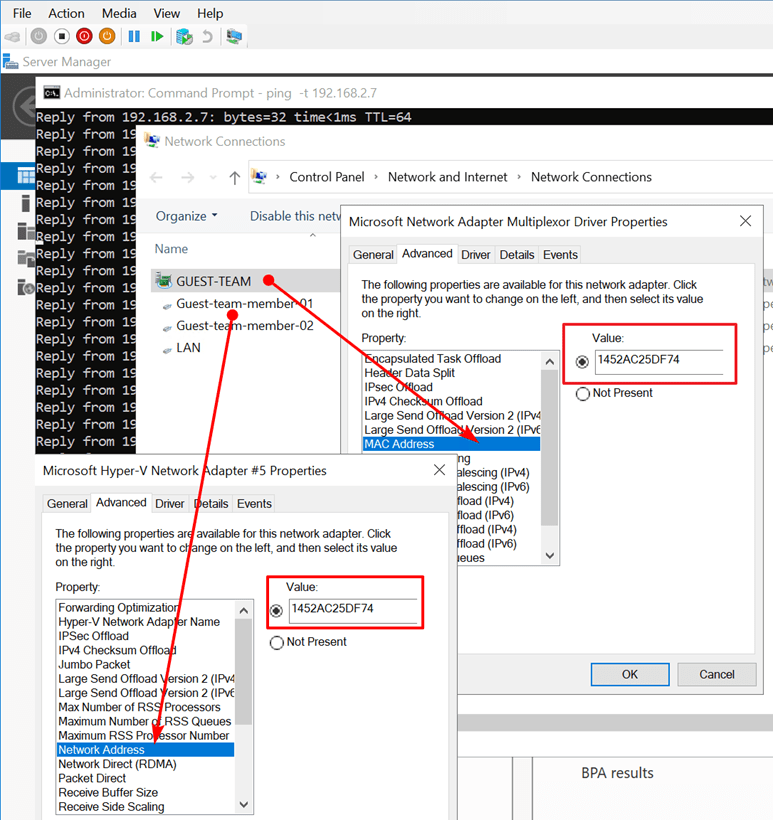
First, note the format of the MAC address. No dashes, dots, or colons. Also, that is a lot of clicking. Let’s try to do this with PowerShell. Using Set-NetAdapter throws an error to the fact that it detects the duplicate MAC address. It protects you against what it thinks is a bad idea.
$TeamName = 'GUEST-TEAM'
Set-NetAdapter -Name $TeamName -MacAddress "14-52-AC-25-DF-74"
ForEach ($MemberNic in $TeamName){
#Get-NetAdapter (Get-NetLbfoTeamMember -Team $MemberNic).Name | Format-Table
Set-NetAdapter (Get-NetLbfoTeamMember -Team $MemberNic).Name -MacAddress "14-52-AC-25-DF-74"
}
Set-NetAdapter : The network address 1452AC25DF74 is already used on a network adapter with the name ‘Guest-team-member-01’ At line:2 char:1+ Set-NetAdapter -Name $TeamName -MacAddress “14-52-AC-25-DF-74″+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~+ CategoryInfo : InvalidArgument: (MSFT_NetAdapter…wisetech.corp”):ROOT/StandardCimv2/MSFT_NetAdapter) [Set-NetAdapter], CimException + FullyQualifiedErrorId : Windows System Error 87,Set-NetAdapter
Set-NetAdapter : The network address 1452AC25DF74 is already used on a network adapter with the name ‘Guest-team-member-01’
At line:5 char:1
+ Set-NetAdapter (Get-NetLbfoTeamMember -Team $MemberNic).Name -MacAdd …
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidArgument: (MSFT_NetAdapter…wisetech.corp”):ROOT/StandardCimv2/MSFT_NetAdapter) [Set-NetAdapter], CimException
+ FullyQualifiedErrorId : Windows System Error 87,Set-NetAdapter
You need to use Set-NetAdapterAdvancedProperty. Mind you that the MAC address property for the team is called “MAC Address” and for the team member NIC “Network Address” just like in the GUI. Use the following code in the guest virtual machine.
