Some days you walk into environments were legacy services that have been left running for 10 years as:
They do what they need to do
No one dares touch it
Have been forgotten, yet they provide a much used service
Recently I had the honor of migrating IAS that was still running on Windows Server 2003 R2 x86, which was still there for reason 1. Fair enough but with W2K3 going it’s high time to replace it. The good news was it had already been virtualized (P2V) and is running on Hyper-V.
Since Windows 2008 the RADIUS service is provided by Network Policy Server (NPS) role. Note that they do not use SQL for logging.
Now in W2K3 there is no export/import functionality for the configuration in IAS. So are we stuck? Well no, a tool has been provided!
Install a brand new virtual machine with W2K12R2 and update it. Navigate to C:WindowsSysWOW64 folder and grab a copy of IasMigReader.exe.
Place IasMigReader.exe in the C:WindowsSystem32 path on the source W2K3 IAS server as that’s configured in the %path% environment variable and it will be available anywhere from the command prompt.
Open a elevated command prompt
Run IasMigReader.exe
Copy the resulting ias.txt file from the C:WindowsSystem32IASfolder. Please keep this file secure it contains password. TIP: As a side effect you can migrate your RADIUS even if no one remembers the shared secrets and you now have them again
When Network Policy Server (NPS) is a member of an Active Directory® Domain Services (AD DS) domain, NPS performs authentication by comparing user credentials that it receives from network access servers with the credentials that are stored for the user account in AD DS. In addition, NPS authorizes connection requests by using network policy and by checking user account dial-in properties in AD DS.
For NPS to have permission to access user account credentials and dial-in properties in AD DS, the server running NPS must be registered in AD DS.
Membership in Domain Admins , or equivalent, is the minimum required to complete this procedure.
All that’s left to do now is pointing the WAPs (or switches & other RADIUS Clients) to the new radius servers. On decent WAPs this is easy as either one of them acts as a controller or you have a dedicated controller device in place.
TIP: Most decent WAPS & switches will allow for 2 Radius servers to be configured. So if you want you can repeat this to create a second NPS server with the option of load balancing. This provides redundancy & load balancing very easily. Only in larger environments multiple NPS proxies pointing to a number of NPS servers make sense.Here’s a DELL PowerConnect W-AP105 (Aruba) example of this.
Over the last 18 months cheaper, commodity, small port count, but high quality 10Gbps switches have become available. NetGear is a prime example. This means 10Gbps networking is within reach for even the smallest deployments.
Size is an often used measure for technological needs like storage, networking and compute but in many cases it’s way too blunt of a tool. A lot of smaller environments in specialized niches need more capable storage and networking capacities than their size would lead you to believe. The “Enterprise level” cost associated with the earlier SPF+ based swithes was an obstacle especially since the minimum port count lies around 24 ports, so with switch redundancy this already means 2 *24 ports. Then there’s the cost of vendor branded SPF+ modules. But that could be offset with Copper Twinax Direct Attach cabling (which have their sweet spots for use) or finding functional cheaper non branded SFP+ modules. But all that isn’t an issue anymore. Today 10GBase-T card & switches are readily available and ready for prime time. The issues with power consumption and heat have been dealt with.
While vendors like DELL have done some amazing work to bring affordable 10Gbps switches to the market it remained a obstacle for many small environments. Now with the cheaper copper based, low port count switches it’s become a lot easier to introduce 10Gbps while taking away the biggest operational pains.
You can start with a lower number of 10Gbps ports (8-12) instead of a minimum of 24.
No need for expensive vendor branded SPF+ modules.
Copper cabling (CAT6A) is relatively cheap for use in a rack or between two racks and for this kind of environment using patch lead cables isn’t an issue
Power consumption and heat challenges of copper 10Gbps has been addressed.
So even for the smallest setups where people would love to get 10Gbps for live migrations, hypervisor host backups and/or the virtual network it can be done now. If you introduce these for just CSV, live migration, storage or backup networks you can even avoid having to integrate them into the data network. This makes it easier, non disruptive & the isolation helps puts minds at easy about potential impacts of extra traffic and misconfigurations. Still you take away the heavy loads that might be disrupting your 1Gbps network, making things well again without needing further investments.
