Happy New Year! Today we welcome 2019. I wish all my readers the best for 2019. May your hikes and journeys, both recreational & inspirational, lead you to beautiful places and gorgeous views to behold. Enjoy the experience, the adventure and efforts along the way to get there. Be grateful you have the abilities to do so.
Me relaxing after hiking up and down the trail network at Lake O’Hara in Yoho National Park (yes ,we got a golden ticket and were allowed in for hiking those gorgeous trails) – I just love the Rockies and RoCE
As I welcome 2019, I’ll be diving into some interesting technologies, trends & strategies to investigate, discuss, implement and advise on. Join me on my journey in 2019!
When you have upgraded your SC Series SAN to SCOS 7.3 (7.3.5.8.4 at the time of writing, see https://blog.workinghardinit.work/2018/SCX08/13/sc-series-scos-7-3/ ) you are immediately ready to start utilizing the SCOS 7.3 distributed spares feature. This is very easy and virtually transparent to do.
7.3 on an SC-7020 AFA
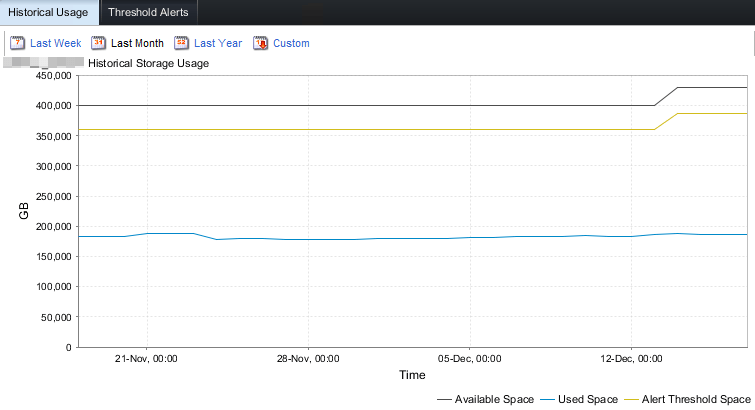
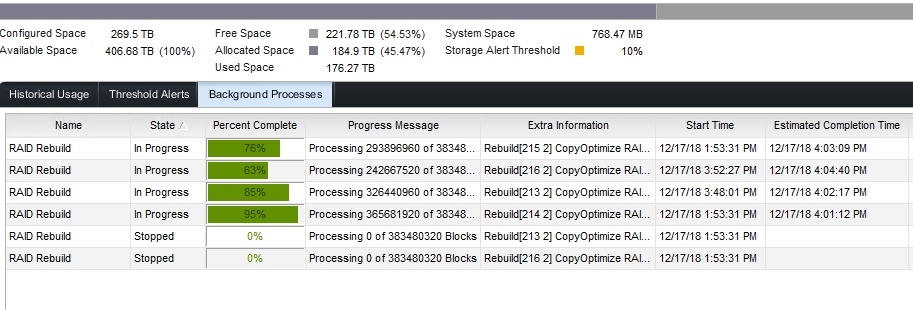
You will actually notice a capacity and treshhold jump in your SC array when you upgraded to 7.3. The system now know the spare capacity is now dealt with differently.
Usable space and alert threshold increase right after upgrading to SCOS 7.3
How?
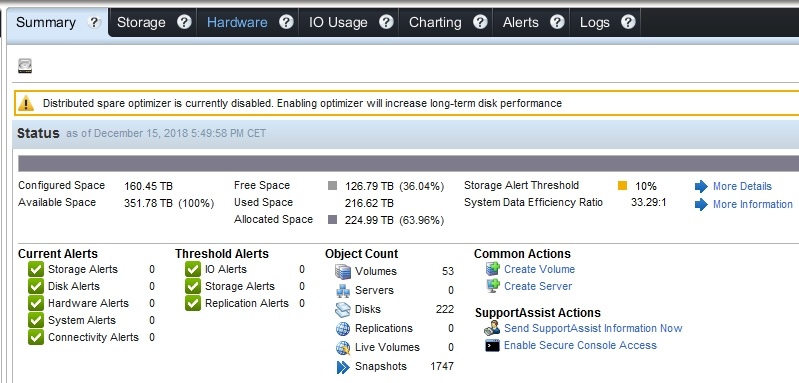
After upgrading you’ll see a notification either in Storage Manager or in Unisphere Central that informs you about the following:
“Distributed spare optimizer is currently disabled. Enabling optimizer will increase long- term disk performance.”
