Introduction
You can compile Desired State Configuration (DSC) configurations in Azure Automation State Configuration, which functions as a pull server. Next to doing this via the Azure portal, you can also use PowerShell. The latter allows for easy integration in DevOps pipelines and provides the flexibility to deal with complex parameter constructs. So, this is my preferred option. Of course, you can also push DSC configurations to Azure virtual machines via ARM templates. But I like the pull mechanisms for life cycle management just a bit more as we can update the DSC config and push it out when needed. So, that’s all good, but under certain conditions, you can get the following error: Cannot connect to CIM server. The specified service does not exist as an installed service.
When can you get into this pickle?
DSC itself is PowerShell, and that comes in quite handy. Sometimes, the logic you use inside DSC blocks is insufficient to get the job done as needed. With PowerShell, we can leverage the power of scripting to get the information and build the logic we need. One such example is formatting data disks. Configuring network interfaces would be another. A disk number is not always reliable and consistent, leading to failed DSC configurations.
For example, the block below is a classic way to wait for a disk, and when it shows up, initialize, format, and assign a drive letter to it.
xWaitforDisk NTDSDisk {
DiskNumber = 2
RetryIntervalSec = 20
RetryCount = 30
}
xDisk ADDataDisk {
DiskNumber = 2
DriveLetter = "N"
DependsOn = "[xWaitForDisk]NTDSDisk"
}
The disk number may vary depending on whether your Azure virtual machine has a temp disk or not, or if you use disk encryption or not can trip up disk numbering. No worries, DSC has more up its sleeve and allows to use the disk id instead of the disk number. That is truly unique and consistent. You can quickly grab a disk’s unique id with PowerShell like below.
xWaitforDisk NTDSDisk {
DiskIdType = 'UniqueID'
DiskId = $NTDSDiskUniqueId #'1223' #GetScript #$NTDSDisk.UniqueID
RetryIntervalSec = 20
RetryCount = 30
}
xDisk ADDataDisk {
DiskIdType = 'UniqueID'
DiskId = $NTDSDiskUniqueId #GetScript #$NTDSDisk.UniqueID
DriveLetter = "N"
DependsOn = "[xWaitForDisk]NTDSDisk"
}
Powershell in compilation error
So we upload and compile this DSC configuration with the below script.
$params = @{
AutomationAccountName = 'MyScriptLibrary'
ResourceGroupName = 'WorkingHardInIT-RG'
SourcePath = 'C:\Users\WorkingHardInIT\OneDrive\AzureAutomation\AD-extension-To-Azure\InfAsCode\Up\App\PowerShell\ADDSServer.ps1'
Published = $true
Force = $true
}
$UploadDscConfiguration = Import-AzAutomationDscConfiguration @params
while ($null -eq $UploadDscConfiguration.EndTime -and $null -eq $UploadDscConfiguration.Exception) {
$UploadDscConfiguration = $UploadDscConfiguration | Get-AzAutomationDscCompilationJob
write-Host -foregroundcolor Yellow "Uploading DSC configuration"
Start-Sleep -Seconds 2
}
$UploadDscConfiguration | Get-AzAutomationDscCompilationJobOutput –Stream Any
Write-Host -ForegroundColor Green "Uploading done:"
$UploadDscConfiguration
$params = @{
AutomationAccountName = 'MyScriptLibrary'
ResourceGroupName = 'WorkingHardInIT-RG'
ConfigurationName = 'ADDSServer'
}
$CompilationJob = Start-AzAutomationDscCompilationJob @params
while ($null -eq $CompilationJob.EndTime -and $null -eq $CompilationJob.Exception) {
$CompilationJob = $CompilationJob | Get-AzAutomationDscCompilationJob
Start-Sleep -Seconds 2
Write-Host -ForegroundColor cyan "Compiling"
}
$CompilationJob | Get-AzAutomationDscCompilationJobOutput –Stream Any
Write-Host -ForegroundColor green "Compiling done:"
$CompilationJob
So, life is good, right? Yes, until you try and compile that (DSC) configuration in Azure Automation State Configuration. Then, you will get a nasty compile error.
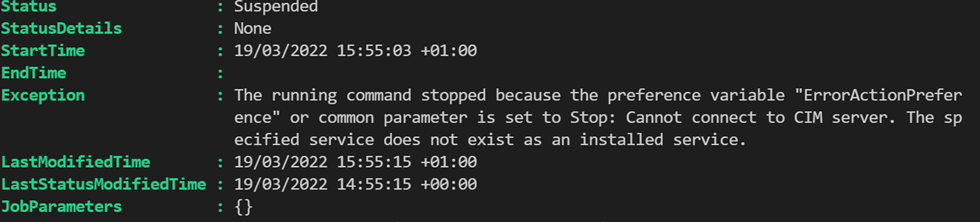
“Exception: The running command stopped because the preference variable “ErrorActionPreference” or common parameter is set to Stop: Cannot connect to CIM server. The specified service does not exist as an installed service.”
