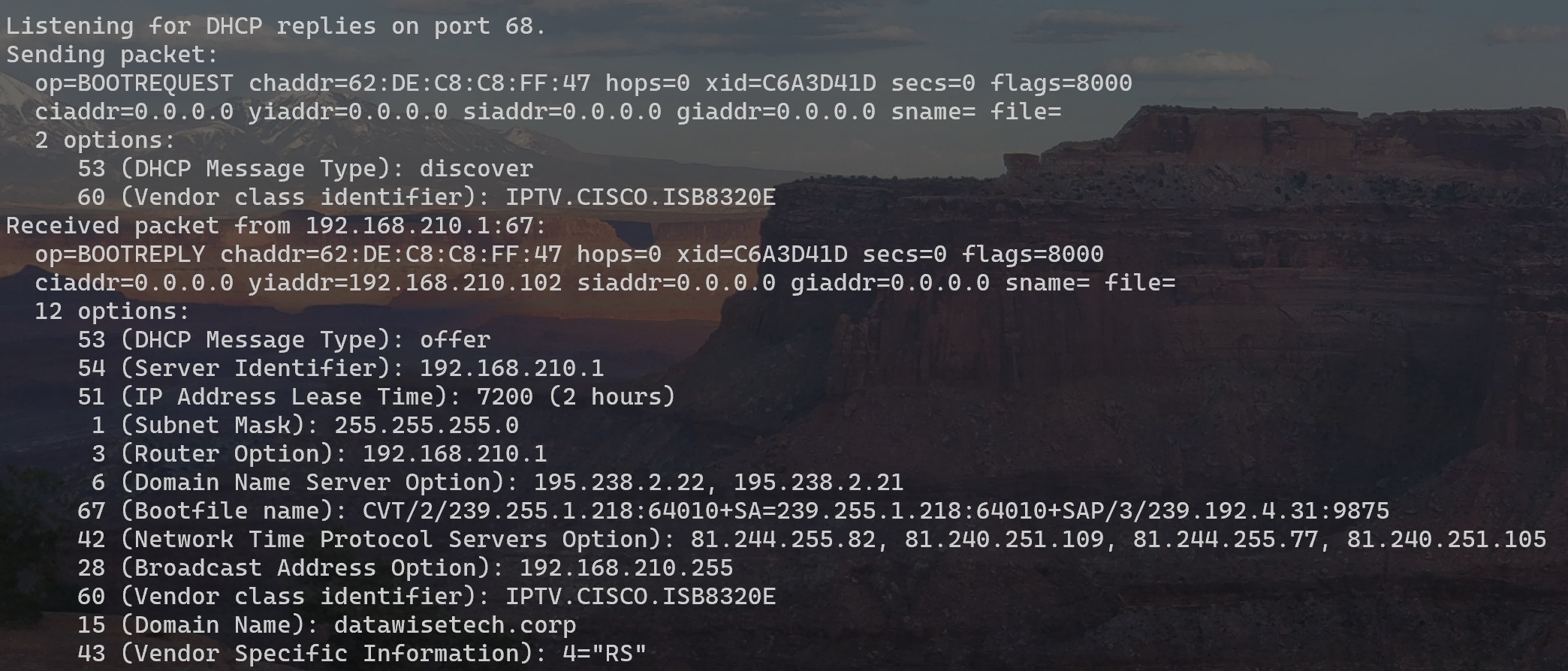
This blog serves as a Proximus IPTV decoder DHCP Options Reference. It is nothing more than an ICS DHCP .conf file to leverage in OPNsense to help tweak the configuration for Proximus (Fiber, SIngle VLAN 20) IPTV work on an OPNsense appliance (physical or virtual) instead of via the Internet Box. See DHCP — OPNsense documentation.
I still need to put in the lab time to try to convert my config to KEA DHCP, as ICS DHCP is getting a bit old.
This blog post is meant to be a reference document I can return to and add to when needed. Please feel free to add to it or correct info via the comments. I am working on more elaborate documentation explaining how you can use your 3rd party OPNsense Firewall/Router with Porximus (Internet, IPTV, and VOIP) in the single VLAN 20 setup they are now rolling out. The official documentation is a bit too vague in certain areas. Also, with so many devices, Proximus has no commercial interest in supporting them. That said, OPNsense, pfSense, Unifi, OpenWRT, DD-WRT, MicroTik, and others would cover the most popular ones and do miracles to make an ISP/telco loved instead of seen as a necessary evil. With the prices they charge, they should be able to afford and fund that effort.
Later, when “complete,” I’ll also throw this on GitHub.
Custom ICS DHCP config file Proximus Decoders
You’ll need to use your own interfaces (physical or VLAN) subnet, grab the MAC address of your decoder(s), and verify your decoder(s) hardware version (sniff it or grab it from the system Info via your TV). I got the other values for the DHCP options by capturing DHCP traffic from the decoder. Hence, this blog is my Proximus IPTV decoder DHCP Options Reference.
option space ProximusDecoderV5C;
option ProximusDecoderV5C.serviceName code 4 = text;
# This decoder works with Proximus Fiber To The Home and is the one I could test with.
# Please fill out the MAC address of your decoder. The "1" means ethernet and is not part of the MAC address.
class "ProximusDecoderV5C" {
match if (substring(hardware, 0, 7) = 1:62:de:c8:c8:ff:47 and substring(option vendor-class-identifier, 0, 19) = "IPTV.CISCO.ISB8320E");
}
# Below classes are older or newer decoders and the info I could find about them for this use case.
# You must figure it out with network captures, Wireshark, and DHCP tests.
# This is an older decoder V5 (Mini?) - Obsolete and probably does not work with Proximus Fiber To The Home
# Please fill out the MAC address of your decoder. The "1" means ethernet and is not part of the MAC address.
#I do not have access, so I could not sniff out DHCP Option 43 to find it.
class "ProximusDecoderV5" {
match if (substring(hardware, 0, 7) = 1:62:de:c8:c8:ff:48 and substring(option vendor-class-identifier, 0, 18) = "IPTV.CISCO.IPV5001");
}
# This is decoder V6- Obsolete and being replaced. Maybe due to it being Huawei? It might or might not work with Proximus Fiber To The Home.