So go ahead, take the step and enjoy the benefits that 10Gbps bring to your (virtual) environment. Even medium sized shops can use this as a show case while they prepare for a 10Gbps upgrade for the server room or data center in the years to come.
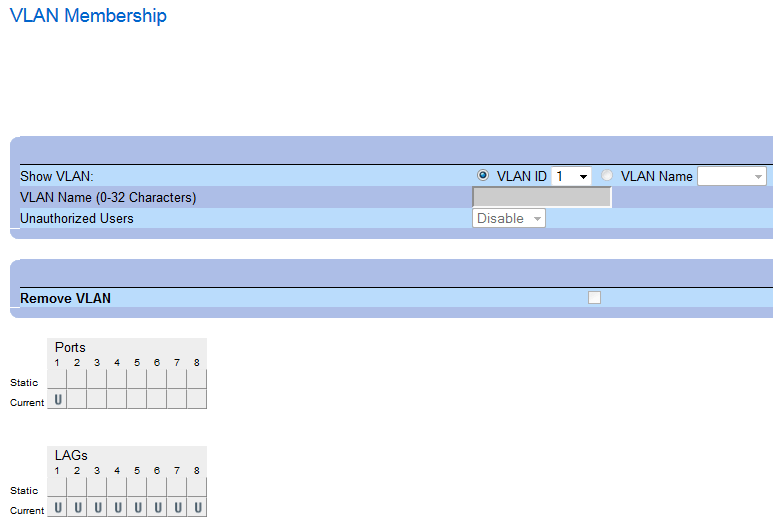
I was deploying a bunch of PowerConnect 2808 switches that needed to provide connectivity to multiple VLANs (Training, Guest, …) in classrooms. I should have figured it out before I got there with my “assumption” based quick configuration loaded on the switches if I had just refreshed my insights in how the PowerConnect family of switches work. Setting Up A Uplink (Trunk/General) With A Dell PowerConnect 2808 or 28XX series switch differs a bit from the higher-end PowerConnect.
Setting Up A Uplink (Trunk/General) With A Dell PowerConnect 2808 or 28XX
PowerConnect port mode refresher
So before we go on, here are the basics on switch port (or LAG) modes in the PowerConnect family. Please realize that switch behavior (especially for trunk mode in this context) has changed over time with more recent switches/firmware. But the current state of affairs is as follows (depending on what model & firmware you have behavior differs a bit).You can put your port or LAG in the following 3 (main) modes:
Access
The port belongs to a single untagged VLAN. When a port is in Access mode, the packet types which are accepted on the port cannot be designated. Ingress filtering cannot be enabled/disabled on an access port. So only untagged received traffic is allowed and all transmitted traffic is untagged. The setting of the port determines the VLAN of traffic. Tagged received traffic is dropped. Basically, this is what you set your ports for client devices to (printer, PC, laptop, NAS).
Trunk
In older versions this means that ALL transmitted traffic is tagged. That’s easy. Tagged received traffic is dropped if doesn’t belong to one of the defined VLAN on the trunk. In more recent switches/firmware untagged received traffic is dropped but for one VLAN, that can be untagged and still be received. Which is nice for the default VLAN and makes for a better compatibility with other switches.
General
You determine what the rules are. You can configure it to transmit tagged or untagged traffic per VLAN. Untagged received traffic is accepted and the PVID determines the VLAN it is tagged with. Tagged received traffic is dropped if doesn’t belong to one of the defined VLANs.
Setting Up A Uplink (Trunk/General) With A Dell PowerConnect 2808 or 28XX
These are good switches for their price point & use cases. Just make sure you buy them for the right use case. There is only one thing I find unforgiving in this day and age: the lack of SSH/HTTPS support for management.
