So what did we notice? VDI generates enough interest from various angles that is for sure. Both on the demand side as on the (re)seller & integrator side. Most storage vendors are bullish enough to claim that they can handle whatever IOPS required to get the most bang for the buck but only the smaller or newest players were present and engaged in interaction with the attendees. One thing is for sure VDI has some serious potential but it has to be prepared well and implemented thoroughly. Don’t do it over the weekend and see if it works out for all your users.
The amount of tools & tactics for VDI on both the storage side and the configuration/management side is both more complex and diverse than with server virtualization. The possible variations on how to tackle a VDI project are almost automatically more numerous as well. This is due to the fact that desktops are often a lot more complex and heterogenic in nature than server-side apps. On top of that, the IO on a desktop can be quite high. Some of it can be blamed on the client OS but lots of that has to do with the applications and utilities used on desktops. I think that developers had so many resources at their disposal that there wasn’t to much pressure on optimization there. The age of multi-cores and x64 bit will help in thinking more about how and application uses CPY cycles but virtualization might very well help in abstracting that away. When a PC has one vCPU and the host has 4*8 cores, how good is that hypervisor at using all that pCPU power to address the needs of that one vCPU? But I digress. All in all, it takes more effort and complexity to do VDI than server virtualization. So there is a higher cost or at least the APEX isn’t such a convincing clear cut story as it is with server virtualization. If you’re not doing the latter today when and where you can you are missing out of a major number of benefits that are just to good to ignore. I wouldn’t dare say that for VDI. Treating VDI just like server virtualization is said to be one of the main reasons for VDI failing or being put on hold or being limited to a smaller segment of the desktop population.
My experience with server virtualization is also with rather heterogenic environments where we have VMs with anything between 1 and 4 virtual CPUs, 2 to 12 GB of RAM. And yet I have to admit it has been a great success. Never the less I can’t say that helped me much in my confidence that a large part of our desktop environment can be virtualized successfully and cost-effectively as I think that our desktops are such vicious resource hogs they need another step forward in raw power and functionality versus cost. Let briefly describe the environment. 85% of the workforce at my current gig has dual 24” wide screens, with anything between 4GB to 8 GB of RAM, Quad-Core CPUs and SCSI / SATA 10.000 RPM disks with anything between 250 GB to 1TB local storage in combination with very decent GPUs. Now the employees run Visual Studio, SQL Server, multiple CAD & GIS packages, and various specialized image processing software that gauges image and other files that can be 2GB or even higher. If they aren’t that large than they are still very numerous. On top of that 1Gbps network to the desktop is the only thing we offer anymore. So this is not a common office suite plus a couple of LOB applications order, this is a large and rich menu for a very hard to please audiences. That means that if you ask them what they want, they only answer more, more, more … And I won’t even mention 3D screens & goggles.
Now I know that X amount of time the machines are idle or doing a lot less but in the end that’s just a very nice statistic. When a couple of dozen users start playing around with those tools and throw that data around you still need them and their colleagues to be happy customers. Frankly even with the physical hardware that they have now that can be a challenge. And please don’t start about better, less resource wasting applications and such. You can’t just f* the business and tell them to get or wait for better apps. That flies in the face of reality. You have to be able to deliver the power where and when needed with the software they use. You just can’t control the entire universe.
I heard about integrators achieving 40-60 VMs per host in a VDI project. Some customers can make due with Windows 7 and 1GB of RAM. I’m not one of those. I think the guys & gals of the service desk would need armed escorts if we rolled that out to the employees they care for. One of the things I notice is that a lot of people choose to implement storage just for VDI. I’m not surprised. But until now I’ve not needed to do it. Not even for databases and other resource hogs. Separate clusters, yes, as the pCPU/vCPU ratio and Memory requirements differ a lot from the other servers. The fact that the separate cluster uses other HBA’s en LUNS also helps.
Next to SANs local storage for VDI is another option for both performance and cost. But for recovery, this isn’t quite that good a solution. The idea of having non-persistent disks (in a pool) or a combination of that with persistent disks is not something I can see fly with our users. And frankly, a show of hands at BriForum seems to indicate that this isn’t very widespread. VDI takes really high-performance storage, isolated from your server virtualization to make it a success. On top of that if you need control, rapid provisioning, user virtualization & workspace management in a layered/abstracted way. Lost of interest there but again, yet more tools to get it done. Then there is also application virtualization, terminal service-based solutions etc. So we get a more involved, divers, and expensive solution compared to server virtualization. Now to offset these costs we need to look at what we can gain. So where do the benefits to be found?