# I do not have access, so I could not sniff out DHCP Option 43 to find it.
# Please fill out the MAC address of your decoder. The "1" means ethernet and is not part of the MAC address.
class "ProximusDecoderV6" {
match if (substring(hardware, 0, 7) = 1:62:de:c8:c8:ff:49 and substring(option vendor-class-identifier, 0, 19) = "IPTV.HUAWEI.EC6109V1");
}
#This is decoder V7. I have not had one to play with, so I am unsure of the system version. CHECK IT YOURSELF! Works with Proximus Fiber To The Home.
#I do not have access, so I could not sniff out DHCP Option 43 to find it.
#Please fill out the MAC address of your decoder. The "1" means ethernet and is not part of the MAC address.
class "ProximusDecoderV7" {
match if (substring(hardware, 0, 7) = 1:62:de:c8:c8:ff:50 and substring(option vendor-class-identifier, 0, 19) = "IPTV.TECHNICOLOR.UIW4020PXM");
}
# Anything else you might plug-in like a smart TV directly - optionally you can just refuse to lease it an address to block use by unknown devices>
# Alteratively you can filter on MAC addresses.
class "NotProximusDecoder" {
match if not (substring(option vendor-class-identifier, 0, 19) = "IPTV.CISCO.ISB8320E");
}
subnet 192.168.210.0 netmask 255.255.255.0 {
Pool{
allow members of "ProximusDecoderV5C";
range 192.168.210.101 192.168.210.111;
# Route/GW for the subnet of IPTV VLAN
option routers 192.168.210.1;
# Subnetmask for the subnet of IPTV VLAN
option subnet-mask 255.255.255.0;
# Broadcast address for the subnet of IPTV VLAN
option broadcast-address 192.168.210.255;
# Proximus STB/decoder V5c has this VCI (checked with DHCP client tool and Wireshark
option vendor-class-identifier "IPTV.CISCO.ISB8320E";
# Vendor-specific option space for IPTV
vendor-option-space ProximusDecoderV5C;
# Proximus defined IPTV specific options
option ProximusDecoderV5C.serviceName = "RS";
# Bootfile name for the device
option bootfile-name "CVT/2/239.255.1.218:64010+SA=239.255.1.218:64010+SAP/3/239.192.4.31:9875"; # Option 67
# Proximus NTP servers (Option 42)
option ntp-servers 81.244.255.82, 81.240.251.109, 81.244.255.77, 81.240.251.105;
# Proximus DNS servers (Option 6)
option domain-name-servers 195.238.2.22, 195.238.2.21;
max-lease-time 86400;
}
Pool{
allow members of "NotProximusDecoder";
range 192.168.210.201 192.168.210.211;
# Route/GW for the subnet of IPTV VLAN
option routers 192.168.210.1;
# Subnetmask for the subnet of IPTV VLAN
option subnet-mask 255.255.255.0;
# Broadcast address for the subnet of IPTV VLAN
option broadcast-address 192.168.210.255;
# Proximus NTP servers (Option 42)
option ntp-servers 81.244.255.82, 81.240.251.109, 81.244.255.77, 81.240.251.105;
# Proximus DNS servers (Option 6)
option domain-name-servers 195.238.2.22, 195.238.2.21;
max-lease-time 86400;
}
}
Why would we clear the Git commits and history from the local & remote master repository? When preparing training labs leveraging Azure DevOps and Git, I often need to do a lot of testing and experimenting to empirically get the scenarios right. That means the commit history is cluttered with irrelevant commits for the lab training I am presenting.
Ideally, I reset the history to start a training lab when the repository is at the right stage. The students are then not bothered by the commits of previous demos. But how can we clear the Git commits and history from the local & remote master repository?
Clear the Git commits and history from the local & remote master repository
Git is meant to keep the commit history, as are repositories like Azure DevOps. That means there is no way to reset the commit history in Azure DevOps. Git, being a very powerful and, to a certain extent, also a dangerous tool, can help you overcome this. But how to do it is not always obvious. That said, you can also shoot yourself in the foot with Git, so pay attention and be careful.