Go ahead fire up a 2808 and take a look at the web interface and see what you can configure. In contrast with the PC54XX/55XX etc. Series you cannot set the port mode it seems. So how can this switch accommodate trunks/general/access modes at all. Well it’s implied in the configuration of ports that seem to be set in general mode by default and you cannot change that. The good news is that with the right setting a port in general mode behaves like a port in access or trunk mode. How? Well we follow the rules above.
So we assume here that a port is in general mode (can’t be changed). But we want trunk mode, so how do we get the same behavior? Let’s look at some examples in speudo CLI. (It’s web GUI only device).
Example 1: Classic Trunk = only defined tagged traffic is accepted. All untagged traffic is dropped
So we can have the same behavior is general mode using
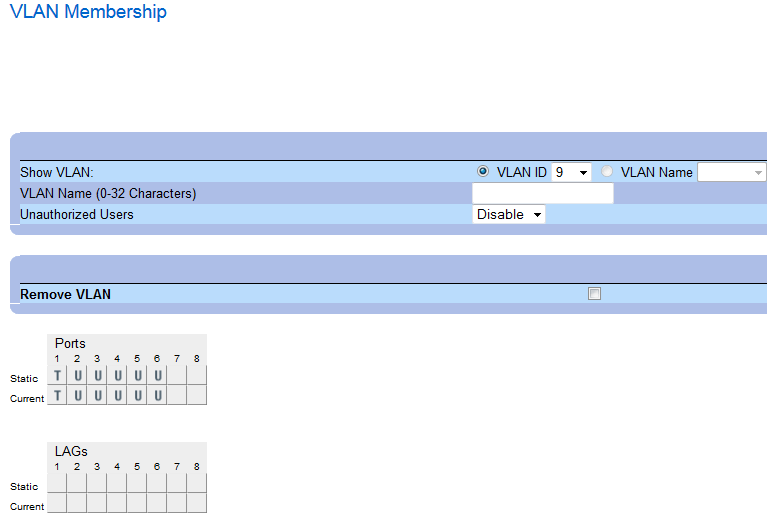
switchport mode general switchport general allowed vlan add 9, 20 tagged switchport general pvid 4095
The PVID of 4095 is the industry standard discard VLAN, it assign this VLAN to all untagged traffic which is dropped. Ergo this is the same as the trunk config above!
Example 2: Modern Trunk = only defined tagged traffic and one untagged VLAN is accepted
So we can have the same behavior is general mode using
switchport mode general switchport general allowed vlan add 9, 20 tagged switchport general pvid 1
This example is what we needed in the classroom. And is basically what you set with the GUI. So far so good. But we ran into an issue with connectivity to the access ports in VLAN 9 and VLAN 20. Let’s look at that in the next Example
Example 3: Access port mode = only one untagged VLAN is accepted
switchport mode access switchport access vlan 9
Switchport mode general switchport general allowed vlan add 9 untagged switchport general pvid 9
If you’re accustomed to the higher end PC switches you define the port in access mode and add the VLAN of you choice untagged. That’s it. Here the mode is general and can’t be changed meaning we need to set the PVID to 9 so all untagged traffic is indeed tagged with VLAN 9 on the port.
Setting Up an uplink between a PowerConnect 5548 and a 2808
Here’s the normal deal with higher range series of PowerConnect switches: you normally use the port mode to define the behavior and in our case we could go with a trunk or general mode. We use trunk, leave the native VLAN for the one untagged VLAN and add 9 and 20 as tagged VLANs.
The “trunk” port of LAG is left on the default PVID
So an “access” port for VLAN 9 is is achieved by setting the PVID to 9
And an “access” port for VLAN 20 is achieved by setting the PVID to 20
While the VLAN membership settings are what you’d expect them to be like on the higher end PowerConnect models:
First, VLAN 1 (native),
then LAN 9 (Corp),
and finally, VLAN 20 (Guest)
Conclusion
If it’s the first time configuring a PC2808 you might totally ignore the fact that needed to do some extra work to make traffic flow. There is no selection of access/general/trunk on a PowerConnect 2808. The port or LAG is “implicitly” set to general. The extra settings of the PVID and adding tagged/untagged VLANs will make it behave as general, trunk or access.