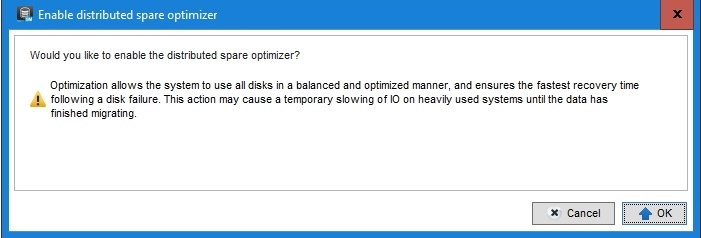
Once you click enable you’ll be asked if you want to proceed.
When you click “OK” the optimizer is configured and will start its work. That’s a one way street. You cannot go back to classic hot spares. That is good to know but in reality, you don’t want to go back anyway.
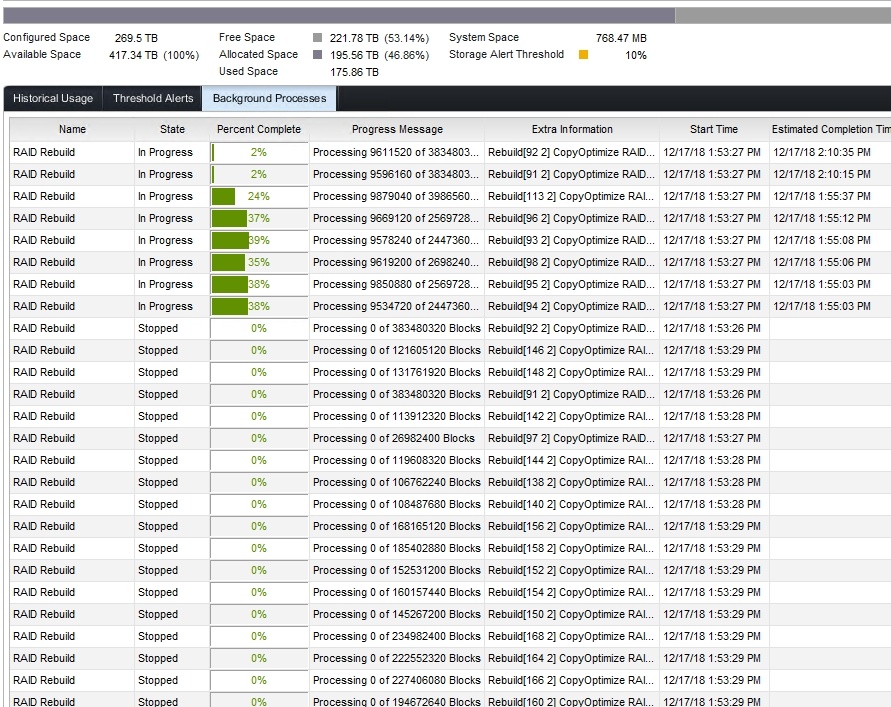
In “Background Processes” you’ll be able to follow the progress of the initial redistribution. This goes reasonabely fast and I did 3 SANs during a workday. No one even noticed or complained about any performance issues.
The Raid rebuild starts … RAID rebuild near the end … it took about 2-3 hours on All Flash Arrays.
The benefits are crystal clear
The benefits of SCOS 7.3 Distributed Spares are crystal clear:
Better performance. All disks contribute to the overall IOPS. There are no disks idling while reserved as a hot spare. Depending on the number of disks in your array the number of hot spares adds up. Next up for me is to rerun my base line performance test and see if I can measure this.
The lifetime of disks increases. On each disk, a portion is set aside as sparing capacity. This leads to an extra amount of under-provisioning. The workload on each of the drives is reduced a bit and gives the storage controller additional capacity from which to perform wear-leveling operations thus increasing the life span.
Faster rebuilds. This is the big one. As we can now read AND write to many disks the rebuild speed increases significantly. With ever bigger disks this is something you need and what was long overdue. But it’s here! It also allows for fast redistribution when a failed disk is replaced. On top of that when a disk is marked suspect the before it fails. A copy of the data takes place to spare capacity and only when that is done is the orginal data on the failing disk taken out fo use and is the disk marked as failed for replacement. This copy operation is less costly than a rebuild.
In the previous blog post, we moved from RAID to AHCI. Moving from AHCI to RAID can also be achieved without reinstalling Windows. With my NVME disk, I have not seen a huge performance difference between AHCI with the native Windows driver and RAID with Intel RST. If, however, you want to move back from AHCI to RAID when newer drivers become available this is also possible. Depending on your approach it can be a more tedious process with some risk, but normally you can always fall back to AHCI if it doesn’t work out and, otionally, try another approch.