Step 1 to Clear the Git commits and history from the local & remote master repository
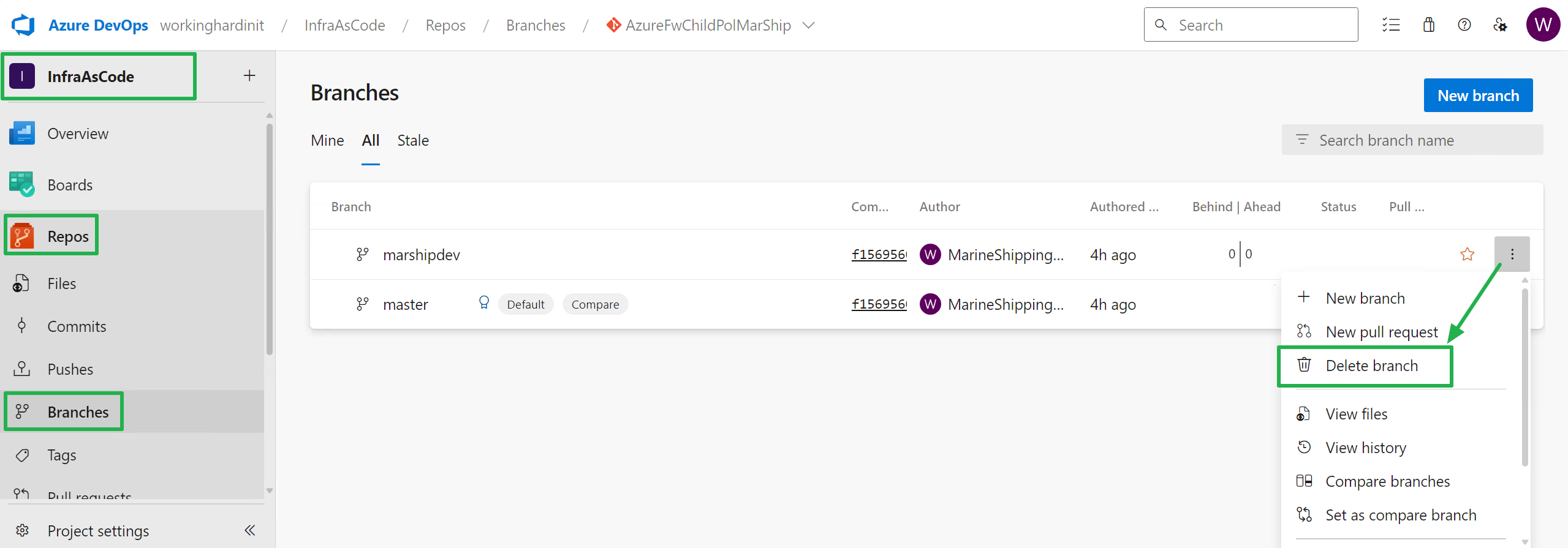
If you keep branches around things get complicated. For my needs, I don’t need them. To delete a branch via git we need three (3) deletes.
You can also delete remote branches in Azure DevOps via the GUI by selecting a branch and selecting “Delete branch” in the menu. Locally you’ll need to use Git commands or the Git GUI.
Step 2
Create a new orphaned branch
git checkout --orphan myresetbranch
The Git option –orphan creates a branch that is in a git init “like” state. That is why we have an alternative option and that is to delete the .git folder in your local repository and run git init in it. That is why i normally keep a copy around of the “perfect” situation with the .git folder removed. I can copy that to create a new local master branch by running git init. I then have that track a new remote repository that still needs initializing via:
But that is not what I am doing here, I am using another method.
Step 3
On your workstation in the local repository, make sure to clean and delete or edit and add all the files and folders we want to be in our master repository initial commit.
git add -A
git commit -m “Initial commit”
Note: we use -A here instead of “.” Because we also want to delete any tracked files and folder that are currently being tracked. At the same time, it adds new items to be tracked. In practice it is like running both git -u and git .
Step 4
Now delete the current master branch
git branch -D master
Step 5
Rename the temporary branch to “master”
git branch -m master
We now have a master repository again locally.
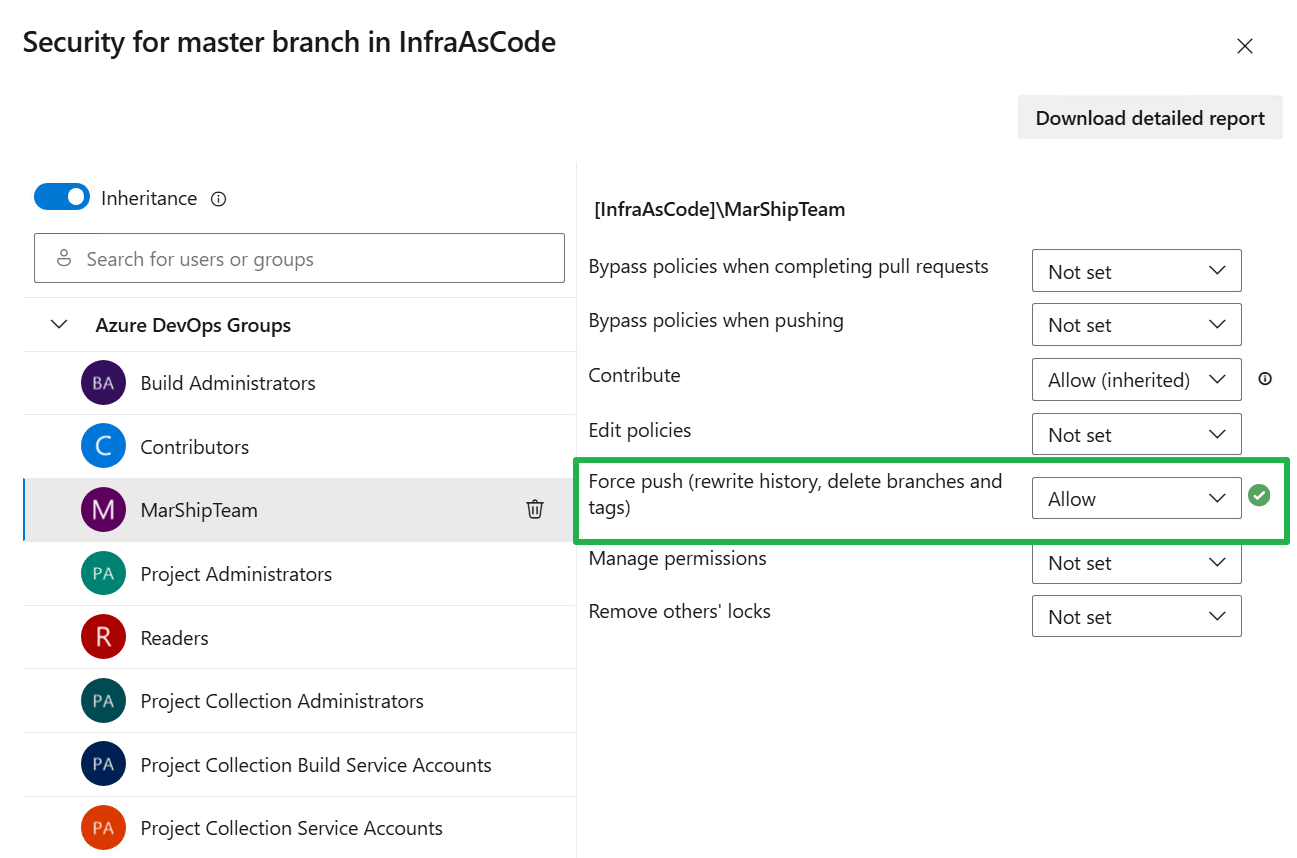
Step 6
We now need to update the remote repository with the option –force or -f. That allows us to delete branches and tags as well as rewrite the history. Normally that is no allowed so we nee to temporarily allow this in Azure DevOps.