Set any other VLAN than the default 1 to tagged on the port or LAG you’ll use as uplink. So far things are quite “standard PowerConnect”.
You set the VLAN membership of your “access” ports to untagged to the VLAN you want them to belong to.
After that in on the “access” ports you set the PVID to the VLAN you want the port to belong to. If you do not do this the port still behaves as if it’s a VLAN 1 port. It will not get a DHCP address for that VLAN but for for the the one on VLAN 1 if there is one, or, if you use a static IP address for the subnet of a VLAN on that port you won’t have connectivity as it’s not set to the right VLAN.
The reason we used the PowerConnect 2808 series here is that they needed silent ones (passive cooling) in the training rooms. Multiple ones to avoid too many cables running around the place. That was the outcome of 2 minutes at the desk of the project manager’s quick fix to a changed requirement. The real solution of cause would have been to get 24+ outlets to the room in the correct places and add 24+ ports to the normal switch count in the hardware analysis for the building solution. But after the facts, you have to roll with the flow.
Plug ‘n Play enumeration of devices has been very useful for loading device drivers automatically but isn’t deterministic. As devices are enumerated in the order they are received it will be different from server to server but also within the system. Meaning that enumeration and order of the NIC ports in the operating system may vary and “Local Area Connection 2” doesn’t always map to port 2 on the on board NIC. It’s random. This means that scripting is “rather hard” and even finding out what NIC matches what port is a game of unplugging cables.
Consistent Device Naming is the solution
A mechanism that has to be supported by the BIOS was devised to deal with this and enable consistent naming of the NIC port numbering on the chassis and in the operating system.
But it’s even better. This doesn’t just work with on board NICs. It also works with add on cards as you can see. In the name column it identifies the slot in which the card sits and numbers the ports consistently.
In the DELL 12th Generation PowerEdge Servers this feature is enabled by default. It is not in HP servers for some reason, you need to turn in it on manually.
I first heard about this feature even before Windows Server 2012 Beta was released but as it turns out Dell has been involved with the development of this feature. It was Dell BIOS team members that developed the solution to consistently name network ports and had it standardized via PCI SIG. They also collaborated with Microsoft to ensure that Windows Server 2012 would support all this.
Here’s a screen shot of a DELL R720 (12th Generation PowerEdge Server) of ours. As you can see the Consistent Device Naming doesn’t only work for the on broad NIC card. It also does a fine job with add on cards of which we have quite a few in this server.
It clearly shows the support for Consistent Device Naming for the add on cards present in this server. This is a test server of ours (until we have to take it into production) and it has a quad 1Gbps Intel card, a dual Intel X520 DA card and a dual port Mellanox 10Gbps RoCE card. We use it to test out our assumptions & ideas. We still need a Chelsio iWarp card for more testing mind you
A closer look
This solution is illustrated the in the “Device Name column” in the screen shot below. It’s clear that the PnP enumerated name (the friendly name via the driver INF file) and the enumerated number value are very different from the number in Name column ( NIC1, NIC2, NIC2, NIC4) even if in this case where by change the order is correct. If the operating system is reinstalled, or drivers changed and the devices re-enumerated, these numbers may change as they did with previous operating systems.
The “Name” column is where the Consistent Device Naming magic comes to live. As you can see you are able to easily identify port names as they are numbered consistently, regardless of the “Device Name” column numbering and in accordance with the numbering on the chassis or add on card. This column name will NEVER differ between identical servers of after reinstalling a server because it is not dependent on PnP. Pretty cool isn’t it! Also note that we can rename the Name column and if we choose we can keep the original name in that one to preserve the mapping to the physical hardware location.
In the example below thing map perfectly between the Name column and the Device Name column but that’s pure luck.
On of the other add on cards demonstrates this perfectly.







 . See http://msdn.microsoft.com/en-us/library/cc754878.aspx:
. See http://msdn.microsoft.com/en-us/library/cc754878.aspx: