However, three relevant things have changed since my original blog post:
Veeam v12.1 introduced a new encryption method. Firstly, in Veeam 12.1, the method of encrypting passwords has changed. That means the old script no longer works (always) as it only uses the legacy method.
Veeam published its encryption and decryption methods. Secondly, Veeam has published the methods used to encrypt and decrypt passwords in the spirit of full disclosure and to preempt anyone who attempts to claim that Veeam is insecure. Those individuals or companies demonstrate only ignorance and malicious intentions. The good news is that the article has all the information we need to write a new script.
Veeam now supports PostgreSQL, in addition to Microsoft SQL Server. Finally, Veeam now also supports MySQL as a database, in addition to Microsoft SQL. That means we need to ensure that we can retrieve the necessary data from both database types.
Instead of having two scripts, my old one and a newer one. I decided to create one that would work on VBR v12 and lower, as well as on VBR 12.1 and higher.
What Changed in Encryption
Until version 12, Veeam used its internal .NET static method:
That method leverages the native Microsoft Data Protection API (DPAPI) under the hood. It was part of the Veeam.Backup.Common.dll and worked well up to version 12. In v12.1 and beyond, this method no longer exists. Instead, Veeam now leverages the native Microsoft Data Protection API (DPAPI), directly:
Since both leverage the native Microsoft Data Protection API, I figured I could also use the [System.Security.Cryptography.ProtectedData]::Unprotect static method to decrypt those legacy passwords as long as I don’t try to leverage the optionalEntropy parameter for them. The good news is that in the KB article, Veeam provides instructions on how to differentiate between the legacy and new types of password encryption. That allows me to write logic to determine the version and execute the corresponding decryption method accordingly.
By the way, once you update a password on v12.1 or up, it will be encrypted with the new method. As time passes, by rotating the passwords, legacy encryption phases out.
The new script
I did not want to maintain two separate scripts, one for the legacy password decryption method and one for the newer one. That’s why I’ve consolidated everything into a single, unified PowerShell script. It supports:
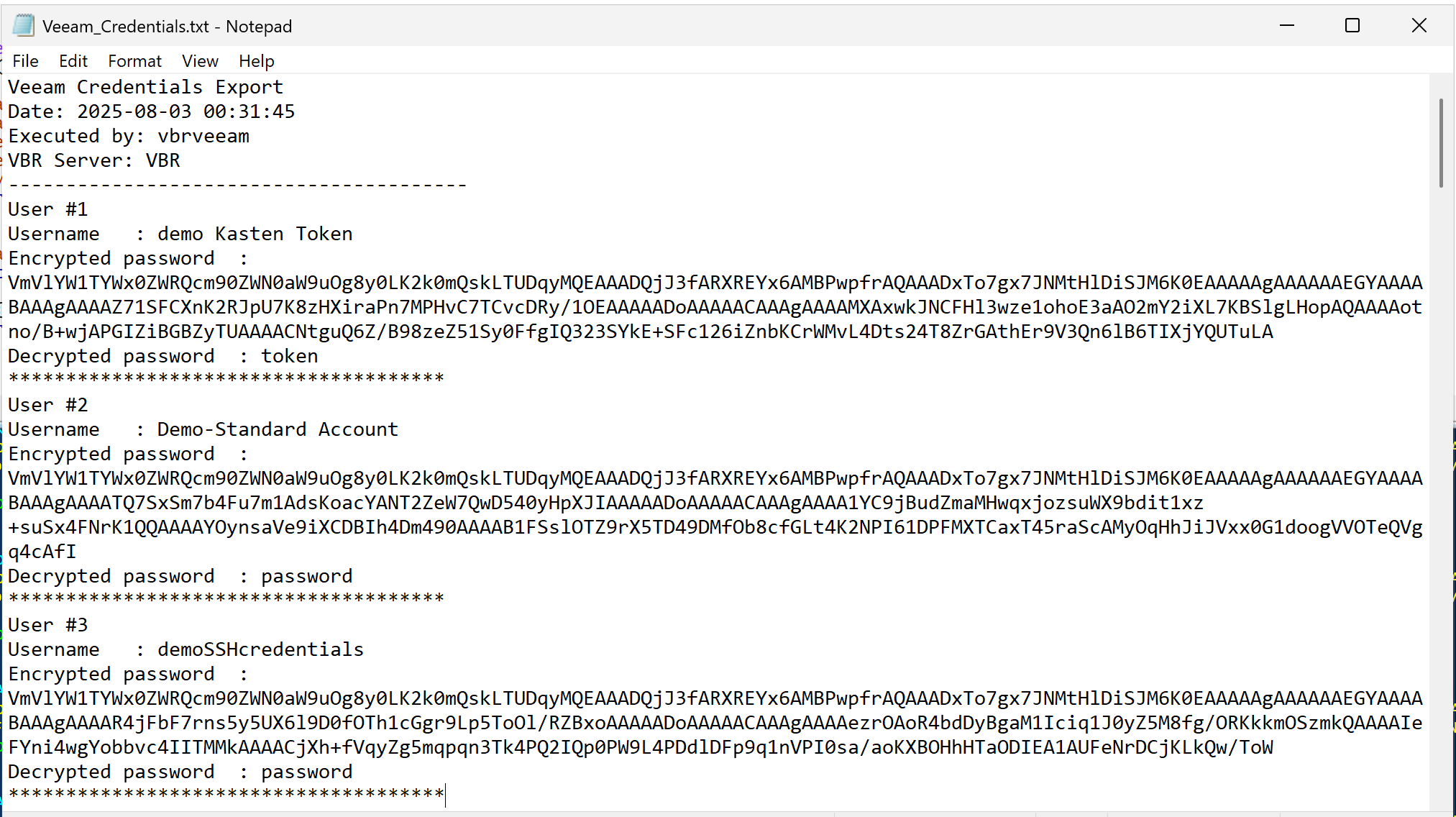
Supports VBR v10 through v12.3+ and decrypts Veeam credentials from registry and database.
