Introduction
Without any doubt, I find the hardened Linux repository Veeam introduces in Veeam Backup & Replication v11 one of the most fascinating new features to get my hands on. In the ever-escalating battle with ransomware and wipers, this is a very valuable option to have in your defensive arsenal. So, I grabbed the Beta 2 and got to work in the lab over the holidays to investigate and find out some details about the Immutability of Linux files on the Veeam hardened Linux repository.
Immutability of Linux files on the Veeam hardened Linux repository
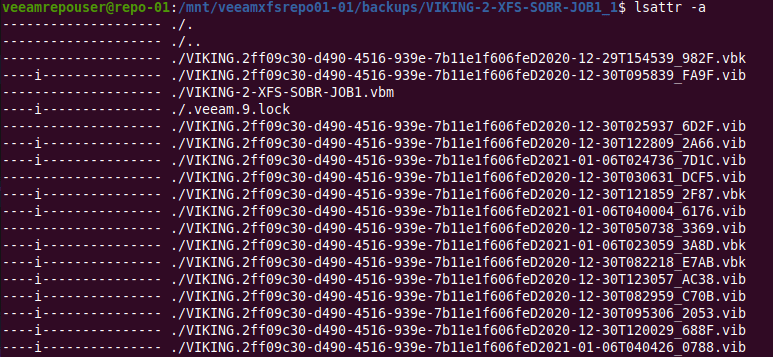
It’s quite easy to find the file attribute “i” that marks a file as immutable.
lsattr -a
or
lsattr -a -l
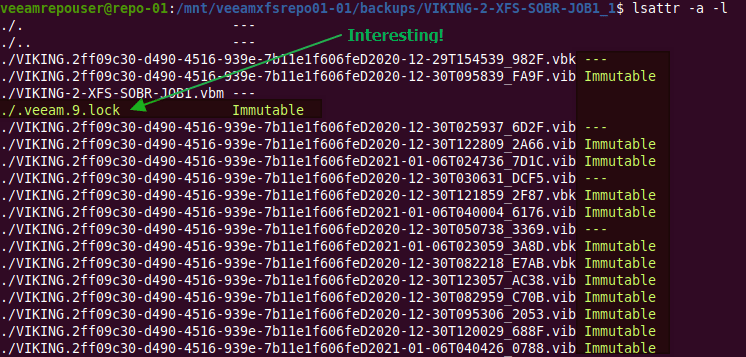
Where is the information about the immutability actually stored? I mean, that “i” attribute is one thing but how do the Linux host and Veeam know from what time period this immutability is valid. In the end, the service has to clear it and know when to do this. Or is this only stored in the Veeam database or both?
How does it now from when till when a file must be immutable?
Digging around in the files and folders of the Veeam repository, I soon found the lock file “.veeam.x.lock” (see the green arrow in the image above) that is created by the veeamimmureposvc service. The owner is root, hence it is not created by the Veeam transport service. The veeamimmureposvc service is a local account with root access for managing the immutability. It only works locally and does not listen on any network port, hence it cannot be accessed remotely.
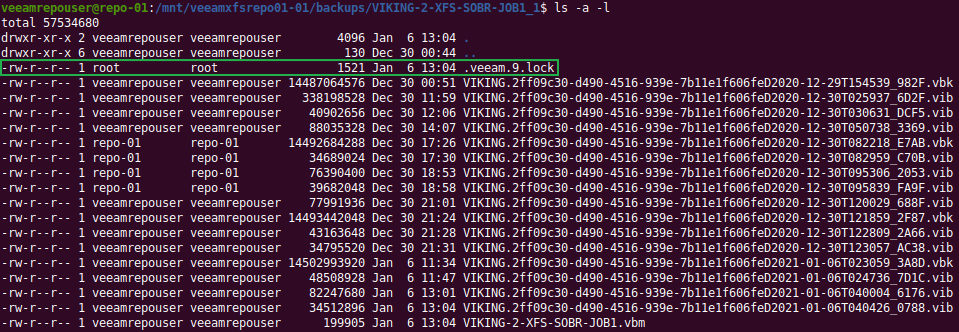
Let’s look inside to see if we can read something there?
cat .veeam.9.lock

When you open that file you will find it to be an XML file. Inside you’ll see the date and time stamp for every file in the backup chains for that job. That’s cool.
