This is a 3th post in a series of 4. Here’s a list of all parts:
- Introducing 10Gbps Networking In Your Hyper-V Failover Cluster Environment (Part 1/4)
- Introducing 10Gbps With A Dedicated CSV & Live Migration Network (Part 2/4)
- Introducing 10Gbps & Thoughts On Network High Availability For Hyper-V (Part 3/4)
- Introducing 10Gbps & Integrating It Into Your Network Infrastructure (Part 4/4)
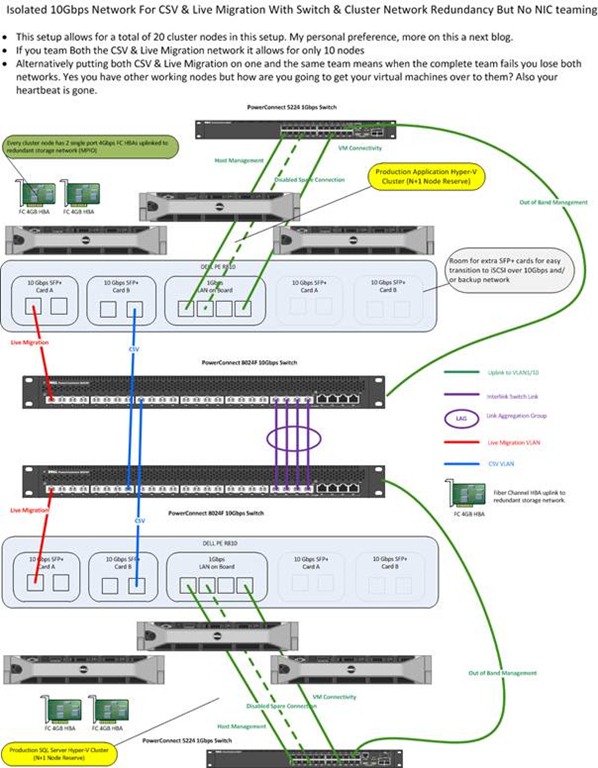
As you saw in my previous blog post “Introducing 10Gbps With A Dedicated CSV & Live Migration Network (Part 2/4)” we created an isolated network for Hyper-V cluster networking needs, i.e. Heartbeat, Cluster Shared Volume and Live Migration traffic. When you set up failover clustering you’re doing so to achieve some level of high availability. We did this by using 2 switches and setting up redundant paths to them, making use of the fault tolerance the cluster networks offer us. The darks side of high availability is that is always exposes the next single point of failure and when it comes to networking that means you’ll need redundant NICs, NIC ports, cabling and switches. That’s what we’ll discuss in this blog post. All the options below are just that. There is never an obligation to use them everywhere and it might be not needed depending on the type of network and the business needs we’re talking about. But one thing I have learned is to build options into your solutions. You want ways and opportunities to work around issues while you fix them.
Redundant Switches
The first thing you’ll need to address is the loss of a switch. The better ones have redundant power supplies but that’s about it. So you’ll need to have (at least) two switches and make sure you have redundant connections to both switches. That implies both switches can talk to each other as they form one functional unit even when it is an isolated network as in our example.
One of the ways we can achieve this is by setting up a Link Aggregation Group (LAG) over Inter Switch Links (ISL). The LAG makes all the connections available between the switches for the VLANs you define. There are different types of LAG but one of the better ones is a LAG with LACP.
Stacking your switches might also be a solution if they support that. You might need stacking modules for that. Basically this turns two or more switches into one big switch. One switch in the stack acts as the master switch that maintains the entire stack and provides a single configuration and monitoring point. If a switch in the stack fails the remaining switches will bypass the failed switch via the stacking modules. Depending on the quality of your network equipment you can have some disruption during a the failure of the master switch as then another switch needs to take on that role and this can take anything between 3 seconds and a minute depending on vendor, type, firmware, etc. Network people like this. And as each switch contains the entire the stack configuration it’s very easy to replace a dead switch in a stack. Just rip out the dead one, plug in the replacement one and the stack will do the rest.
We note that more people have access to switches that can handle LAGs versus those who have stackable ones. The reason for this is that the latter tend to be more pricy.
Redundant Network Cards & Ports
Now whether you’re using LAGs or stacking the idea is that you connect your NICs to different switches for redundancy. The question is do we need to do something with the NIC configuration or not to benefit from this? Do we have redundancy in via a cluster wide virtual switch or not? If not can we use NIC teaming? Is NIC teaming always needed or a good idea? Ok, let’s address some of these questions.