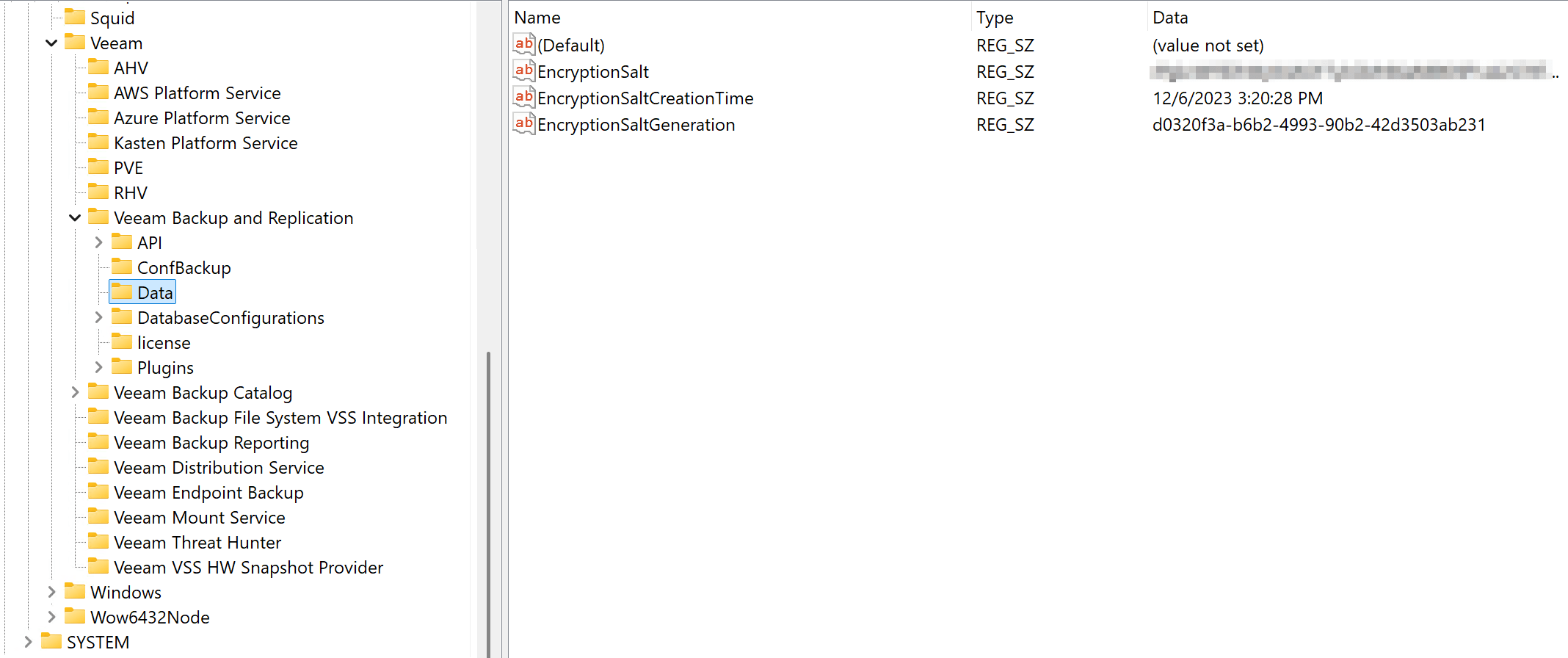
The Veeam Backup & Replication encryption salt in the registry lives here: Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Veeam\Veeam Backup and Replication\Data.
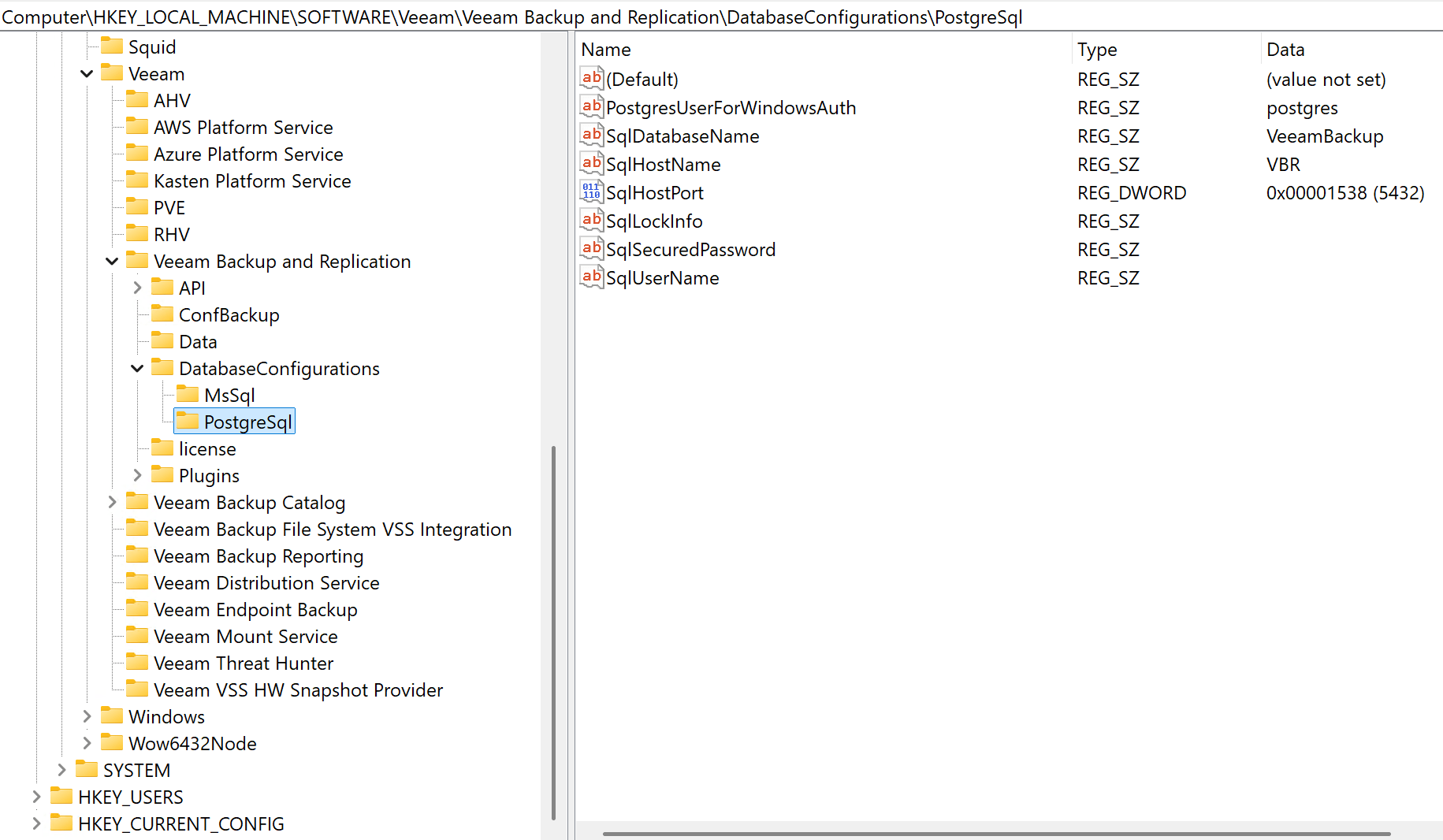
The Veeam database info in the registry lives here: Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Veeam\Veeam Backup and Replication\DatabaseConfigurations\
Per-user counters and clean output formatting
Supports MSSQL and PostgreSQL configurations
Handles multiple password formats:
‘v12 and lower’
‘v12.1 and up (with encryption salt)’
Optional filtering by username
Optional export to file (`Veeam_Credentials.txt` on Desktop)
Graceful error handling and informative console output
The script runs on Windows only, because DPAPI is a Windows-native feature. With VBR v13 introducing Linux-based deployments, this script won’t work in those environments. That’s a different challenge for another day.
The IT world, like everywhere else, is not a perfect place, and I need a way to deal with imperfection. It is that simple. If we are honest, we all know that IT environments aren’t always in pristine condition. Whether it’s a lab, a forgotten backup server, or an entire backup fabric for a production environment abandoned by a previous IT partner, credentials are often missing. Documentation is sparse. And when disaster strikes, you need access, fast.
My script has already helped IT teams recover access to critical systems when no one else could. I know because I’ve seen it happen. Before Veeam ever published its KB article, my original script was quietly saving the day in real-world scenarios.
Conclusion
Knowledge is power. And while power inherently allows abuse, hiding knowledge under the guise of “security” is just security theater. Security through obscurity is not security but window dressing.
That’s why I’m glad Veeam documented their credential encryption methods. It empowers administrators to recover access responsibly. And it exposes the charlatans who twist transparency into baseless accusations of insecurity. I just felt compelled to create a handy, functional script around it that I can use when needed.
If someone uses this information to claim Veeam is irresponsible, they could not be more wrong. They prove themselves to be untrustworthy. To me, they’ve lost their reputation and credibility.
This script isn’t about hacking. It’s about recovery, accountability, and clarity. And if it helps you regain control of your environment when all else fails, then it’s done its job.
As an observer of the changes in the hypervisor market in 2024 and 2025, you have undoubtedly noted considerable commotion and dissent in the market. I did not have to deal with it as I adopted and specialized in Hyper-V from day one. Even better, I am pleased to see that many more people now have the opportunity to experience Hyper-V and appreciate its benefits.
While the UI management is not as sleek and is more fragmented than that of some competitors, it offers all the necessary features available for free. Additionally, PowerShell automation enables you to create any tooling you desire, tailored to your specific needs. Do that well, and you do not need System Center Virtual Machine Manager for added capabilities. Denying the technical capabilities and excellence of Hyper-V only diminishes the credibility and standing of those who do so in the community.
That has been my approach for many years, running mission-critical, real-time data-sensitive workloads on Hyper-V clusters. So yes, Microsoft could have managed the tooling experience a bit better, and that would have put them in an even better position to welcome converting customers. Despite that, adoption has been rising significantly over the last 18 months and not just in the SME market.
Commotion, fear, uncertainty, and doubt
The hypervisor world commotion has led to people looking at other hypervisors to support their business, either partially or wholesale. The moment you run workloads on a hypervisor, you must be able to protect, manage, move, and restore these workloads when the need to do so arises. Trust me, no matter how blessed you are, that moment comes to us all. The extent to which you can handle it, on a scale from minimal impact to severe impact, depends on the nature of the issue and your preparedness to address it.
Customers with a more diverse hypervisor landscape means that data protection vendors need to support those hypervisors. I think that most people will recognize that developing high-quality software, managing its lifecycle, and supporting it in the real world requires significant investment. So then comes the question, which ones to support? What percentage of customers will go for hypervisor x versus y or z? I leave that challenge to people like Anton Gostev and his team of experts. What I can say is that Hyper-V has taken a significant leap in adoption, as it is a mature and capable platform built and supported by Microsoft.
The second rise of Hyper-V
Over the past 18 months, I have observed a significant increase in the adoption of Hyper-V. And why not? It is a mature and capable platform built and supported by Microsoft. The latter makes moving to it a less stressful choice as the ecosystem and community are large and well-established. I believe that Hyper-V is one of the primary beneficiaries of the hypervisor turmoil. Adoption is experiencing a second, significant rise. For Veeam, this was not a problem. They have provided excellent Hyper-V support for a long time, and I have been a pleased customer, building some of the best and most performant backup fabrics on our chosen hardware.
But who are those customers adopting Hyper-V? Are they small and medium businesses (SME) or managed service providers? Or is Hyper-V making headway with big corporate enterprises as well? Well, neither Microsoft nor Veeam shares such data with me. So, what do I do? Weak to strong signal intelligence! I observe what companies are doing and what they are saying, in combination with what people ask me directly. That has me convinced that some larger corporations have made the move to Hyper-V. Some of the stronger signals came from Veeam.
Current and future Veeam Releases
Let’s look at the more recent releases of Veeam Backup & Replication. With version 12.3, support for Windows Server 2025 arrived very fast after the general availability of that OS. Hyper-V, by the way, is getting all the improvements and new capabilities for Hyper-V just as much as Azure Local. That indicates Microsoft’s interest in making Hyper-V an excellent option for any customer, regardless of how they choose to run it, be it on local storage, with shared storage, on Storage Spaces Direct (S2D), or Azure Local. That is a strong, positive signal compared to previous statements. Naturally, Hyper-V benefits from Veeam’s ongoing efforts to resolve issues, enhance features, and add capabilities, providing the best possible backup fabric for everyone. I will discuss that in later articles.
Now, the strong signal and very positive signal from Veeam regarding Hyper-V came with updates to Veeam Recovery Orchestrator. Firstly, Veeam Recovery Orchestrator 7.2 (released on February 18th, 2025) introduced support for Hyper-V environments. What does that tell me? The nature, size, and number of customers leveraging Hyper-V that need and are willing to pay for Veeam Recovery Orchestrator have grown to a point where Veeam is willing to invest in developing and supporting it. That is new! On the Product Update page, https://community.veeam.com/product-updates/veeam-recovery-orchestrator-7-2-9827, you can find more information. The one requirement that sticks out is the need for System Center Virtual Machine Manager. Look at these key considerations:
System Center Virtual Machine Manager (SCVMM) 2022 & CSV storage registered in SCVMM is supported.