$Team = Get-NetLbfoTeam -Name 'GUEST-TEAM'
$MACAddress = "1452AC25DF74"
$TeamName = $Team.Name
#Get-NetAdapterAdvancedProperty -Name $TeamName
Set-NetAdapterAdvancedProperty -Name $TeamName -DisplayName 'MAC Address' -DisplayValue $MACAddress
$TeamMemberNicNames = (Get-NetLbfoTeamMember -Team $TeamName).Name
foreach ($TeamMember in $TeamMemberNicNames){
#Get-NetAdapterAdvancedProperty -Name $TeamMember
Set-NetAdapterAdvancedProperty -Name $TeamMember -DisplayName 'Network Address' -DisplayValue $MACAddress
}
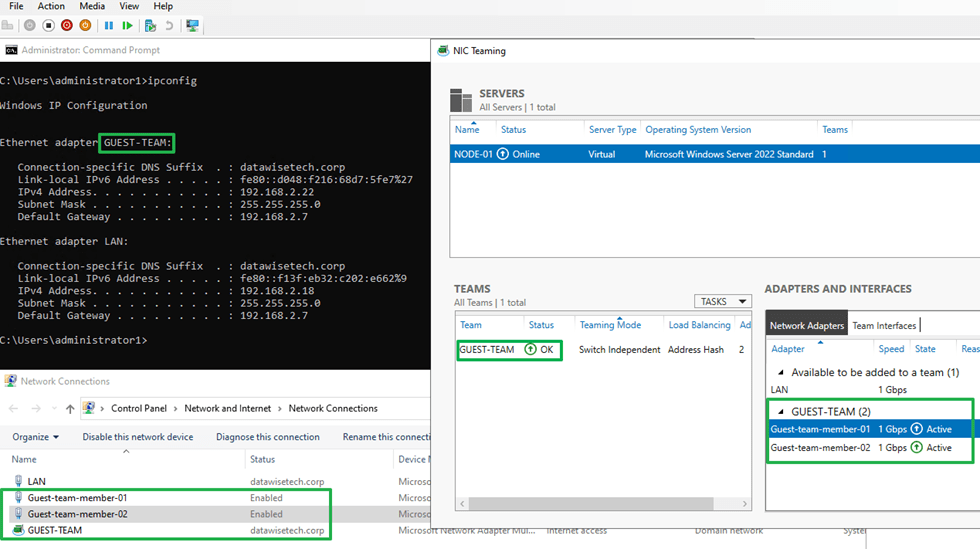
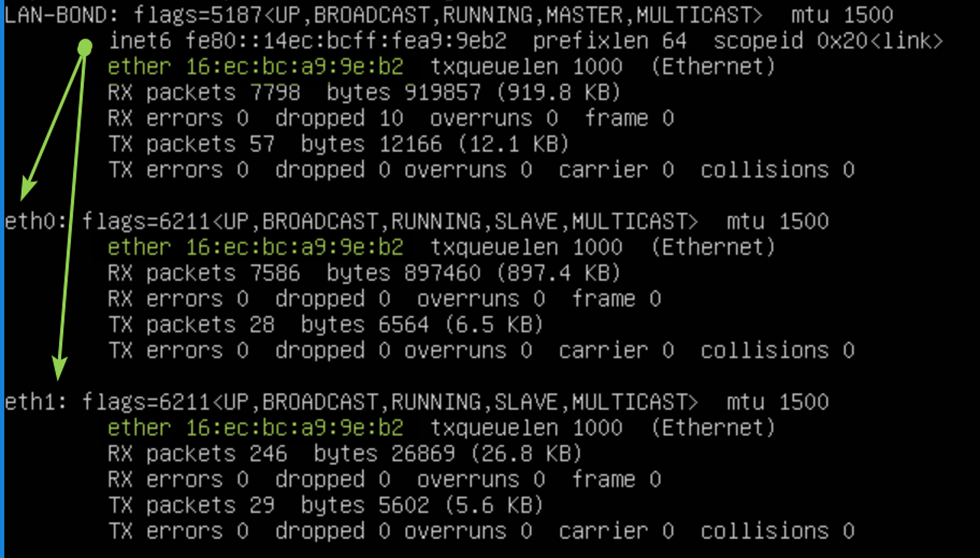
Let’s check our handy work with PowerShell

Last but not least, leave the dynamically assigned MAC addressed on the vNIC team members in Hyper-V setting but do enable MAC spoofing.