Now we can run
git push -f origin master
If we had not allowed Force push the above command would fail with an error indicating we need to allow “Force push”. TF401027: You need the Git ‘ForcePush’ permission to perform this action.
Important: do not forget to set “Force push” back to “Not set”
Step 7 to Clear the Git commits and history from the local & remote master repository
Finally, make sure that the local master branch is set up to track origin/master.
git push --set-upstream origin master
That’s it, you now have a master repository in Azure DevOps that is ready to be cloned and used for labs with a clean commit history. Student can clone it, create branches, work on that repository and they will only see their changes and commit.
Conclusion
Resetting the git commit history of a repository is not a recommend action on production repositories under normal situations. But in situations like training lab repositories, it gives me a clean commit history to start my demos from.
Connect to an Azure VM via Bastion with native RDP using only Azure PowerShell
To connect to an Azure VM via Bastion with native RDP using only RDP requires a custom solution. By default, the user must leverage Azure CLI. It also requires the user to know the Bastion subscription and the resource ID of the virtual machine. That’s all fine for an IT Pro or developer, but it is a bit much to handle for a knowledge worker.
That is why I wanted to automate things for those users and hide that complexity away from the users. One requirement was to ensure the solution would work on a Windows Client on which the user has no administrative rights. So that is why, for those use cases, I wrote a PowerShell script that takes care of everything for an end user. Hence, we chose to leverage the Azure PowerShell modules. These can be installed for the current user without administrative rights if needed. Great idea, but that left us with two challenges to deal with. These I will discuss below.
A custom PowerShell Script
The user must have the right to connect to their Virtual Machine in Azure over the (central) bastion deployment. These are listed below. See Connect to a VM using Bastion – Windows native client for more information.
Reader role on the virtual machine.
Reader role on the NIC with private IP of the virtual machine.
Reader role on the Azure Bastion resource.
Optionally, the Virtual Machine Administrator Login or Virtual Machine User Login role
When this is OK, this script generates an RDP file for them on the desktop. That script also launches the RDP session for them, to which they need to authenticate via Azure MFA to the Bastion host and via their VM credentials to the virtual machine. The script removes the RDP files after they close the RDP session. The complete sample code can be found here on GitHub.
I don’t want to rely on Azure CLI
Microsoft uses Azure CLI to connect to an Azure VM via Bastion with native RDP. We do not control what gets installed on those clients. If an installation requires administrative rights, that can be an issue. There are tricks with Python to get Azure CLI installed for a user, but again, we are dealing with no technical profiles here.
So, is there a way to get around the requirement to use Azure CLI? Yes, there is! Let’s dive into the AZ CLI code and see what they do there. As it turns out, it is all Python! We need to dive into the extension for Bastion, and after sniffing around and wrapping my brain around it, I conclude that these lines contain the magic needed to create a PowerShell-only solution.
In PowerShell, that translates into the code below. One thing to note is that if this code is to work with PowerShell for Windows, we cannot use “keep-alive” for the connection setting. PowerShell core does support this setting. The latter is not installed by default.
# Connect & authenticate to the correct tenant and to the Bastion subscription
Connect-AzAccount -Tenant $TenantId -Subscription $BastionSubscriptionId | Out-Null
#Grab the Azure Access token
$AccessToken = (Get-AzAccessToken).Token
If (!([string]::IsNullOrEmpty($AccessToken))) {
#Grab your centralized bastion host
try {
$Bastion = Get-AzBastion -ResourceGroupName $BastionResoureGroup -Name $BastionHostName
if ($Null -ne $Bastion ) {
write-host -ForegroundColor Cyan "Connected to Bastion $($Bastion.Name)"
write-host -ForegroundColor yellow "Generating RDP file for you to desktop..."