But there is more. When we run “getfattr *”to look for extend file attributes we find that every Veeam created file has a one called user.immutable.until.
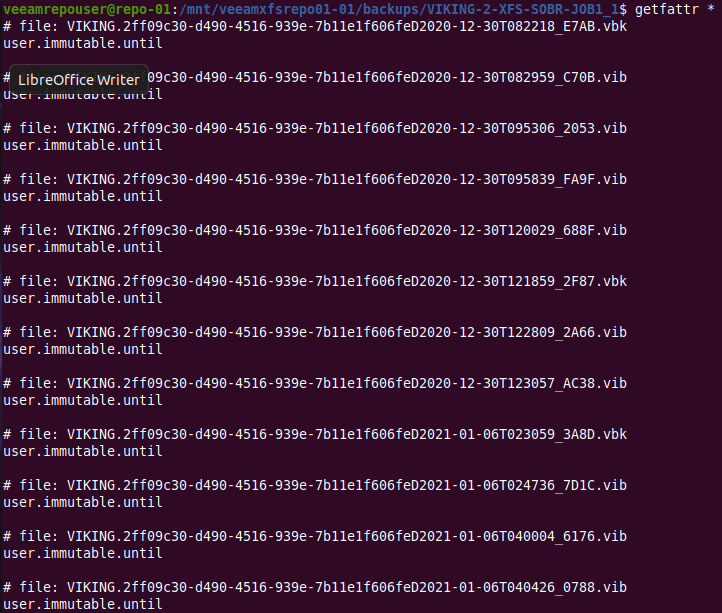
With that name, it is clear it can be of interest to us. If you look at what is in there, you’ll see it contains the date and time stamp for that file’s immutability period.
getfattr * -n user.immutable.until
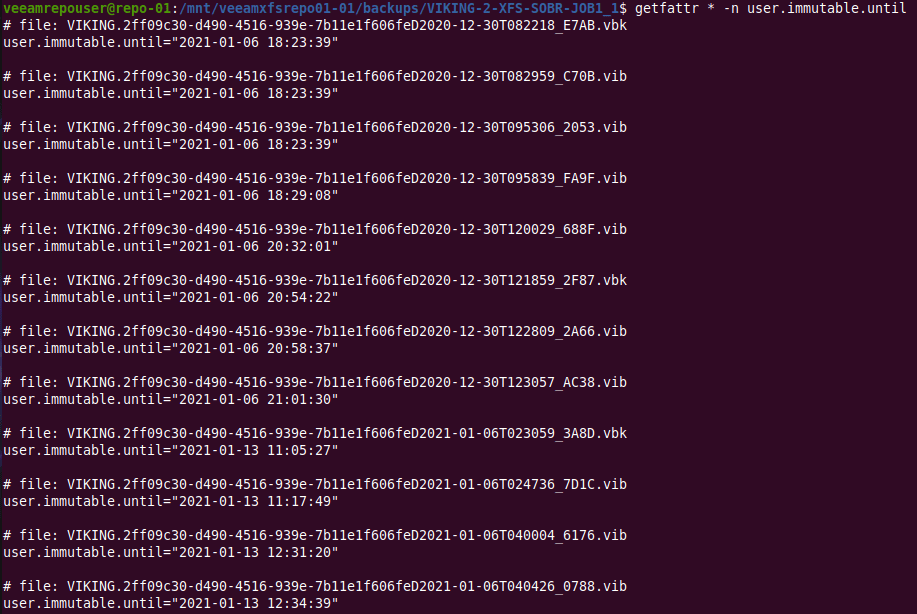
That I find interesting. Veeam saves the information twice. Is that for redundancy or as some sort of checksum? Maybe it also has to do with the fact Veeam backup files are transportable and self-contained so that information is stored as an extended file attribute.
Conclusion
So there you have it. A small piece of information on where the immutability information is stored. The most surprising thing to me was that it is actual stored twice.
I hope you fund this interesting. Poking around to figure out the how and what of things always helps me tremendously to learn and understand the technologies I want to work with. That leads to better decisions in design and implementation. It leads to both trust and confidence, which helps me decide where and when to leverage it. Finally it also, almost without, it is invaluable when supporting the technology.