Direct connections to Hyper-V hosts are not supported.
Support for Azure Local recovery target: You can now use Azure Local as a recovery target for both vSphere and Hyper-V workloads, expanding flexibility and cloud recovery options.
Hyper-V direct-connected cluster support: Extended Hyper-V functionality enables support for direct-connected clusters, eliminating the need for SCVMM. This move simplifies deployment and management for Hyper-V environments.
MFA integration for VRO UI: Multi-Factor Authentication (MFA) can now be enabled to secure logins to the VRO user interface, providing enhanced security and compliance. Microsoft Authenticator and Google Authenticator apps are supported.
Especially 1 and 2 are essential, as they enable Veeam Recovery Orchestrator to support many more Hyper-V customers. Again, this is a strong signal that Hyper-V is making inroads. Enough so for Veeam to invest. Ironically, we have Broadcom to thank for this. Which is why in November 2024, I nominated Broadcom as the clear and unchallenged winner of the “Top Hyper-V Seller Award 2024” (https://www.linkedin.com/posts/didiervanhoye_broadcom-mvpbuzz-hyperv-activity-7257391073910566912-bTTF/)
Conclusion
Hyper-V and Veeam are a potent combination that continues to evolve as market demands change. Twelve years ago, I was testing out Veeam Backup & Replication, and 6 months later, I became a Veeam customer. I am still convinced that for my needs and those of the environments I support, I have made a great choice.
The longevity of the technology, which evolves in response to customer and security needs, is a key factor in determining great technology choices. In that respect, Hyper-V and Veeam have performed exceptionally well, striking multiple bullseye shots without missing a beat. And missing out on the hypervisor drama, we have hit the bullseye once more!
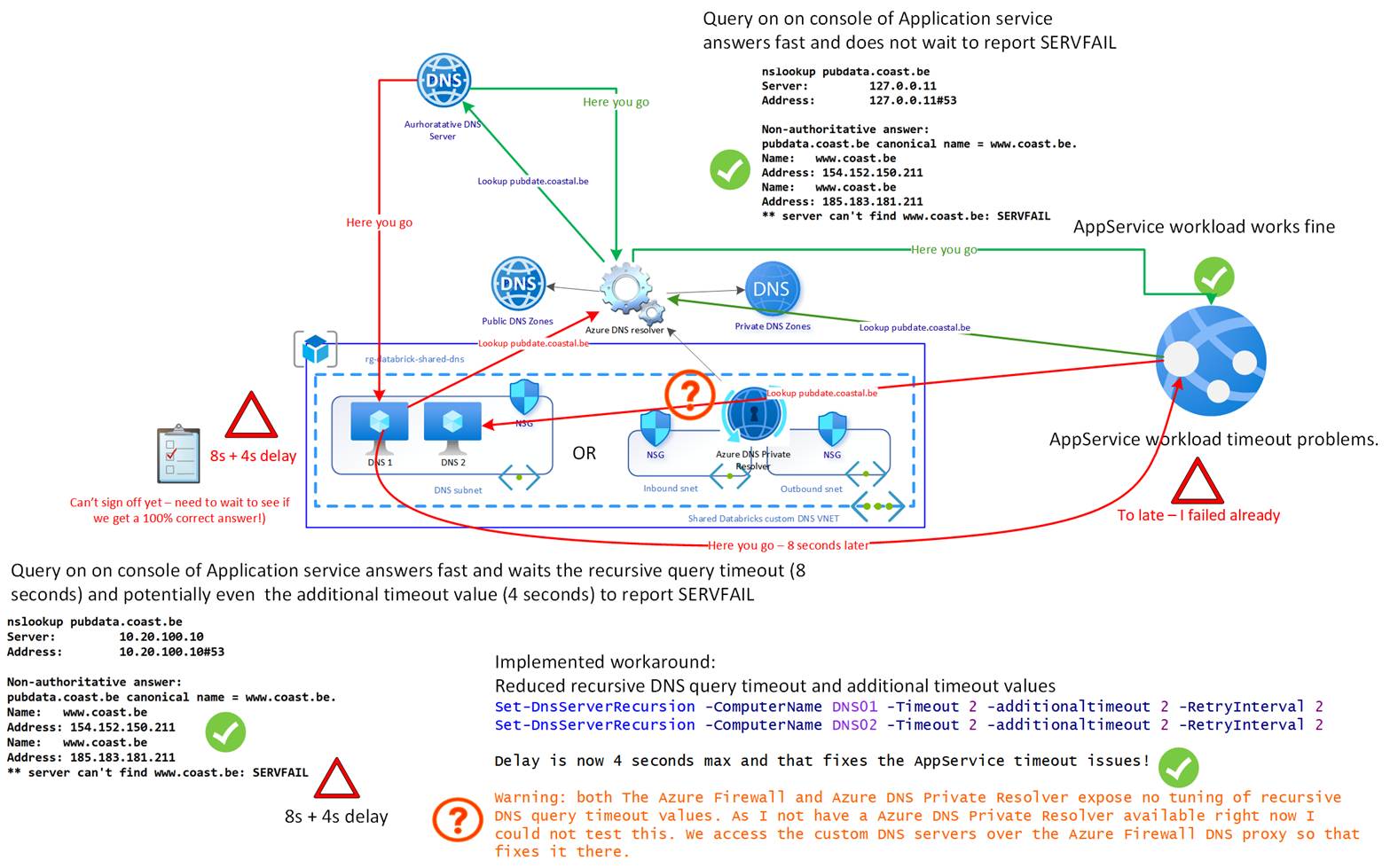
The very strict Azure recursive DNS resolver, when combined with a Custom DNS resolver, can cause a timeout-sensitive application to experience service disruption due to ambiguities in third-party DNS NS delegation configurations.
