
Introduction
Today I focus on Veeam File Share backups and knowledge worker data testing. In Veeam NAS and File Share Backups did my 1st testing with the RTM bits of Veeam Backup & Replication V10 File Share backup options. Those tests were focused on a pain point I encounter often in environments with lots of large files: being able to back them up at all! Some examples are medical imaging, insurance, and GIS, remote imaging (satellite images, Aerial photography, LIDAR, Mobile mapping, …).
The amount of data created has skyrocketed driven by not only need but the advances in technology. These technologies deliver ever-better quality images, are more and more affordable, and are ever more applicable in an expanding variety of business cases. This means such data is an important use case. Anyway for those use cases, things are looking good.
But what about Veeam File Share backups and knowledge worker data? Those millions of files in hundreds of thousands of folders. Well, in this blog post I share some results of testing with that data.
Veeam File Share backups and knowledge worker data
For this test we use a 2 TB volume with 1.87TB of knowledge worker data. This resides on a 2 TB LUN, formatted with NTFS and a unit allocation size of 4K.
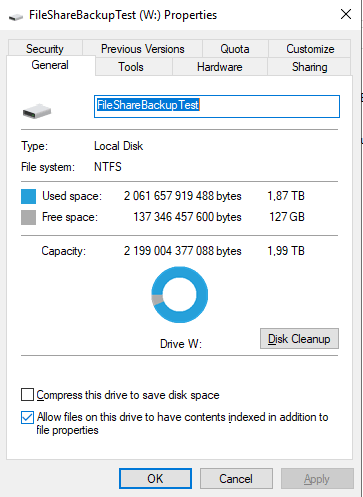
The data consists of 2,637,652 files in almost 196,420 folders. The content is real-life accumulated data over many years. It contains a wide variety of file types such as office, text, zip, image, .pdf, .dbf, movie, etc. files of various sizes. This data was not generated artificially. All servers are Windows Server 2019. The backup repository was formatted with ReFS (64K allocation unit size).
Backup test
We back it up with the file server object from an all-flash source to an all-flash target. There is a dedicated 10Gbps backup network in the lab. As we did not have a separate spare lab node we configured the cache on local SSD on the repository. I set the backup I/O control for faster backup. We wanted to see what we could get out of this setup.
Below are the results.
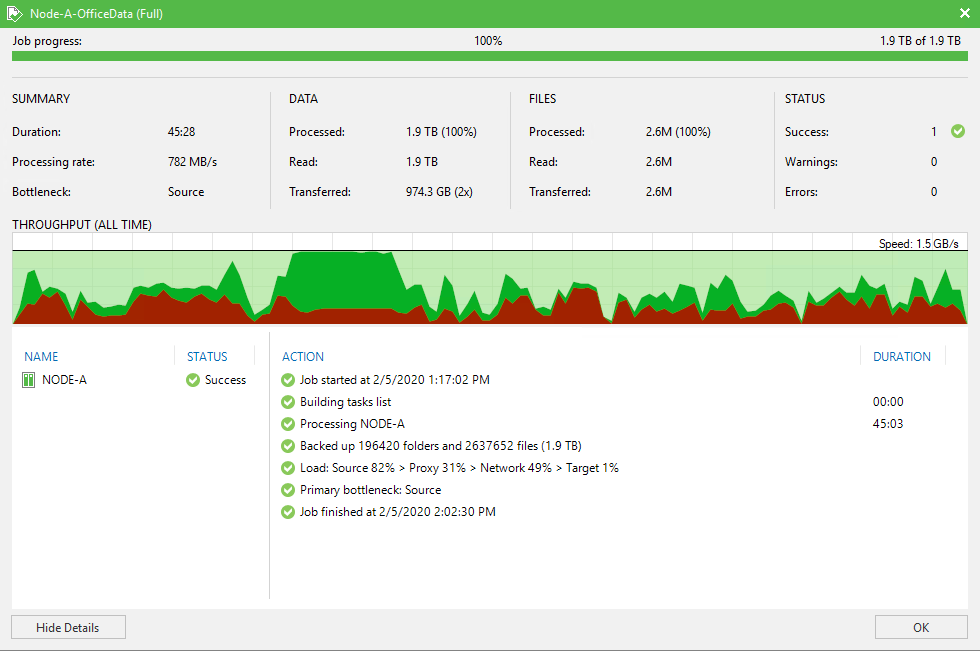
If you look at the back-up image above you see that the source was the bottleneck. As we are going for maximum speed we are hammering the CPU cores quite a bit. The screenshot below makes this crystal clear.