$target_resource_id = $VmResourceId
$enable_mfa = "true" #"true"
$bastion_endpoint = $Bastion.DnsName
$resource_port = "3389"
$url = "https://$($bastion_endpoint)/api/rdpfile?resourceId=$($target_resource_id)&format=rdp&rdpport=$($resource_port)&enablerdsaad=$($enable_mfa)"
$headers = @{
"Authorization" = "Bearer $($AccessToken)"
"Accept" = "*/*"
"Accept-Encoding" = "gzip, deflate, br"
#"Connection" = "keep-alive" #keep-alive and close not supported with PoSh 5.1
"Content-Type" = "application/json"
}
$DesktopPath = [Environment]::GetFolderPath("Desktop")
$DateStamp = Get-Date -Format yyyy-MM-dd
$TimeStamp = Get-Date -Format HHmmss
$DateAndTimeStamp = $DateStamp + '@' + $TimeStamp
$RdpPathAndFileName = "$DesktopPath\$AzureVmName-$DateAndTimeStamp.rdp"
$progressPreference = 'SilentlyContinue'
}
else {
write-host -ForegroundColor Red "We could not connect to the Azure bastion host"
}
}
catch {
<#Do this if a terminating exception happens#>
}
finally {
<#Do this after the try block regardless of whether an exception occurred or not#>
}
Finding the resource id for the Azure VM by looping through subscriptions is slow
As I build a solution for a Windows client, I am not considering leveraging a tunnel connection (see Connect to a VM using Bastion – Windows native client). I “merely” want to create a functional RDP file the user can leverage to connect to an Azure VM via Bastion with native RDP.
Therefore, to make life as easy as possible for the user, we want to hide any complexity for them as much as possible. Hence, I can only expect them to know the virtual machine’s name in Azure. And if required, we can even put that in the script for them.
But no matter what, we need to find the virtual machine’s resource ID.
Azure Graph to the rescue! We can leverage the code below, and even when you have to search in hundreds of subscriptions, it is way more performant than Azure PowerShell’s Get-AzureVM, which needs to loop through all subscriptions. This leads to less waiting and a better experience for your users. The Az.ResourceGraph module can also be installed without administrative rights for the current users.
$VMToConnectTo = Search-AzGraph -Query "Resources | where type == 'microsoft.compute/virtualmachines' and name == '$AzureVmName'" -UseTenantScope
Note using -UseTenantScope, which ensures we search the entire tenant even if some filtering occurs.
Creating the RDP file to connect to an Azure Virtual Machine over the bastion host
Next, I create the RDP file via a web request, which writes the result to a file on the desktop from where we launch it, and the user can authenticate to the bastion host (with MFA) and then to the virtual machine with the appropriate credentials.
try {
$progressPreference = 'SilentlyContinue'
Invoke-WebRequest $url -Method Get -Headers $headers -OutFile $RdpPathAndFileName -UseBasicParsing
$progressPreference = 'Continue'
if (Test-Path $RdpPathAndFileName -PathType leaf) {
Start-Process $RdpPathAndFileName -Wait
write-host -ForegroundColor magenta "Deleting the RDP file after use."
Remove-Item $RdpPathAndFileName
write-host -ForegroundColor magenta "Deleted $RdpPathAndFileName."
}
else {
write-host -ForegroundColor Red "The RDP file was not found on your desktop and, hence, could not be deleted."
}
}
catch {
write-host -ForegroundColor Red "An error occurred during the creation of the RDP file."
$Error[0]
}
finally {
$progressPreference = 'Continue'
}
Finally, when the user is done, the file is deleted. A new one will be created the next time the script is run. This protects against stale tokens and such.
Pretty it up for the user
I create a shortcut and rename it to something sensible for the user. Next, I changed the icon to the provided one, which helps visually identify the shortcut from any other Powershell script shortcut. They can copy that shortcut wherever suits them or pin it to the taskbar.
I recently wrote a 3 part series (see part 1, part 2, and part 3) about setting up site-to-site VPNs to Azure using an OPNsense router/firewall appliance. That made me realize some of you would like to learn more about deploying an OPNsense/pfSense Hyper-V virtual machine in your lab or production. In this blog post, using PowerShell, I will start by showing you how to deploy one or more virtual machines that are near perfect to test out a multitude of scenarios with OPNsense. It is really that easy.
Hyper-V virtual switches
I have several virtual switches on my Hyper-V host (or hosts if you are clustering in your lab). One is for connections to my ISP, and the other is for management, which can be (simulated) out-of-band (OOB) or not; that is up to you. Finally, you’ll want one for your workload’s networking needs. In the lab, you can forgo teaming (SET or even classic native teaming) and do whatever suits your capabilities and /or needs.
I can access more production-grade storage, server, and network hardware (DELL, Lenovo, Mellanox/Nvidia) for serious server room or data center work via befriended MVPs and community supporters. So that is where that test work happens.