Disclaimer
I am using fantasy FQDNs and made-up IP addresses here. Not the real ones involved in the issue.
Introduction
Services offered by a GIS-driven business noticed a timeout issue. Upon investigation, this was believed to be a DNS issue. That was indeed the case, but not due to a network or DNS infrastructure error, let alone a gross misconfiguration.
The Azure platform DNS resolver (168.63.129.16) is a high-speed and very strict resolver. While it can return the IP information, it does indicate a server error.
nslookup pubdata.coast.be
Server: 127.0.0.11
Address: 127.0.0.11#53
Non-authoritative answer:
pubdata.coast.be canonical name = www.coast.be.
Name: www.coast.be
Address: 154.152.150.211
Name: www.coast.be
Address: 185.183.181.211
** server can’t find www.coast.be: SERVFAIL
Azure handles this by responding fast and reporting the issue. The Custom DNS service, which provides DNS name resolution for the service by forwarding recursive queries to the Azure DNS resolver, also reports the same problem. However, it does not do this as fast as Azure. Here, it takes 8 seconds (Recursive Query Timeout value), potentially 4 seconds longer due to the additional timeout value. So, while DNS works, something is wrong, and the extra time before the timeout occurs causes service issues.
When first asked to help out, my first questions were if it had ever worked and if anything had changed. The next question was whether they had any control over the time-out period to adjust it upward, which would enable the service to function correctly. The latter was not possible or easy, so they came to me for troubleshooting and a potential workaround or fix.
<hash2>.be. 600 IN RRSIG NSEC3 8 2 600 20250816062813 20250724154732 62188 be. <RRSIG_DATA_ANONYMIZED>
;; Received 610 bytes from 194.0.37.1#53(b.nsset.be) in 10 ms
pubdata.coast.be. 3600 IN CNAME www.coast.be.
www.coast.be. 3600 IN NS dns-lb1.corpinfra.be.
www.coast.be. 3600 IN NS dns-lb2.corpinfra.be.
;; Received 151 bytes from 185.183.181.135#53(ns1.corpinfra.be) in 12 ms
The DNSSEC configuration is not the issue, as the signatures and DS records appear to be correct. So, the delegation inconsistency is what causes the SERVFAIL, and the duration of the custom DNS servers’ recursive query timeout causes the service issues.
The real trouble is here:
pubdata.coast.be. 3600 IN CNAME www.coast.be
www.coast.be. 3600 IN NS dns-lb1.corpinfra.be.
This means pubdata.coast.be is a CNAME to www.coast.be. But www.coast.be is served by different nameservers than the parent zone (coast.be uses ns1/ns2.corpinfra.be). This creates a delegation inconsistency:
The resolver must follow the CNAME and query a different set of nameservers. If those nameservers don’t respond authoritatively or quickly enough, or if glue records are missing, resolution may fail.
Strict resolvers (such as Azure DNS) may treat this as a lame delegation or a broken chain, even if DNSSEC is technically valid.
Workarounds
I have already mentioned that fixing the issue in the service configuration setting was not on the table, so what else do we have to work with?
A quick workaround is to use the Azure platform DNS resolver (168.63.129.16) directly, which, due to its speed, avoids the additional time required for finalizing the query. However, due to DNS requirements, this workaround is not always an option.
The other one is to reduce the recursive query timeouts and additional timeout values on the custom DNS solution. This is what we did. The timeout value is now 2 (default is 8), and the additional timeout value is now 2 (default is 4). That is what I did to resolve the issue as soon as possible. Monitor this to ensure that no other problems arise after taking this action.
Third, we could conditionally forward coast.be to the dns-lb1.corpinfra.be and dns-lb2.corpinfra.be NS servers. That works, but it requires maintenance when those name servers change, so we need to keep an eye on that. We already have enough work.
A fourth workaround is to provide an IP address from a custom DNS query in the source code to a public DNS server, such as 1.1.1.1 or 8.8.8.8, when accessing the pubdata.coast.be FQDN is involved. This is tedious and not desirable.