I personally have used other ways to do this. Manipulating some registry settings in combination with a safe boot before booting normally does the trick as well. This works with both SATA SSD and M.2 NVMe drives and it enables relatively fast switching between back and forth between AHCI and RAID. I have described this method below. I have also tried the same process used to switch from RAD to AHCI and that works as well.
Switch to safe boot
Reboot into BIOS
Change from AHCI to RAID in the BIOS
Boot into safe mode
Turn off safe mode and reboot normally again
Nothing else and that also did the trick, just like with moving from RAID to AHCI. So the link above and my step by step below is here for completeness. You have options in case one of them doesn’t work!
Step by step AHCI to RAID registry method
This procedure I describe below works on Windows 10 1803/1809 and has been tested on Dell Latitude E6220 an XPS 13 9360. Editing the registry is always a little risky if you have no clue what you are doing. So, beware if you mess up and can’t figure out how to get out of this pickle, you might need to redeploy/restore from backup.
To change the SATA operation mode from AHCI to RAID follow the steps below.
Prepping the registry settings
Open the registry editor regedit
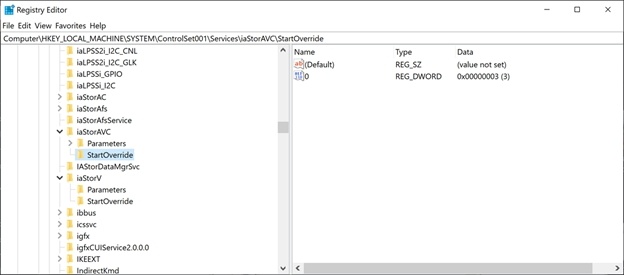
Navigate to HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSetXXX\Services\and find the some of the keys that are below (not all will exist depending on your laptop’s configuration):
You can put all these to 0 if you want, that doesn’t matter but normally you’ll know which one matters. AHCI is easy, there is only one entry. For the iaStor options I know I need aiStorAVC as the one I see in device manager and in the WinDbg MEMORY.DMP analysis is iaStorAVC.sys in my previous blog post.
When you find a StartUpOverride sub key and it is set to 3 also change this to 0 for the value you want to switch to.
Just make sure you set the one you need to 0 as then it will be picked up when you switch between AHCI/RAID in the BIOS. If you’re in you can set them all to 0 as the setting in the BIOS will pick up the correct one and windows will reset the StartupOverride value where needed.
When changing values in CurrentControl001 or 002 make sure you know the one that is being used. You can find that inHKEY_LOCAL_MACHINE\SYSTEM\Select in the value named Current. If it is 1 edit CurrentControl001 if its 2 edit CurrentControl002 (that key might not even exist).
Making sure you go into safeboot mode
After changing the registry setting set the default boot mode to Safe Mode, use msconfig.exe or open an admin cmd/PowerShell window and run: bcdedit/set ‘{current}’ safeboot minimal
Reboot and hit F2 to enter the BIOS.
Change the SATA mode to RAID.
Save and reboot.
After Windows successfully boots into Safe Mode, disable Safe Mode with msconfig.exe or open an admin cmd/PowerShell window and run: bcdedit /deletevalue ‘{current}’safeboot
Reboot again.
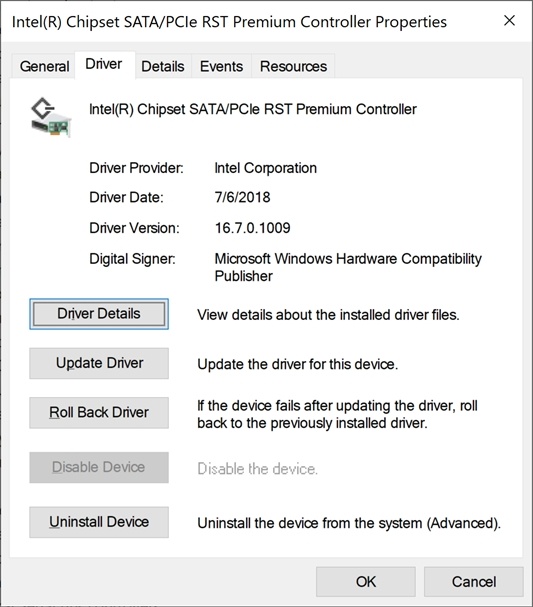
Log in and verify in Device Manager, that you now have the Intel Chipset SATA RAID Controller device under Storage Controllers.
Updating the Intel RST driver
You are now back to RAID but are still at the driver level that is causing your BSODs. Mine was 15.9.
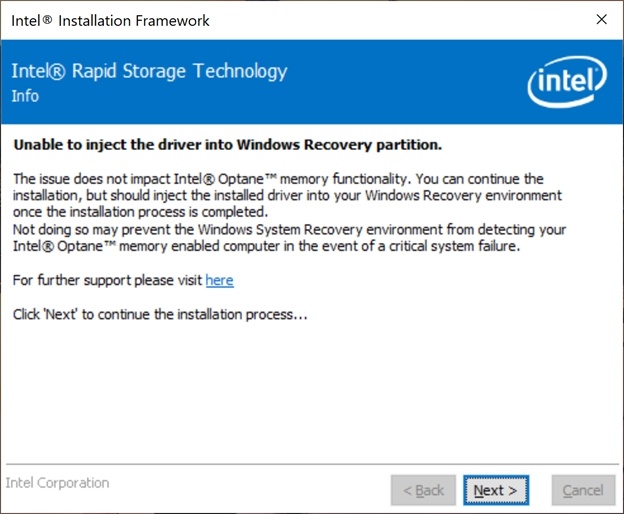
To fix that you need to upgrade your Intel RST driver. While doing so you might get a warning about being unable to inject the driver into the recovery partition but you can ignore this and take care of that later.
Now reboot again and check the storage controller now in device manager. You’ll find an Intel Chipset SATA/PCIe RST Premium Controller now with driver version 16.7.0.1009 at the time of writing and that is the one I used and which fixed the BSODs for me when using RAID. Now DELL also releases updates on their support site you can try. If that doesn’t fix it, grab a more recent one from Intel if you can find one to try. That is what I did here.
The old AHCI disk is still visible when you enable show hidden devices but also shows the disk name as know to the Intel Chipset SATA/PCIe RST Premium Controller.
Important
Note that if you have a BSOD during the installation don’t despair, try again and after a successful run and reboot you’ll have the new driver. Then you’ll have to work on the laptop and see if it still blue screens. If so, revert back to AHCI.
I hope this helps someone out there, including my future self.
The good news is you do not need to reinstall Windows to move from RAID to AHCI. You just need to do it right and in the correct order to make this pretty straightforward.
As you might recall from my previous blog DELL XPS Laptops and seemingly random Blue Screens of Death the reason for moving to AHCI is that our laptop blue screens on the iaStorAVC.sys driver of the Intel Rapid Storage Technology when in SATA RAID mode. If an update is not available or doesn’t help we can move to SATA AHCI mode and avoid any more BSOD due to the Intel RST driver.
To move from RAID to AHCI is surprisingly easy. All that’s needed is a successful boot to Safe Mode after switching from RAID to AHCI in the BIOS settings. It is important you first boot into safe mode after making the change in the BIOS. This process was tested with an XPS 13 9360 and a lab Lattitude E6220. The process, step by step, is as follows.
To set the default boot mode to Safe Mode, usemsconfig.exe or open an admin cmd/PowerShell window and run: bcdedit /set ‘{current}’ safeboot minimal
Reboot and hit F2 to enter the BIOS.
Change the SATA mode to AHCI.
Save and reboot.
After Windows successfully boots into Safe Mode, disable Safe Mode with msconfig.exe or open an admin cmd/PowerShell window and run: bcdedit /deletevalue ‘{current}’safeboot
Reboot again.
Log in and verify in Device Manager, that you now have the Standard NVM Express Controller device under Storage Controllers.
After moving to SATA AHCI
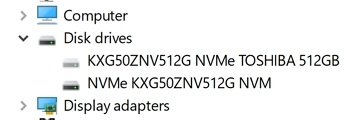
The performance with my KXG50ZNV512G NVMe Toshiba disk is still OK. Not as good as it could be but that’s reality for you. It’s worth to note that DELL does not officially support other NVMe drivers than the inbox Windows one for AHCI mode. Not saying you cannot try to install them but thenyou would be out of support. As noted above, standard these laptops come with RAID mode enabled by default. AHCI is supported and sometimes even needed (dual boot with Linux for example).
Anyway, things work and perform well. They are also stable and that is of utmost performance for me. If at a later date you want to move to RAID again read the next blog: Moving from AHCI to Raid