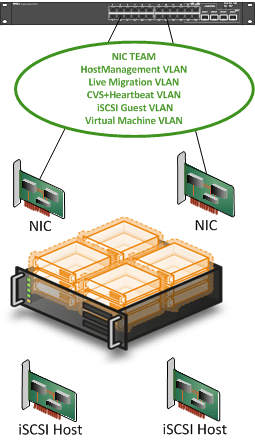
First of all, Hyper-V in the current Windows Server 2008 SP1 version has no cluster wide virtual switch that can provide redundancy for your virtual machine network(s). But please allow me to dream about Hyper-V 3.0. To achieve redundancy for the virtual machine networks you’ll need to turn to NIC teaming. NIC teaming has various possible configurations depending on vendor and the capabilities of the switches in use. You might be familiar with terminology like Switch Fault Tolerance (SFT), Adaptive Fault Tolerance (AFT), Link Aggregation Control protocol (LACP), VM etc. Apart from all that the biggest thing to remember is that NIC teaming support has to come from the hardware vendor(s). Microsoft doesn’t support it directly for Hyper-V and Hyper-V gets assess to a NIC team NIC via the Windows operating system.
On NIC Teaming
I’m going to make a controversial statement. NIC teaming can be and is often a cause of issues and it can expensive in time to both set up and fix if it fails. Apart from a lot of misconceptions and terminology confusion with all the possible configurations we have another issue. NIC teaming introduces complexity with drivers & software that is at least a hundred fold more likely to cause failures than today’s high quality network cards. On top of that sometimes people forget about the proper switch configuration. Ouch!
Do a search on Hyper-V and NIC teaming and you’ll see the headaches it causes so many people. Do you need to stay away from it? Is it evil? No, I’m not saying that. Far from that, NIC teaming is great. You need to decide carefully where and when to use it and in what form. Remember when you can handle & manage the complexity need to achieve high availability, generally speaking you’re good to go. If complexity becomes a risk in itself, you’re on the wrong track.
Where do I stand on NIC teaming? Use it when it really provides the benefits you seek. Make sure you have the proper NICs, Switches and software/drivers for what you’re planning to do. Do your research and test. I’ve done NIC Teaming that went so smooth I never would have realized the headaches it can give people. I’ve done NIC teaming where buggy software and drivers drove me crazy.
I’d like to mention security here. Some people tend to do a lot of funky, tedious configurations with VLANS in an attempt to enhance security. VLANS are not security mechanisms. They can be used in a secure implementation but by themselves they achieve nothing. If you’re doing this via NIC teaming/VLANS I’d like to note that once someone has access to your Hyper-V management console and /or the switches you’re toast. Logical and physical security cannot be replaced or ignored.
NIC Teaming To Enhance Throughput
You can use NIC teaming enhance bandwidth/throughput. If this is you major or only goal, you might not even be worried about using multiple switches. Now NIC teaming does help to provide better bandwidth but, sure but nothing beats buying 10Gbps switches & NICs. Really, switches with LAGs or stack and NIC Teaming are great but bigger pipes are always better for raw throughput. If you need twice or quadruple the ports only for extra bandwidth this gets expensive very fast. And if, on top of that, you need consultants because you don’t have a network engineer to set it all up just for that purpose, save your money and invest it in hardware.
NIC Teaming For Redundancy
Do you use NIC teaming for redundancy? Yes, this is a very good reason when it fits the needs. Do you do this for all networks? No, it depends. Just for heartbeat, CSV & Live migration traffic it might be overkill. The nature of these networks in a Hyper-V Cluster is such that you don’t really need it as they can mutually provide redundancy for each other. But what if a NIC port fails when I’m doing a live migration? Won’t that mean the live migration will fail? Yes. But once the NIC is out of the picture Live Migration will just work over the CSV network if you set it up that way. And you’re back in business while you fix the issue. Have I seen live migration fail? Yes, sure. But it never left the VM messed up, that kept running. So you fix the issue and Live Migrate it again.
The same goes for the other networks. CSV should not give you worries. That traffic gets queued and send to the next available network available for CSV. Heart beat is also not an issue. You can afford the little “down time” until it is sent over the next available network for cluster communication. Really a properly set up cluster doesn’t go down when a cluster networks fails if you have multiple of them.
But NIC teaming could/would prevent even this ever so slight interruption you say. It can, yes, depending on how you set this up, so not always by definition. But it’s not needed. You’re preventing something benign at great cost. Have you tested it? Is it always a lossless, complete transparent failover? No a single packet dropped? Not one ping failed? If so, well done! At what cost and for what profit did you do it? How often do your NICs and switch ports fail? Not very often. Also remember the extra complexity and the risk of (human) configuration errors. As always, trust but verify, testing is your friend.