The most elegant solution would be to address the DNS configuration Azure has an issue with. That is out of our hands, but it can be requested from the responsible parties. For that purpose, you will find the details of our findings.
Issue Summary
The .be zone delegates coast.be to the NS servers:
dns-lb1.corpinfra.be
dns-lb2.corpinfra.be
However, the coast.be zone itself lists different NS servers:
ns1.corpinfra.be
ns2.corpinfra.be
This discrepancy between the delegation NS records in .be and the authoritative NS records inside the coast.be zone is a violation of DNS consistency rules.
Some DNS resolvers, especially those performing strict DNSSEC and delegation consistency checks, such as Azure Native DNS resolver, interpret this as a misconfiguration and return SERVFAIL errors. This happens even when the IP address(es) for pubdata.coast.be can indeed be resolved.
Other resolvers (e.g., Google Public DNS, Cloudflare) may be more tolerant and return valid answers despite the mismatch, without mentioning any issue.
Why could this be a problem?
DNS relies on consistent delegation to ensure:
Security
Data integrity
Reliable resolution
When delegation NS records and authoritative NS records differ, recursive resolvers become uncertain about the actual authoritative servers.
This uncertainty often triggers a SERVFAIL to avoid possibly returning stale or malicious data. When NS records differ between parent and child zones, resolvers may reject responses to prevent the use of stale or spoofed data.
Overview
Zone Level
NS Records
Notes
.be (parent)
dns-lb1.corpinfra.be, dns-lb2.corpinfra.be
Delegation NS for coast.be
coast.be
ns1.corpinfra.be, ns2.corpinfra.be
Authoritative NS for zone
Corpinfra.be (see https://www.dnsbelgium.be/nl/whois/info/corpinfra.be/details) – this is an example, the domain is fictitious – operates all four NS servers that resolve to IPs in the same subnet, but the naming inconsistency causes delegation mismatches.
Recommended Fixes
Option 1: Update coast.be zone NS records to match the delegation NS
Add dns-lb1.corpinfra.be and dns-lb2.corpinfra.be as NS records in the coast.be zone alongside existing ones (ns1 and ns2), so the zone’s NS RRset matches the delegation.
coast.be. IN NS ns1.corpinfra.be.
coast.be. IN NS ns2.corpinfra.be.
coast.be. IN NS dns-lb1.corpinfra.be.
coast.be. IN NS dns-lb2.corpinfra.be.
Option 2: Update .be zone delegation NS records to match the zone’s NS records
Change the delegation NS records in .be zone to use only:
remove dns-lb1.corpinfra.be and dns-lb2.corpinfra.be
Option 3: Align both the .be zone delegation and coast.be NS records to a consistent unified set
Either only use ns1.corpinfra.be abd ns2.corpinfra.be for both the delegation and authoritative zone NS records, or only use dns-lb1.corpinfra.be and dns-lb2.corpinfra.be for both. Or use all of them; three or more geographically dispersed DNS servers are recommended anyway. Depends on who owns and manages the zone.
What to choose?
Option
Description
Pros
Cons
1
Add dns-lb1 and dns-lb2 to the zone file
Quick fix, minimal disruption
Maybe the zones are managed by <> entities
2
Update .be delegation to match zone NS (ns1, ns2)
Clean and consistent
Requires coordination with DNS Belgium
3
Unify both delegation and zone NS records
Most elegant
Requires a full agreement between all parties
All three options are valid, but Option 3 is the most elegant and future-proof. That said, this is a valid configuration as is, and one might argue that Azure’s DNS resolver’s strictness is the cause of the issue. Sure, but in a world where DNSSEC is growing in importance, such strictness might become more common? Additionally, if the service configuration could handle a longer timeout, that would also address this issue. However, that is outside my area of responsibility.
Simulation: Resolver Behavior
Resolver
Behavior with Mismatch
Notes
Azure DNS resolver
SERVFAIL
Strict DNSSEC & delegation checks
Google Public DNS
Resolves normally
Tolerant of NS mismatches
Cloudflare DNS
Resolves normally
Ignores delegation inconsistencies
Unbound (default)
May vary
Depends on configuration flags
Bind (strict mode)
SERVFAIL
Enforces delegation consistency
Notes
No glue records are needed for coast.be, because the NS records point to a different domain (corpinfra.be), so-called out-of-bailiwick name servers, and .be correctly delegates using standard NS records.
After changes, flush DNS caches
Conclusion
When wading through the RFC we can summarize the findings as below
RFC Summary: Parent vs. Child NS Record Consistency
RFC
Section
Position on NS Matching
Key Takeaway
RFC 1034
§4.2.2
No mandate on matching
Describes resolver traversal and authoritative zones, not strict delegation consistency
RFC 1034
§6.1 & §6.2
No strict matching rule
Discusses glue records and zone cuts, but doesn’t say they must be aligned
RFC 2181
§5.4.1
Explicit: child may differ
Parents’ NS records are not authoritative for the child; the child can define its own set.