With non-persistent disk you have rapid provisioning of know good machines in a pool but your environment must accept this and I don’ see this flying well in face of the reality of consumerization of ICT. De-duplication and thin provisioning help to get the storage needs under control but the bigger the client-side storage needs and the more diverse these are the fewer gains can be found there. Better control, provisioning, resource sharing, manageability, disaster recovery, it is all possible but it is all so very specific to the environment compared to server virtualization and some solutions contradict gains that might have been secured with other approaches (disaster recovery, business continuity with SAN versus local storage). One of the most interesting possibilities for the environment I described was perhaps doing virtualization on the client. I look at it as booting from VHD in the Windows 7 era but on steroids. If you can save guard the images/disks on a SAN with de-duplication & thin provisioning you can have high availability & business continuity as losing the desktops is a matter of pushing to VM to other hardware which due to abstraction by virtualization should be a problem. It also deals with the network issues of VDI, a hidden bottleneck as most people focus on the storage. Truth be told, the bandwidth we consume is that big, it could be that VDI might have it best improvements for us on that front.
Somewhat surprising was that Microsoft, whilst being really present at PubForum in Dublin, was nowhere to be seen at BriForum. Citrix was saving it’s best for its own conference (Synergy) I think. Too bad, I mean when talking about VDI in 2011 we’re talking about Windows 7 for the absolute majority of implementations and Citrix has a strong position in VDI really giving VMware a run for their money. Why miss the opportunity? And yesterday at TechEd USA we heard about the HSBC story of a 100.000 seat VDI solution on Hyper-V http://www.microsoft.com/Presspass/press/2011/may11/05-16TechEd11PR.mspx.
On a side note, I wish I would/could have gone to PubForum as well. Should have done that. Now, these musings are based upon what I see at my current place of endeavor. VDI has a time and place where it can provide significant operational and usage advantages to make the business case for VDI. Today, I’m not convinced this is the case for our needs at this moment in time. looking at our refresh schedule we’ll probably pass on a VDI solution for the coming one. But booting from VHD as a standard in the future… I’m going to look into that, it will be a step towards the future I think.
To conclude BriForum 2011 was a good experience and the smaller scale of it makes for good and plenty of opportunities for interaction and discussion. A very positive note is that most vendors & companies present were discussing real issues we all face. So it was more than just sales demos. Brian, nice job.

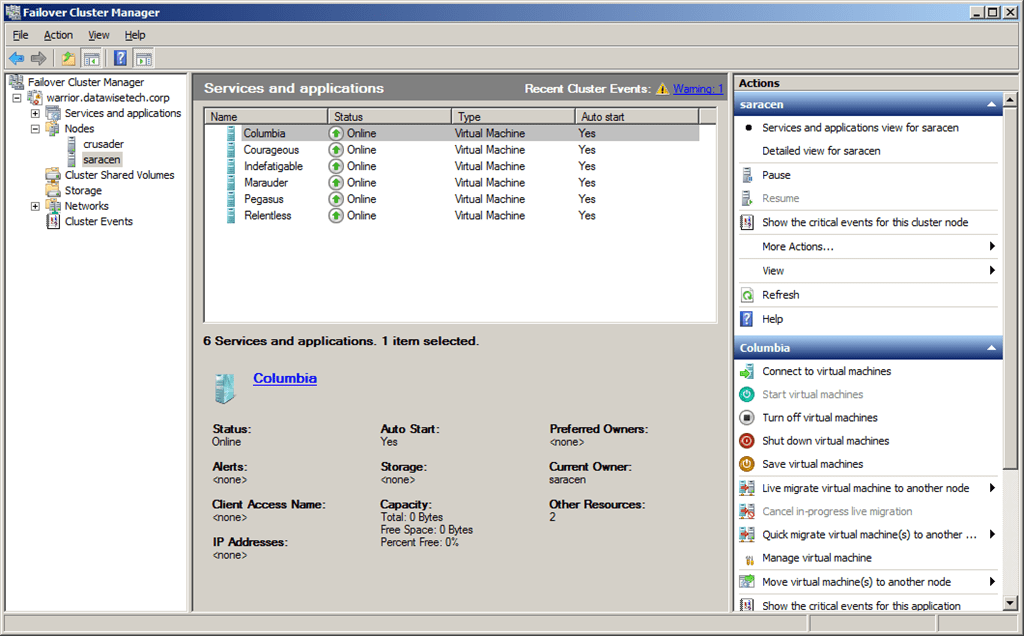
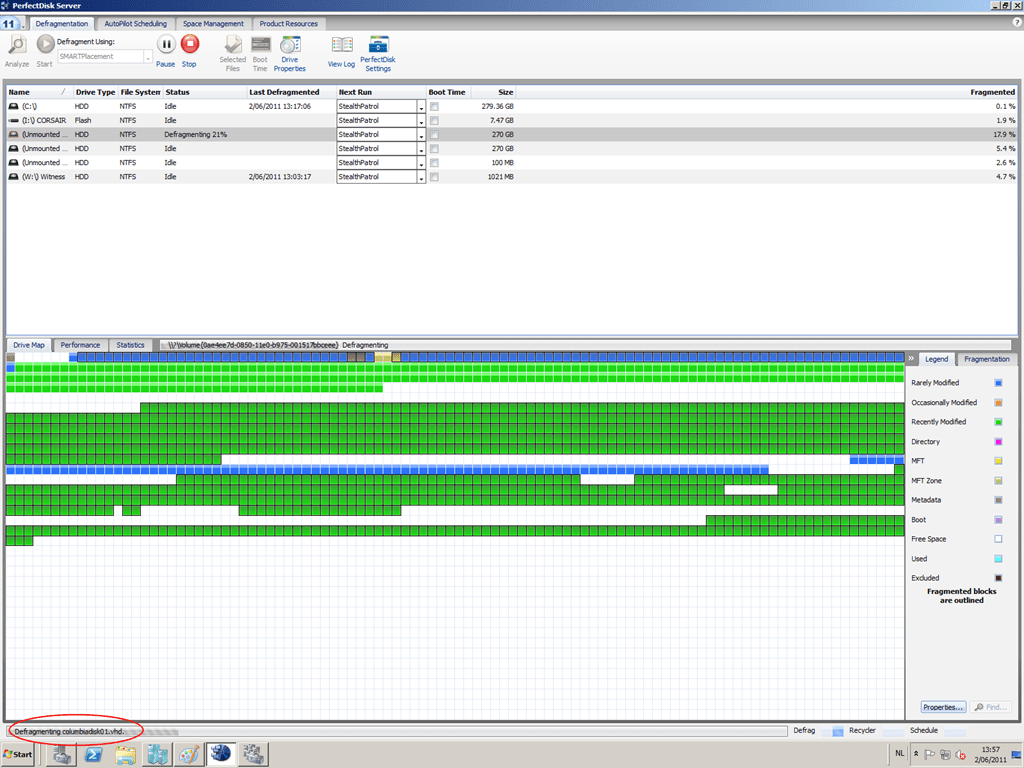
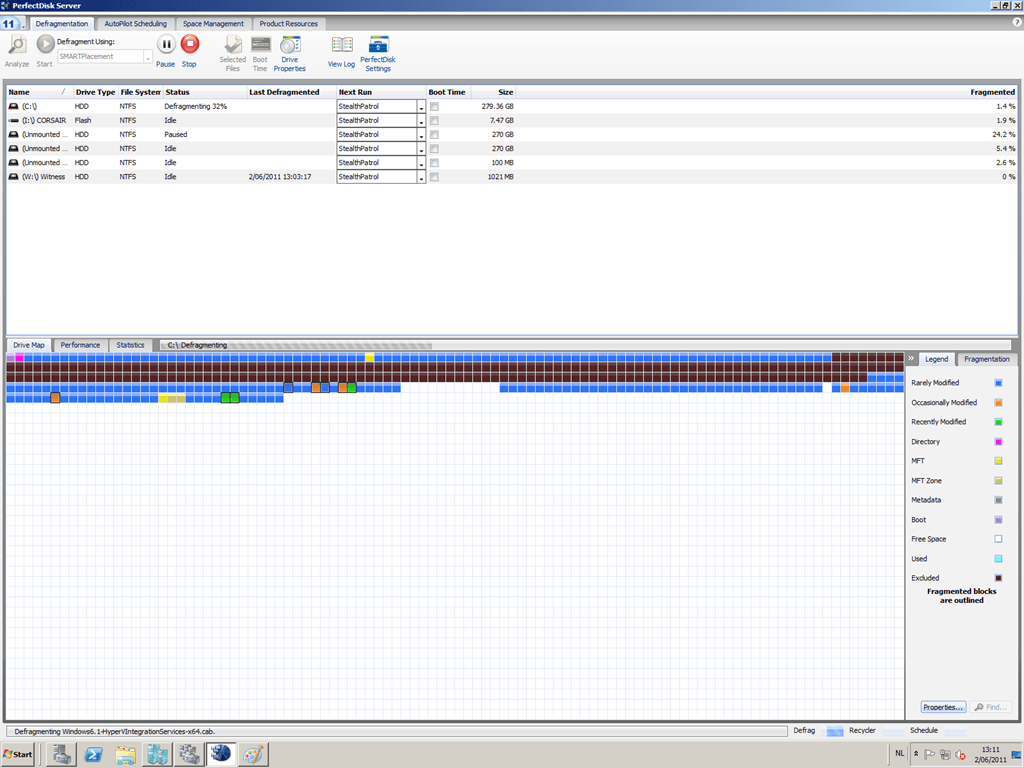 Here you can see that the guest files are indeed being defragmented, in this case, the VHD for the guest server Columbia (red circle at the bottom):
Here you can see that the guest files are indeed being defragmented, in this case, the VHD for the guest server Columbia (red circle at the bottom):