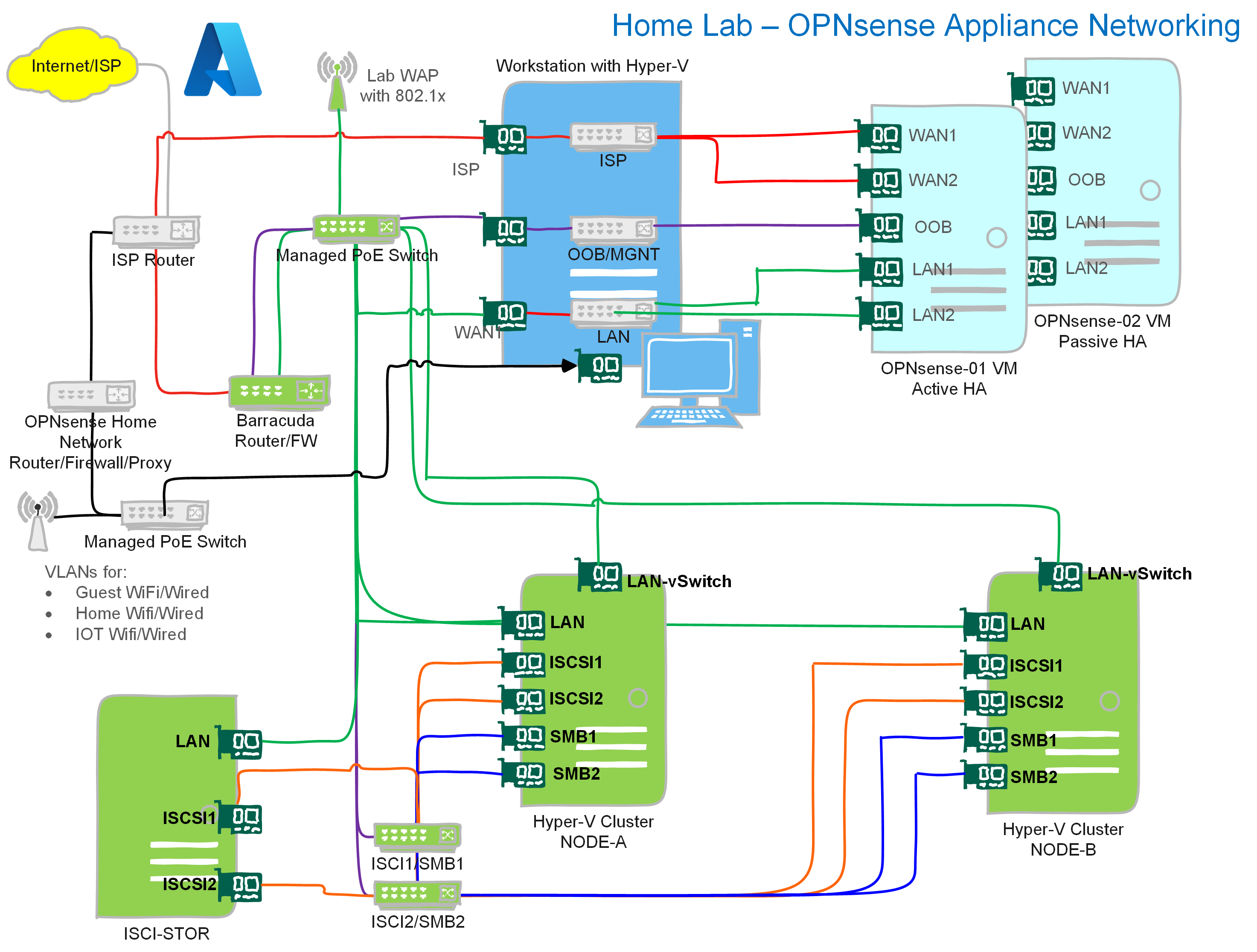
Images speak louder than a thousand words
Let’s add some images to help you orient your focus on what we are doing. The overview below gives you an idea about the home lab I run. I acquired the network gear through dumpster diving and scavenging around for discards and gifts from befriended companies. The focus is on the required functionality without running up a ridiculous power bill and minimizing noise. The computing hardware is PC-based and actually quite old. I don’t make a truckload of money and try to reduce my CO2 footprint. If you want $$$, you are better in BS roles, and there, expert technical knowledge is only a hindrance.
The grey parts are the permanently running devices. These are one ISP router and what the rest of the home network requires. An OPNsense firewall, some Unifi WAPs, and a managed PoE switch. That provides my workstation with a network for Internet access. It also caters to my IoT, WiFi, and home networking needs, which are unimportant here.
The lab’s green part can be shut down unless I need it for lab scenarios, demos, or learning. Again this saves on the electricity bill and noise.
The blue part of the network is my main workstation and about 28 virtual machines that are not all running. I fire those up when needed. And we’ll focus on this part for the OPNsense needs. What is not shown but which is very important as a Veeam Vanguard is the Veeam Backup & Replication / Veeam ONE part of the lab. That is where I design and test my “radical resilience” Veeam designs.
Flexibility is key
On my stand-alone Hyper-V workstation, I have my daily workhorse and a small data center running all in one box. That helps keep costs down and means that bar the ISP router and permanent home network, I can shut down and cut power to the Barracuda appliance, all switches, the Hyper-V cluster nodes, and the ISCSI storage server when I don’t need them.
If you don’t have those parts in your lab, you need fewer NIC ports in the workstation. You can make the OOB and the LAN vSwitch internal or private, as traffic does not need to leave the host. In that case, one NIC port for your workstation and one for the ISP router will suffice. If you don’t get a public IP from your ISP, you can use a NIC port for an external vSwitch shared with your host.
This gives me a lot of flexibility, and I have chosen to integrate my workstation data center with my hardware components for storage and Hyper-V clustering.
Even with a laptop or a PC with one NIC, you can use the script I share here using internal or private virtual switches. As long as you stay on your host, that will do, with certain limitations of cause.
Three virtual switches
OOB-MGNT: This is attached to a subnet that serves no purpose other than to provide an IP to manage network devices. Appliances like the Kemp Loadmasters, the OPNsense/pfSense/VyOS appliances, physical devices like the switches, the Barracuda firewall, the home router, and other temporary network appliances. It does not participate in any configuration for high availability or in carrying data.
ISP-WAN: This vSwitch has an uplink to the ISP router. Virtual machines attached to it can get a DHCP address from that ISP router, providing internet access over NAT. Alternatively, you can configure it to receive a public IP address from your ISP via DHCP (Cable) or PPoE (VDSL). With some luck, your ISP hands out more than just one. If so, you can test BGP-based dynamic routing with a site-to-site VPN from OPNsense and Azure VWAN.
