Introduction
THANK YOU MICROSOFT!
Anyone who has had to support developers and IT Pros alike running Hyper-V on their clients and test systems in an environment with 802.1x port authentication knows the extra effort you had put into workarounds. This was needed due to the fact that the Hyper-V switch did not support 802.1X EAPoL. Sometimes it was an extra NIC on non-authenticated ports, physical security for rooms with non-authenticated ports, going Wi-Fi everywhere and for everything etc. But in conditions where multiple interfaces are a requirement, this becomes impractical (not enough outlets, multiple dongles etc. or add in cards).
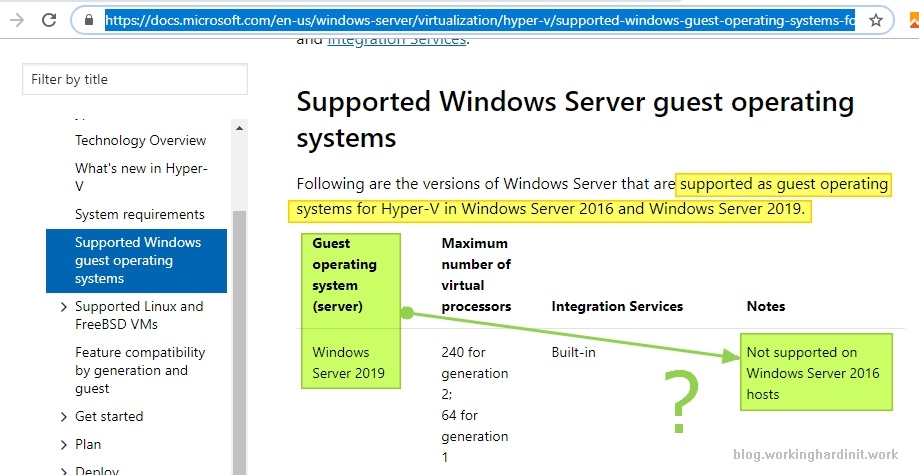
On top of that, there was always at least someone less than happy with the workaround. 802.1x Support with the Hyper-V switch looks like it could or should work when looking at the vNICs both on the host and inside the VMs. You’ll see that the authentication properties are there, the policies to make it all work are pushed but no joy, authentication would fail
802.1x Support with the Hyper-V switch is here!
Windows Server 2019 LTSC (1809) & Windows 10 (1809), as well as the 1809 or later SAC versions, now offer 802.1x Support with the Hyper-V switch.
This is not enabled by default. You will need to add a registry key in order for it to be enabled. Form an elevated command prompt run
Reg add “HKEY_LOCAL_MACHINE\SYSTEM\CURRENTControlSet\Services\vmsmp\parameters” /v 8021xEnabled /t REG_DWORD /d 1 /f
This change requires a reboot. So, we also give the Hyper-V host a kick
shutdown /r /t 0
When you have a Hyper-V switch that you share with the management OS you will see that the management vNIC now authenticates.
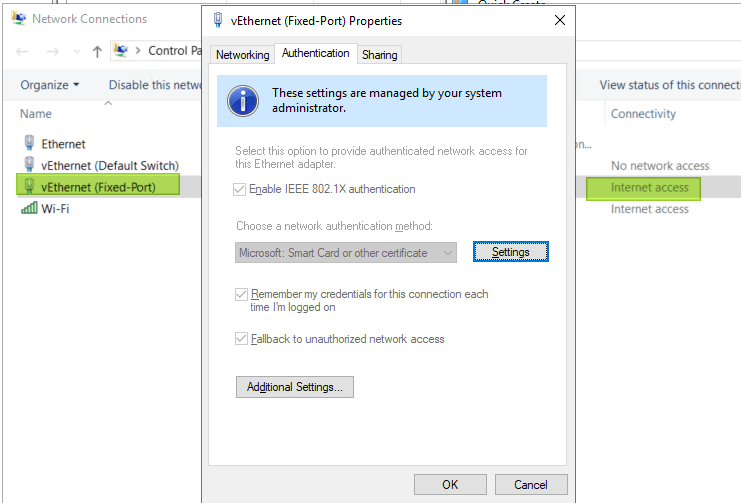
You can also authenticate VMs. Depending on your needs the configuration and setup will differ. 802.1x allows for Single-Session/Single-Host, Single-Session/Multiple-Host, Multiple- Session (names, abilities vary with switch type, model, vendor) and you’ll need to work out what is needed where for the scenarios you want to support, you won’t have one size fits all with port authentication. I’ll be sharing my experiences in the future.
The point is you’ll have to wrap your head around port authentication with 802.1x and its various options, permutations on the switches and radius servers. I normally deal with Windows NPS for the radius needs and the majority of my sites have DELL campus switches. Depending on the needs of the users (developers, IT Pros, engineers) for your VMs you will have to configure port authentication a bit differently and you’d better either own that network or have willing and able network team to work with.
Conclusion
Hurrah! I am a very happy camper. I am so very happy that 802.1x Support with the Hyper-V switch is here. This was very much missing from Hyper-V for such a long time the joy of finally getting makes me forget how long I had to wait! For this feature, I will shout “BOOM”!
With the extra focus on making Hyper-V on Windows 10 the premier choice for developers, this had to be fixed and they did. There are a lot more environments in my neck of the woods that leverage (physical) port authentication via 802.1x than I actually see IPSec in the wild. It might be different in other places but, that’s my reality. With ever more mobile and flex work as well as body shoppers, temp labor that bring their own devices I see physical port authentication remain for a very long time still.