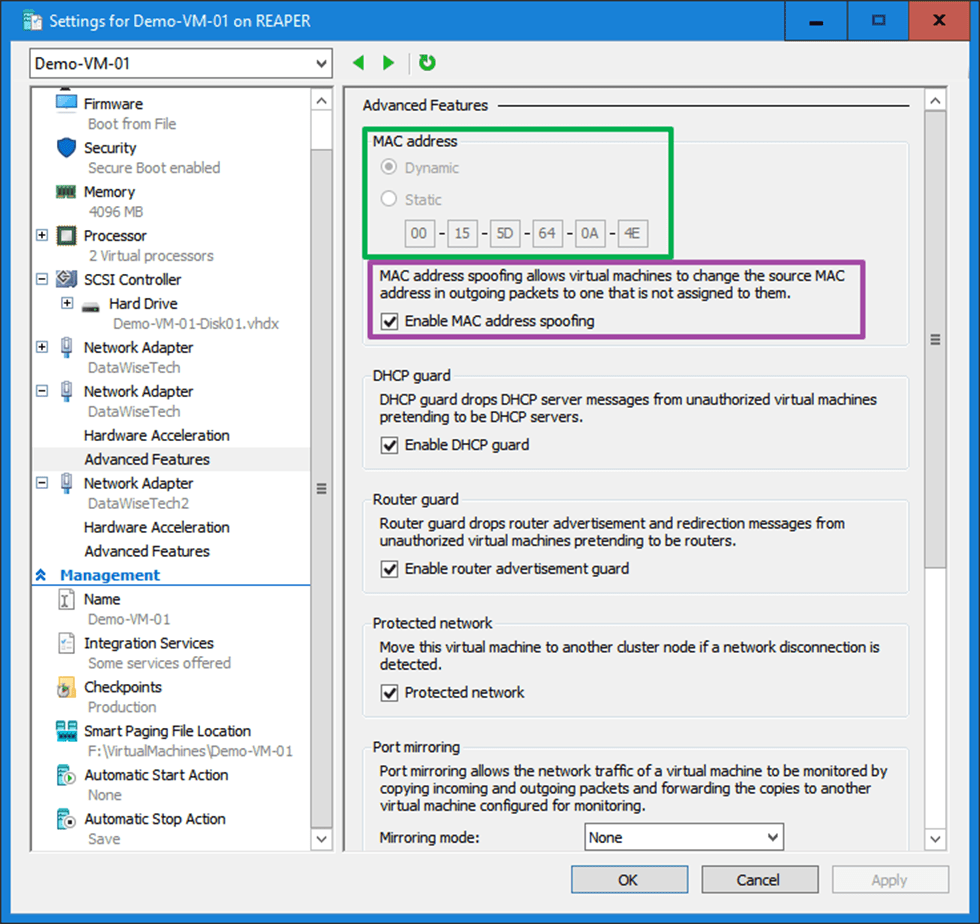
Borrowing a trick from Linux for setting a static MAC address on a guest NIC team in Hyper-V
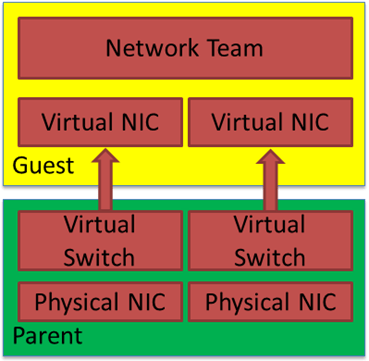
With this setup, we do not need separate switches for each member vNIC for failover to work but it is still very much advised to do so if you want real failover. First, It sounds filthy, dirty, and rotten, but for lab, demo purposes, go on, be a devil. Secondly, can you use this in production? Yes, you can. Just mind the MAC addresses you assign to avoid conflicts. Now you can tie your backward software license key that depends on a fixed MAC address to a Windows LBFO in a Hyper-V virtual machine. Why? Because we can. Finally, I would perhaps have to say that you should not do it, but Linux does, and so can windows!