RFC 4035
§2.3
DNSSEC implications
Mismatched NS sets can cause issues with DNSSEC validation if not carefully managed.
RFC 7719
Glossary
Reinforces delegation logic
Clarifies that delegation does not imply complete control or authority over the child zone
In a nutshell, RFC 2181 Section 5.4.1 is explicit: the NS records in a parent zone are authoritative only for that parent, not for the child. That means the child zone can legally publish entirely different NS records, and the RFC allows it. So, why is there an issue with some DNS resolvers, such as Azure?
Azure DNS “Soft” Enforces Parent-Child NS Matching
Azure DNS resolvers implement strict DNS validation behavior, which aligns with principles of security, reliability, and operational best practice, not just the letter of the RFC. This is a soft enforcement; the name resolution does not fail.
Why
1. Defense Against Misconfigurations and Spoofing
Mismatched NS records can indicate stale or hijacked delegations.
Azure treats mismatches as potential risks, especially in DNSSEC-enabled zones, and returns SERVFAIL to warn about potential spoofed responses, but does not fail the name resolution.
2. DNSSEC Integrity
DNSSEC depends on a trusted chain of delegation.
If the parent refers to NS records that don’t align with the signed child zone, validation can’t proceed.
Azure prioritizes integrity over leniency, which is why there is stricter enforcement.
3. Predictable Behavior for Enterprise Networks
In large infrastructures (like hybrid networks or private resolvers), predictable resolution is critical.
Azure’s strict policy ensures that DNS resolution failures are intentional and traceable, not silent or inconsistent like in looser implementations.
4. Internal Resolver Design
Azure resolvers often rely on cached referral points.
When those referrals don’t match authoritative data at the zone apex, Azure assumes the delegation is unreliable or misconfigured and aborts resolution.
Post Mortem summary
Azure DNS resolvers enforce delegation consistency by returning a SERVFAIL error when parent-child NS records mismatch, thereby signaling resolution failure rather than silently continuing or aborting. While RFC 2181 §5.4.1 allows child zones to publish different NS sets than the parent, Azure chooses to explicitly flag inconsistencies to uphold DNSSEC integrity and minimize misconfiguration risks. This deliberate error response enhances reliability in enterprise environments, ensuring resolution failures are visible, traceable, and consistent with secure design principles.
This was a perfect storm. A too-tight timeout setting in the service (which I do not control), combined with the Azure DNS resolvers’ rigorous behavior, which is fronted by a custom DNS solution required to serve all possible DNS needs in the environment, results in longer times for recursive DNS resolution that finally tripped up the calling service.
Last week, I was on service desk duty. It’s not my favorite field of endeavour, and I’m past my due date for that kind of work. However, doing it once in a while is an eye-opener to how disorganized and chaotic many organizations are. Some requests are ideal to solve by automating them and handing them over to the team to leverage. That is how I wrote a script to bulk invite guest users to Azure Entra ID, as I could not bring myself to click through the same action dozens of times in the portal. You can find the script on my GitHub page https://github.com/WorkingHardInIT/BulkInviteGuestUsersToEntraIdAzure
Script to Bulk Invite Guest Users to Azure Entra ID
📌 Overview
This PowerShell script allows administrators to bulk invite guest users to an Azure Entra ID (formerly Azure Active Directory) tenant using Microsoft Graph. It includes retry logic for connecting to Microsoft Graph, supports both interactive and device code login, and reads user details from a CSV file.
✨ Features
Connects to Microsoft Graph securely using MS Graph PowerShell SDK
Retry logic with customizable attempt count
Supports both interactive and device-based authentication
Invites guest users based on a CSV file input
Allows optional CC recipients in the invitation email (limited to one due to API constraints)
Includes meaningful console output and error handling
Note: Only the first ccRecipient will be used due to a known Microsoft Graph API limitation.
🔧 Script Configuration
Open the script and configure the following variables:
$Scopes = "User.Invite.All" # Required scope
$csvFilePath = ".\BulkInviteGuestUsersToAzureEntraID.csv"
$TenantID = "<your-tenant-id-guid-here>" # Replace with your tenant ID
$emailAddresses = $Null # Optional static list of CC recipients
▶️ How to Run
Open PowerShell as Administrator
Install Microsoft Graph module (if not already):Install-Module Microsoft.Graph -Scope CurrentUser
Multi-user CC: If different users need unique CCs, adapt the script to parse a ccRecipients column with user-specific values.
📤 Example Output
✅ Using device login for Microsoft Graph...
✅ Microsoft Graph is connected to the correct Azure tenant (xxxx-xxxx-xxxx).
✅ Invitation sent to Guest One using [email protected]
⚠️ Skipped a user due to missing email address.
⚠️ Failed to invite Guest Two: Insufficient privileges to complete the operation
🧽 Cleanup / Disconnect
Graph sessions are managed per execution. If needed, manually disconnect with: