Here’s a small recap of an incident we dealt with recently and that served as a coaching exercise for troubleshooting. It seems we have Web Deploy 2.0 in use for in house deployments of web apps. It seems to be a valued asset as well. At least valuable enough to land a help request on the desk of one of the young, eager, smart, and upward mobile IT Professionals when it stops working and they need some assistance.
Hello ICT,
To deploy our we websites remotely we use web deployment service (see http://technet.microsoft.com/en-us/library/dd569087(WS.10).aspx for more info).
This service runs under the network service account by default. Deploying fails now. In the security log on the server I find “The specified account’s password has expired”.
Does anyone know the password of this account?
Best regards,
Hardworking Web Guy In Trouble
Basically, we have enough information to know something went wrong and that they need it to work again. But that’s about it. Password for the network service account expired? They also included an error log and reading it learns us something. The lesson to be learned here: investigate yourself, read the log, interpret them. Don’t let patients give you a diagnosis. Their input is critical, but you need to draw your own conclusions.
An account failed to log on.
Subject:
Security ID: LOCAL SERVICE
Account Name: LOCAL SERVICE
Account Domain: NT AUTHORITY
Logon ID: 0x3e5
Logon Type: 8
Account For Which Logon Failed:
Security ID: NULL SID
Account Name: WDeployConfigWriter
Account Domain: lab.test
Failure Information:
Failure Reason: The specified account’s password has expired.
Status: 0xc000006e
Sub Status: 0xc0000071
Process Information:
Caller Process ID: 0x1f44
Caller Process Name: C:WindowsSystem32inetsrvWMSvc.exe
What did we just read and learn? No, it’s not the Network Service Account whose password has expired. This doesn’t happen/doesn’t work that way … so that was our first indication that this isn’t quite right in the support ticket. As you can see the real problem account mentioned in the error log: WDeployConfigWriter. That account is indeed a local account.
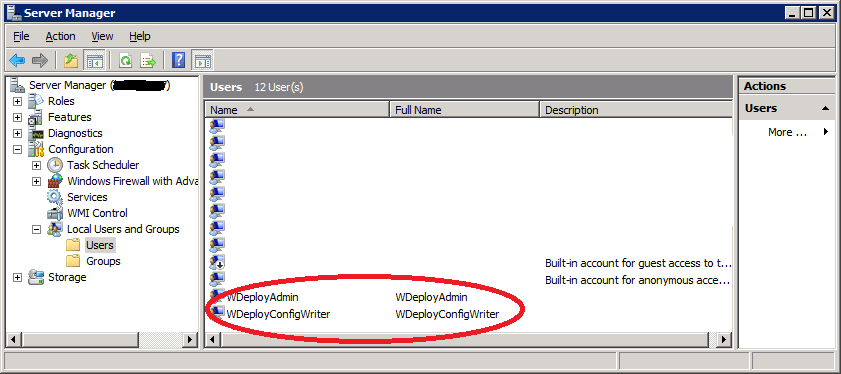
Cool, now we check what service runs under that account by looking in the services panel …. none! The easy way to check is to sort on the “Log On As” column. You won’t find WDeployConfigWriter. Right … , what else do we learn from the Services panel. Well we do have service called Web Deployment Agent Service running under the local Network Service account. We can stop and start it just fine so there is nothing wrong with the Network Service account, which is as expected and this service is not our culprit. What we also learn that this is Web Deploy 2.0.
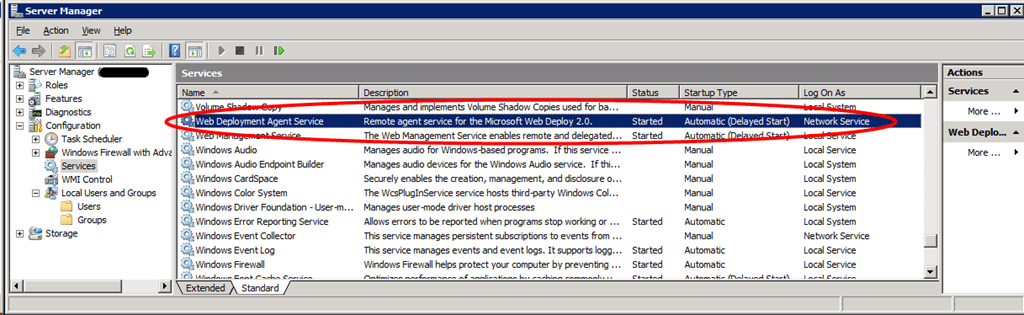
As the Web Deployment Agent Service has nothing to do with the problem at hand. So where is that WDeployConfigWriter being used and what is it status? Let’s take a look.