Paranoia Is Your Friend
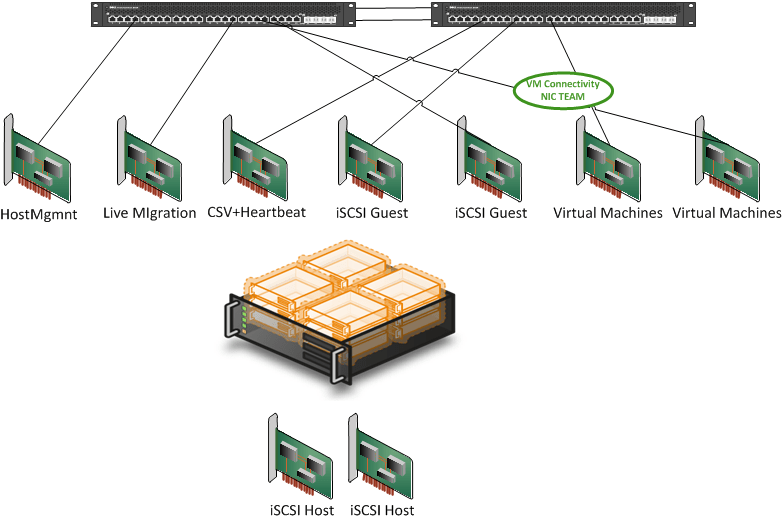
If you set up NIC teaming without separate NIC cards (not ports) and the PCIe slot goes bad NIC teaming won’t save you. So you need multiple network cards. On top of that, if you decide to run all networks over that team you put all your eggs in that one basket. So perhaps you might need 2 teams distributed over multiple NIC cards. Oh boy redundancy and high availability do make for expensive setups.
Combine NIC Teaming & VLANS Work Around Limited NIC Ports
This can be a good idea. As you’ll be pushing multiple networks (VLANs) over the same pipe you want redundancy. So NIC teaming here can definitely help out. You’ll need to consider the amount of network traffic in this case as well. If you use load balancing NIC teaming you can get some extra bandwidth, but don’t expect miracles. Think about the potential for bottle necks, QoS and try to separate bandwidth hogs on separate teams. And remember, bigger pipes are always better, so consider 10Gbps when you are in a bandwidth crunch.
Don’t Forget About The Switches
As a friendly reminder about what we already mentioned above, don’t forget to use different switches for up linking the NIC ports. If you do forget your switch is the single point of failure (SPOF). Welcome to high availability: always hitting the net SPOF and figuring out how big the risk is versus the cost in money and complexity to deal with it J. Switches don’t often fail but I’ve seen sys admins pull out the wrong PDU cables. Yes human error lures in all corners in all possible variations. I know this would never happen to you, and certainly not twice, but other people are not so skillful. And for those who’d rather be lucky than good I have bad news. Luck runs out. Inevitably bad things happen to all of our systems.
Some Closings Thoughts
One rule of thumb I have is not to use NIC teaming to save money by reducing NIC Cards, NIC ports, number of switches or switch ports. Use it when it serves your needs and procure adequate hardware to achieve your goals. You should do it because you have a real need to provide the absolute best availability and then you put down the money to achieve it. If you talk the talk, you need to walk the walk. And while not the subject of this post, your Active Directory or other core infrastructure services are not single points of failure , are they? 
If you do want to use it to save money or work around a lack of NIC ports, there is nothing wrong with that, but say so and accept the risk. It’s a valid decision when you have you have your needs covered and are happy with what that solution provides.
When you take all of this option into consideration, where do you end with NIC teaming and network solutions for Hyper-V clusters? You end up with the “Business ready” or “reference architecture” offered by DELL or HP. They weigh all pros and cons against each other and make a choice based on providing the best possible solution for the largest number of customers at acceptable costs. Is this the best for you? That could very well be. It all depends. They make pretty good configurations.
I tend to use NIC teaming only for the Virtual Machine networks. That’s where the biggest potential service interruption exists. I have in certain environments when NIC teaming was something that was not chosen mediated that risk by providing 2 or 3 single NIC for 2 or 3 virtual networks in Hyper-V. That reduced the impact to 1/3 of the virtual machines. And a fix for a broken NIC is easy; just attach the VMs to a different virtual network. You can do this while the virtual machines are running so no shutdown is required. As an added benefit you balance the network traffic over multiple NICs.
10Gbps with NIC teaming and VLANs provide for some very nice scenarios. This is especially true especially if you have bandwidth hungry applications running in boatload of VMs. This all means that we need to start thinking and talking about integrating the 10Gbps switches in our network infrastructure. So that means we’re entering the network engineers their turf and we’ll need to address some of their concerns. But this is not bad news as they’ll help us prevent some bad scenarios. But that will be discussed in a next blog post.