LAN: The LAN switch is for carrying configuration and workload data. For standard use virtual machines, we configure the VLAN tag on the vNIC settings in the portal or via PowerShell. But network appliances must be able to carry all VLAN traffic. That is why we configure the virtual NICs of the LAN in trunk mode and set the list of allowed VLANs it may carry.
PowerShell script for deploying an OPNsense/pfSense Hyper-V virtual machine
Change the parameters in the below PowerShell function. Call it by running CreateAppliance. You can parameterize the function at will and leverage it however you see fit. This is just to give you an idea of how to do it and how I configure the settings for the appliance(s).
function CreateAppliance() {
Clear-Host
$Title = @"
___ _ _ _ _ _ _
/ \___ _ __ | | ___ _ _ /\ /(_)_ __| |_ _ _ __ _| | /\/\ __ _ ___| |__ (_)_ __ ___
/ /\ / _ \ '_ \| |/ _ \| | | | \ \ / / | '__| __| | | |/ _` | | / \ / _` |/ __| '_ \| | '_ \ / _ \
/ /_// __/ |_) | | (_) | |_| | \ V /| | | | |_| |_| | (_| | | / /\/\ \ (_| | (__| | | | | | | | __/
/___,' \___| .__/|_|\___/ \__, | \_/ |_|_| \__|\__,_|\__,_|_| \/ \/\__,_|\___|_| |_|_|_| |_|\___|
|_| |___/
__ ___ ___ __ __ __ __
/ _| ___ _ __ /___\/ _ \/\ \ \___ ___ _ __ ___ ___ / / __ / _/ _\ ___ _ __ ___ ___
| |_ / _ \| '__| // // /_)/ \/ / __|/ _ \ '_ \/ __|/ _ \ / / '_ \| |_\ \ / _ \ '_ \/ __|/ _ \
| _| (_) | | / \_// ___/ /\ /\__ \ __/ | | \__ \ __// /| |_) | _|\ \ __/ | | \__ \ __/
|_| \___/|_| \___/\/ \_\ \/ |___/\___|_| |_|___/\___/_/ | .__/|_| \__/\___|_| |_|___/\___|
|_|
"@
Write-Host -ForegroundColor Green $Title
filter timestamp { "$(Get-Date -Format "yyyy/MM/dd hh:mm:ss"): $_" }
VMPrefix $= 'OPNsense-0'
$Path = "D:\VirtualMachines\"
$ISOPath = 'D:\VirtualMachines\ISO\OPNsense-23.7-vga-amd64.iso'
#$ISOPath = 'C:\VirtualMachines\ISO\pfSense-CE-2.7.1-RELEASE-amd64.iso'
$ISOFile = Split-Path $ISOPath -leaf
$NumberOfCPUs = 2
$Memory = 4GB
$NumberOfVMs = 1 # Handy to create a high available pair or multiple test platforms
$VMGeneration = 2 # If an apliance supports generation 2, choose this, always! OPNsense, pfSense, Vyos support this.
$VmVersion = '10.0' #If you need this VM yo run on older HYper-V hosts choose the version accordingly
#vSwitches
$SwitchISP = 'ISP-WAN' #This external vSwitch is connected to the NIC towards ISP router. Not shared with the hyper-V Host
$SwitchOOBMGNT = 'OOB-MGNT' #This can be a private/internal netwwork or an external one, possibly shared with the host.
$SwitchLAN = 'LAN' #This can be a private/internal netwwork or an external one, possibly shared with the host.
#vNICs and if applicable their special configuration.
$WAN1 = 'WAN1'
$WAN2 = 'WAN1'
$OOBorMGNT = 'OOB'
$LAN1 = 'LAN1'
$LAN1TrunkList = "1-2048"
$LAN2 = 'LAN2'
$LAN2TrunkList = "1-2048"
write-host -ForegroundColor green -Object ("Starting deployment of your appliance(s)." | timestamp)
ForEach ($Counter in 1..$NumberOfVMs) {
$VMName = $VMPrefix + 1
try {
Get-VM -Name $VMName -ErrorAction Stop | Out-Null
Write-Host -ForegroundColor red ("The machine $VMName already exists. We are not creating it" | timestamp)
exit
}
catch {
$NewVhdPath = "$Path\$VMName\Virtual Hard Disks\$VMName-OS.vhdx"
If ( Test-Path -Path $NewVhdPath) {
Write-host ("$NewVhdPath allready exists. Clean this up or specify a new location to create the VM." | timestamp)
}
else {
Write-Host -ForegroundColor Cyan ("Creating VM $VMName in $Path ..." | timestamp)
New-VM -Name $VMName -path $Path -NewVHDPath $NewVhdPath
-NewVHDSizeBytes 64GB -Version $VmVersion -Generation $VMGeneration -MemoryStartupBytes $Memory | out-null
Write-Host -ForegroundColor Cyan ("Setting VM $VMName its number of CPUs to $NumberOfCPUs ..." | timestamp)
Set-VMProcessor –VMName $VMName –count 2
#Get rid of the default network adapter -renaning would also be an option
Remove-VMNetworkAdapter -VMName $VMName -Name 'Network Adapter'
Write-Host -ForegroundColor Magenta ("Adding Interfaces WAN1, WAN2, OOBMGNT, LAN1 & LAN2 to $VMName" | timestamp)
write-host -ForegroundColor yellow -Object ("Creating $WAN1 Interface" | timestamp)
#For first ISP uplink
Add-VMNetworkAdapter -VMName $vmName -Name $WAN1 -SwitchName $SwitchISP
write-host -ForegroundColor green -Object ("Created $WAN1 Interface succesfully" | timestamp)
write-host -ForegroundColor yellow -Object ("Creating $WAN2 Interface" | timestamp)
#For second ISP uplink
Add-VMNetworkAdapter -VMName $vmName -Name $WAN2 -SwitchName $SwitchISP
write-host -ForegroundColor green -Object ("Created $WAN2 Interface succesfully" | timestamp)
write-host -ForegroundColor yellow -Object ("Creating $OOBorMGNT Interface" | timestamp)
#Management Interface - This can be OOB if you want. Do note by default the appliance route to this interface.
Add-VMNetworkAdapter -VMName $vmName -Name $OOBorMGNT -SwitchName $SwitchOOBMGNT #For management network (LAN in OPNsense terminology - rename it there to OOB or MGNT as well - I don't use a workload network for this)
write-host -ForegroundColor green -Object ("Created $OOBorMGNT Interface succesfully" | timestamp)
write-host -ForegroundColor yellow -Object ("Creating $LAN1 Interface" | timestamp)
#For workload network (for the actual network traffic of the VMs.)
Add-VMNetworkAdapter -VMName $vmName -Name $LAN1 -SwitchName $SwitchLAN
write-host -ForegroundColor green -Object ("Created $LAN1 Interface succesfully" | timestamp)
write-host -ForegroundColor yellow -Object ("Creating $LAN2 Interface" | timestamp)
#For workload network (for the actual network traffic of the VMs. he second one is optional but useful in labs scenarios.)
Add-VMNetworkAdapter -VMName $vmName -Name $LAN2 -SwitchName $SwitchLAN
write-host -ForegroundColor green -Object ("Created $LAN2 Interface succesfully" | timestamp)
Write-Host -ForegroundColor Magenta ("Setting custom configuration top the Interface (trunking, allowed VLANs, native VLAN ..." | timestamp)
#Allow all VLAN IDs we have in use on the LAN interfaces of the firewall/router. The actual config of VLANs happens on the appliance.
write-host -ForegroundColor yellow -Object ("Set $LAN1 Interface to Trunk mode and allow VLANs $LAN1TrunkList with native VLAN = 0" | timestamp)
Set-VMNetworkAdapterVlan -VMName $vmName -VMNetworkAdapterName $LAN1 -Trunk -AllowedVlanIdList $LAN1TrunkList -NativeVlanId 0
write-host -ForegroundColor green -Object ("The $LAN1 Interface is now in Trunk mode and allows VLANs $LAN1TrunkList with native VLAN = 0" | timestamp)
write-host -ForegroundColor yellow -Object ("Set $LAN2 Interface to Trunk mode and allow VLANs $LAN2TrunkList with native VLAN = 0" | timestamp)
Set-VMNetworkAdapterVlan -VMName $vmName -VMNetworkAdapterName $LAN2 -Trunk -AllowedVlanIdList $LAN2TrunkList -NativeVlanId 0
write-host -ForegroundColor green -Object ("The $LAN2 Interface is now in Trunk mode and allows VLANs $LAN2TrunkList with native VLAN = 0" | timestamp)
Write-Host -ForegroundColor Magenta ("Adding DVD Drive, mounting appliance ISO, setting it to boot first" | timestamp)
Write-Host -ForegroundColor yellow ("Adding DVD Drive to $VMName" | timestamp)
Add-VMDvdDrive -VMName $VMName -ControllerNumber 0 -ControllerLocation 8
write-host -ForegroundColor green -Object ("Succesfully addded the DVD Drive." | timestamp)
Write-Host -ForegroundColor yellow ("Mounting $ISOPath to DVD Drive on $VMName" | timestamp)
Set-VMDvdDrive -VMName $VMName -Path $ISOPath
write-host -ForegroundColor green -Object ("Mounted $ISOFile." | timestamp)
Write-Host -ForegroundColor yellow ("Setting DVD with $ISOPath as first boot device on $VMName and disabling secure boot" | timestamp)
$DVDWithOurISO = ((Get-VMFirmware -VMName $VMName).BootOrder | Where-Object Device -like *DVD*).Device
#I am optimistic and set the secure boot template to what it most likely will be if they ever support it :-)
Set-VMFirmware -VMName $VMName -FirstBootDevice $DVDWithOurISO `
-EnableSecureBoot Off -SecureBootTemplate MicrosoftUEFICertificateAuthority
write-host -ForegroundColor green -Object ("Set vDVD with as the first boot device and disabled secure boot." | timestamp)
$VM = Get-VM $VMName
write-Host -ForegroundColor Cyan ("Virtual machine $VM has been created." | timestamp)
}
}
}
write-Host -ForegroundColor Green "+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++"
write-Host -ForegroundColor Green "You have created $NumberOfVMs virtual appliance(s) with each two WAN ports, a Management port and
two LAN ports. The chosen appliance ISO is loaded in the DVD as primary boot device, ready to install."
write-Host -ForegroundColor Green "+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++"
}
#Run by calling
CreateAppliance
Conclusion
Deploying an OPNsense/pfSense Hyper-V virtual machine is easy. You can have one or more of them up and running in less seconds. For starters, it will take longer to download the ISOs for installing OPNsense or pfSense than to create the virtual machine.
Finally, the virtual machine configuration allows for many lab scenarios, demos, and designs. As such, they provide your lab with all the capabilities and flexibilities you need for learning, testing, validating designs, and troubleshooting.