Or in the Azure Portal:
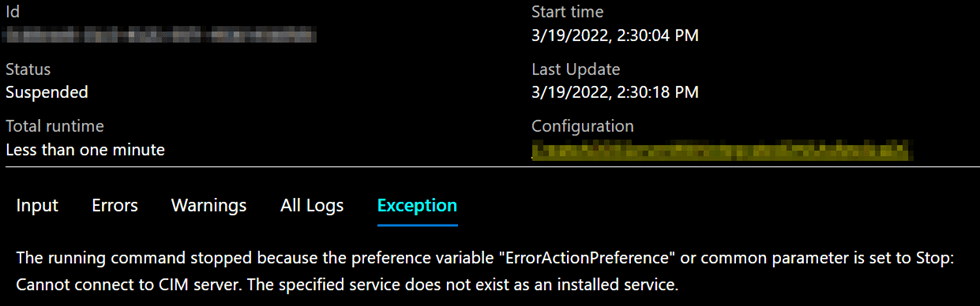
The Azure compiler wants to validate the code, and as you cannot get access to the host, compilation fails. So the configs compile on the Azure Automation server, not the target node (that does not even exist yet) or the localhost. I find this odd. When I compile code in C# or C++ or VB.NET, it will not fail because it cannot connect to a server and validate my code by crabbing disk or interface information at compile time. The DSC code only needs to be correct and valid. I wish Microsoft would fix this behavior.
Workarounds
Compile DSC locally and upload
Yes, I know you can pre-compile the DSC locally and upload it to the automation account. However, the beauty of using the automation account is that you don’t have to bother with all that. I like to keep the flow as easy-going and straightforward as possible for automation. Unfortunately, compiling locally and uploading doesn’t fit into that concept nicely.
Upload a PowerShell script to a storage container in a storage account
We can store a PowerShell script in an Azure storage account. In our example, that script can do what we want, find, initialize, and format a disk.
Get-Disk | Where-Object { $_.NumberOfPartitions -lt 1 -and $_.PartitionStyle -eq "RAW" -and $_.Location -match "LUN 0" } |
Initialize-Disk -PartitionStyle GPT -PassThru | New-Partition -DriveLetter "N" -UseMaximumSize |
Format-Volume -FileSystem NTFS -NewFileSystemLabel "NTDS-DISK" -Confirm:$false
From that storage account, we download it to the Azure VM when DSC is running. This can be achieved in a script block.
$BlobUri = 'https://scriptlibrary.blob.core.windows.net/scripts/DSC/InitialiseNTDSDisk.ps1' #Get-AutomationVariable -Name 'addcInitialiseNTDSDiskScritpBlobUri'
$SasToken = '?sv=2021-10-04&se=2022-05-22T14%3A04%8S67QZ&cd=c&lk=r&sig=TaeIfYI63NTgoftSeVaj%2FRPfeU5gXdEn%2Few%2F24F6sA%3D'
$CompleteUri = "$BlobUri$SasToken"
$OutputPath = 'C:\Temp\InitialiseNTDSDisk.ps1'
Script FormatAzureDataDisks {
SetScript = {
Invoke-WebRequest -Method Get -uri $using:CompleteUri -OutFile $using:OutputPath
. $using:OutputPath
}
TestScript = {
Test-Path $using:OutputPath
}
GetScript = {
@{Result = (Get-Content $using:OutputPath) }
}
}
But we need to set up a storage account and upload a PowerShell script to a blob. We also need a SAS token to download that script or allow public access to it. Instead of hardcoding this information in the DSC script, we can also store it in automation variables. We could even abuse Automation credentials to store the SAS token securely. All that is possible, but it requires more infrastructure, maintenance, security while integrating this into the DevOps flow.
PowerShell to generate a PowerShell script
The least convoluted workaround that I found is to generate a PowerShell script in the Script block of the DSC configuration and save that to the Azure VM when DSC is running. In our example, this becomes the below script block in DSC.
Script FormatAzureDataDisks {
SetScript = {
$PoshToExecute = 'Get-Disk | Where-Object { $_.NumberOfPartitions -lt 1 -and $_.PartitionStyle -eq "RAW" -and $_.Location -match "LUN 0" } | Initialize-Disk -PartitionStyle GPT -PassThru | New-Partition -DriveLetter "N" -UseMaximumSize | Format-Volume -FileSystem NTFS -NewFileSystemLabel "NTDS-DISK" -Confirm:$false'
$ PoshToExecute | out-file $using:OutputPath
. $using:OutputPath
}
TestScript = {
Test-Path $using:OutputPath
}
GetScript = {
@{Result = (Get-Content $using:OutputPath) }
}
}
So, in SetScript, we build our actual PowerShell command we want to execute on the host as a string. Then, we persist to file using our $OutputPath variable we can access inside the Script block via the $using: OutputPath. Finally, we execute our persisted script by dot sourcing it with “. “$using:OutputPath” In TestScript, we test for the existence of the file and ignore the output of GetScript, but it needs to be there. The maintenance is easy. You edit the string variable where we create the PowerShell to save in the DSC configuration file, which we upload and compile. That’s it.
To be fair, this will not work in all situations and you might need to download protected files. In that case, the above will solutions will help out.
Conclusion
Creating a Powershell script in the DSC configuration file requires less effort and infrastructure maintenance than uploading such a script to a storage account. So that’s the pragmatic trick I use. I’d wish the compilation to an automation account would succeed, but it doesn’t. So, this is the next best thing. I hope this helps someone out there facing the same issue to work around the error: Cannot connect to CIM server. The specified service does not exist as an installed service.