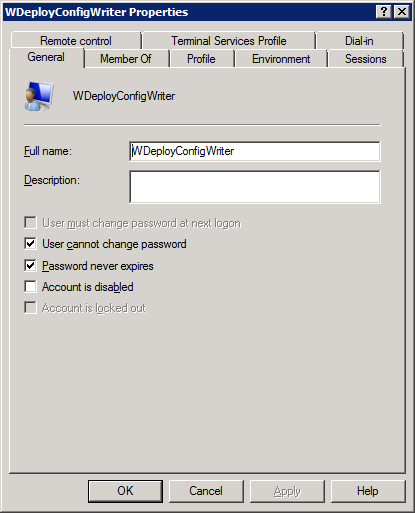
Hey, how could this account have expired? This is impossible. Unless they changed it while trying to fix the error. We check this with a quick phone call and yes, they did exactly that. The good thing is that this web guy is professional and tells us what they did. Some people think this might get them into trouble and won’t do that. It doesn’t change anything, things are what they are, but it does make communication less easy when you discover people act that way… So the lessons here are to double-check & verify what happened if at all possible. Originally the settings were:
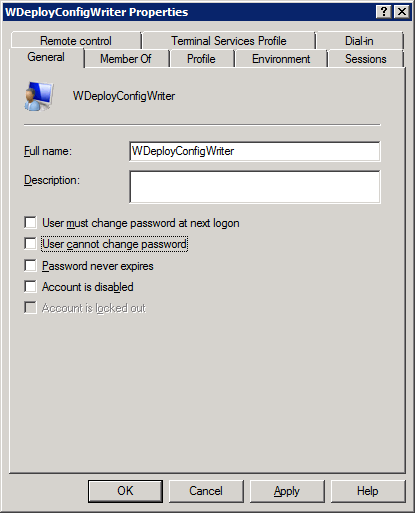
They changed them after they ran into issues hop that checking those options might fix it. Well no, expired is expired and you can’t fix it like that. You need indeed to correct the settings if you don’t want the password to expire and even prevent the user from changing it but you also need to set a new password when it has already expired. After doing so we contact the hardworking web guy in trouble to let them test and predict a new error: whatever runs under that Account will now fail to run due to an incorrect password. And guess what? “Unknown user name or bad password” in the security log.
Log Name: Security
Source: Microsoft-Windows-Security-Auditing
Date: 24/06/2011 10:30:39
Event ID: 4625
Task Category: Logon
Level: Information
Keywords: Audit Failure
User: N/A
Computer: server1.lab.test
Description:
An account failed to log on.
Subject:
Security ID: LOCAL SERVICE
Account Name: LOCAL SERVICE
Account Domain: NT AUTHORITY
Logon ID: 0x3e5
Logon Type: 8
Account For Which Logon Failed:
Security ID: NULL SID
Account Name: WDeployConfigWriter
Account Domain: lab.test
Failure Information:
Failure Reason: Unknown user name or bad password.
Status: 0xc000006d
Sub Status: 0xc000006a
Process Information:
Caller Process ID: 0x1f44
Caller Process Name: C:WindowsSystem32inetsrvWMSvc.exe
The user wants to repair install or uninstall and reinstall the application to “get a quick fix” but we do not give in and keep troubleshooting. It’s better to learn what the cause really is and how to fix it instead of relying on wishful reinstalling.
So where is the thing that runs under that account? We start a quick search in the registry and on the file system for the account name just in case it’s configured in the registry or a configuration file and let it run while we keep investigating. We also send a tweet into the universe, as perhaps someone out there knows this and can help out. We search the internet for Web Deploy 2.0 and WDeployConfigWriter. This results in very few hits, hmmm, interesting … One of them is http://blogs.iis.net/msdeploy/archive/2011/04/05/announcing-web-deploy-2-0-refresh.aspx
Where we learn a few things, the most important is the one line from that blog post I formatted in bold and red from the blog snippet right below. I also enlarged the picture from the blog post to make it readable where you can find in IIS what we learned here:
Notice that Web Deploy setup created two new local user accounts:
– WDeployConfigWriter, which has Write permissions to the IIS server’s applicationHost.config. This is used by delegation rules for createApp, appPoolNetFx and appPoolPipelineMode.
I’ve included the entire block of text from where this was taken below.
1. Easier setup for non-administrator deployments on IIS7
One of the common requests from our users was to make it easier to setup Web Deploy so non-administrators can publish to their sites. Typically, you will need to do this if you are running a shared hosting environment or if you are administering a build machine and you do not want users to have admin access.
If you launch the Web Deploy installer and choose “Custom”, you will notice a new option, “Configure for Non-administrator Deployments”:
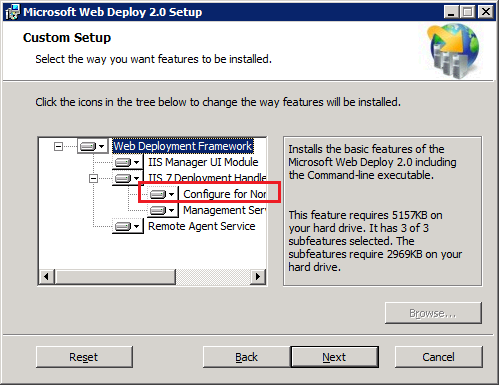
If you choose this option, Web Deploy will automatically create Management Service Delegation rules for the following providers, as well as user the accounts needed for providers like createApp and recycleApp that need elevated privileges.
These are the rules you will have in the Management Service Delegation UI in IIS Manager after you install this component:
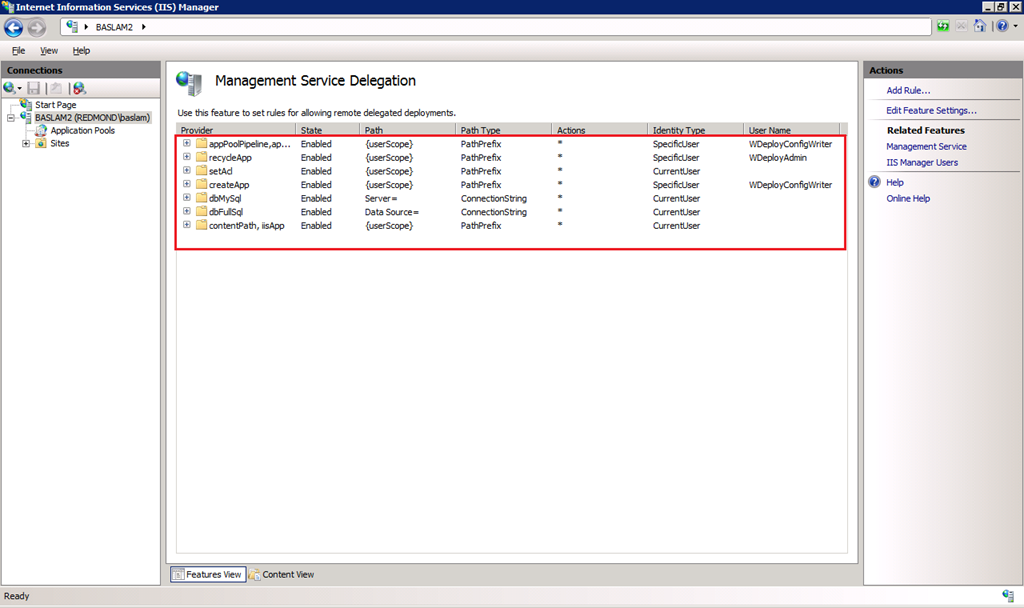
Notice that Web Deploy setup created two new local user accounts:
– WDeployConfigWriter, which has Write permissions to the IIS server’s applicationHost.config. This is used by delegation rules for createApp, appPoolNetFx and appPoolPipelineMode.
– WDeployAdmin, which is an administrator. This is used by delegation rules for recycleApp.
If you prefer to create these rules by hand, uncheck the component in the installer. We also provide a PowerShell script for creating delegation rules (more on this later in the post) if you prefer that route.
Well-armed with this information we go have a look at the Management Service Delegation:
Where we indeed find createApp, appPoolNetFx and appPoolPipelineMode:
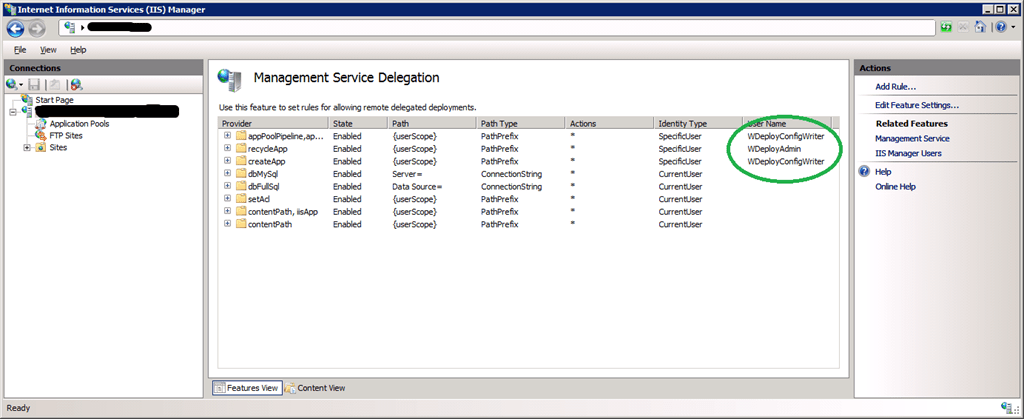
So now we take a look a bit what we can configure here and sure enough, by double-clicking on them the Edit Rule form:
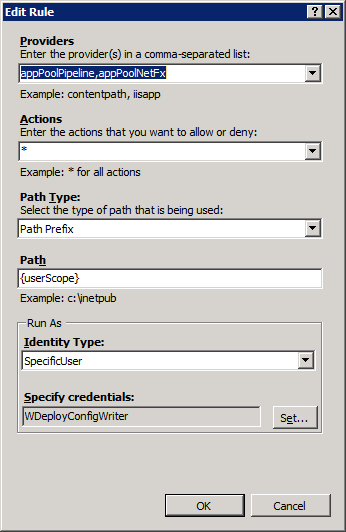
So we click on Edit security credentials and are welcomed by this form:
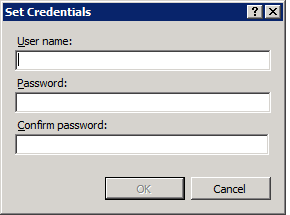
So we enter the account name and the new password we set before (remember to do this for both providers):
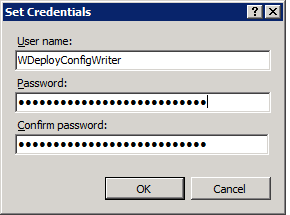
Guess what, end user happy, things are working again. Jay! From service down report to the helpdesk to fully operational again in less than an hour with a technology new to the service desk.
How did this happen and did they end up with this funky configuration (expiring password of an account that no one knows where it is used for and where configured)? Aha, operational control => know the configuration of what you use and know why it is configured that way and where it’s configured. Is it a mistake/assumption in the installer that the accounts WDeployConfigWriter and WDeployAdmin have their passwords set to expired and can be changed by the user or did somebody mess with them after the install? Well, I did the test by setting it up on a test server and found that they are indeed installed with their passwords set to expire and that the password can be changed by the user. It assumes that the person doing the install knows and realizes the implications. I’m not saying either setting is wrong but you should know why, when, and where. There is no documentation on this as far as we could find right now and perhaps the installer should mention the benefits/risks of both types of configuration and ask what to choose. This, together with better documentation, could help prevent this issue. As always, no guarantees are given
Overall lesson: don’t assume things, trust but verify …
