I recently had the opportunity to get my hands on a hardware load balancer for a project where, due to limitations in the configuration of the software, Windows Network Load Balancing could not be used. The piece of kit we got was a LoadMaster 2200 by Kemp Technologies. A GPS network/software services solution (NTRIP Caster) for surveyors needed load balancing, not only for distributing the load, but also to help with high availability. The software could not be configured to use a Virtual IP address of a Windows Load Balancer cluster. That meant when had to take the load balancing of the Windows server nodes. I had been interested in Kemp gear for a while now (in function of some Exchange implementations) but until recently I did not get my hands on a LoadMaster.

We have two networks involved. One the 192.1683.2.0/24 network serves as a management, back-office network to which the dial access calls are routed and load-balanced to 2 separate servers WebSurvey01 and WebSurvey02 (running VMs running on Hyper-V). The Other network is 192.168.1.0/24 and that serves the internet traffic for the web site and the NTRIP data for the surveyors, which is also load balanced to WebSurvey01 and WebSurvey02. The application needs to see the IP addresses of the clients so we want transparency. To achieve this we need to use the gateway of the VIP on the Kemp load balancer as the gateway. That means we can’t connect to those apps from the same subnet, but this is not required. The clients dial in or come in from the internet. A logical illustration (it’s not a complete overview or an exact network diagram) of such a surveyor’s network configuration is shown below.
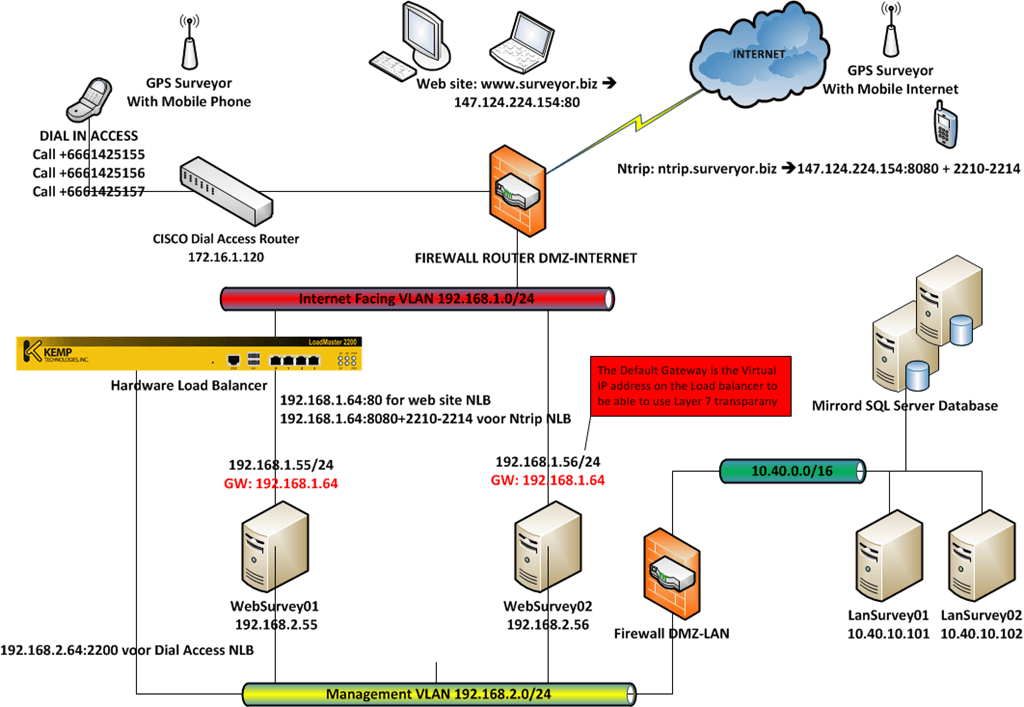
Why am I using layer 7 load balancing? Well, layer 4 is a transport layer (which is transparent but not very intelligent) and as such is not protocol aware while layer 7 is an application layer and is protocol aware. I want the latter as this gives me the possibility to check the health of the underlying service, filter on content, do funky stuff with headers (which allows us to give the clients IP to the destination server => X-Forwarded-For header when using layer 7), load balance traffic based on server load or service etc. Layer 7 not as fast as layer 4, as there is more things to do, code to run, but when you don’t overload the device that not a problem as it has plenty of processing power.
The documentation for the KEMP LoadMaster is OK. But I really do advise you to get one, install it in a lab and play with all the options to test it as much as you can. Doing so will give you a pretty good feel for the product, how it functions, and what you can achieve with it. They will provide you with a system to do just that when you want. If you like it and decide to keep it, you can pay for it and it’s yours. Otherwise, you can just return it. I had an issue in the lab due to a bad switch and my local dealer was very fast to offer help and support. I’m a happy customer so far. It’s good to see more affordable yet very capable devices on the market. Smaller projects and organizations might not have the vast amount of server nodes and traffic volume to warrant high-end load balancers but they have needs that need to be served, so there is a market for this. Just don’t get in a “mine is bigger than yours” contest about products. Get one that is the best bang for the buck considering your needs.
One thing I would like to see in the lower end models is a redundant hot-swappable power supply. It would make it more complete. One silly issue they should also fix in the next software update is that you can’t have a terminal connection running until 60 seconds after booting or the appliance might get stuck at 100% CPU load. Your own DOS attack at your fingertips. Update: I was contacted by KEMP and informed that they checked this issue out. The warning that you should not have the vt100 connected during a reboot is an issue the used to exist in the past but is no longer true. This myth persists as it is listed on the sheet of paper that states “important” and which is the first thing you see when you open the box. They told me they will remove it from the “important”-sheet to help put the myth to rest and your mind at ease when you unbox your brand new KEMP equipment. I appreciate their follow up and very open communication. From my experience, they seem to make sure their resellers are off the same mindset as they also provided speedy and correct information. As a customer, I appreciate that level of service.
The next step would be to make this he setup redundant. At least that’s my advice to the project team. Geographically redundant load balancing seems to be based on DNS. Unfortunately, a lot of surveying gear seems to accept only IP addresses so I’ll still have to see what possibilities we have to achieve that. No rush, getting that disaster recovery and business continuity site designed and setup will take some time anyway.
They have virtual load balancers available for both VMware and Hyper-V but not for their DR or Geo versions. Those are only on VMware still. The reason we used an appliance here is the need to make the load balancer as independent as possible of any hardware (storage, networking, host servers) used by the virtualization environment.