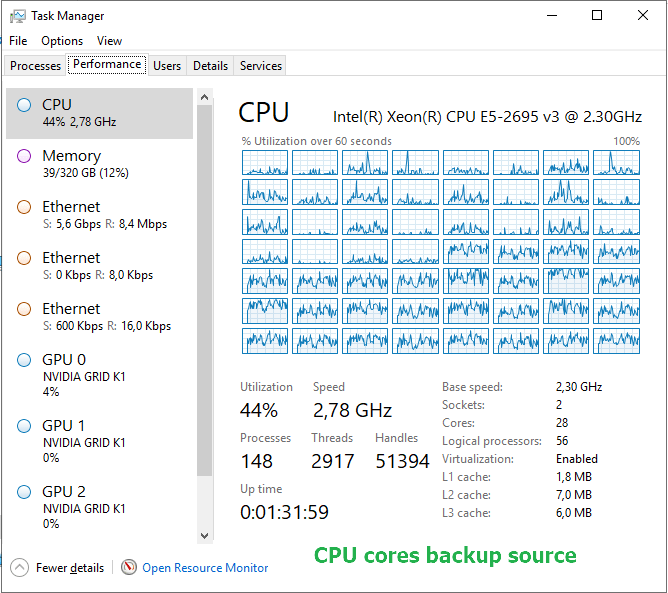
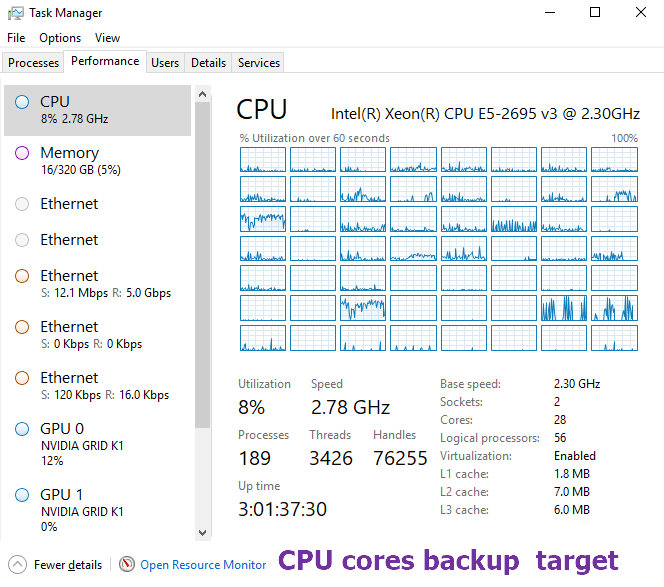
This begs the question if using the file share option would not be a better choice. We can then leverage SMB Direct. This could help save CPU cycles. With SMB Multichannel we can leverage two 10Gbps NICs. So We will repeat this test with the same data. Once with a file share on a stand-alone file server and once with a high available general-purpose file share with continuous availability turned on. This will allow us to compare the File Server versus File Share approach. Continuous availability has an impact on performance and I would also like to see how profound that is with backups. But all that will be for a future blog post.
Restore test
The ability to restore data fast is paramount. It is even mission-critical in certain scenarios. Medical images needed for consultations and (surgical) procedures for example.
So we also put this to the test. Note that we chose to restore all data to a new LUN. This is to mimic the catastrophical loss of the orginal LUN and a recovery to a new one.
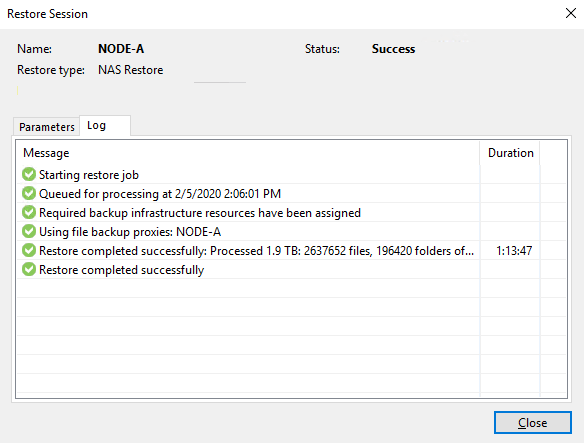
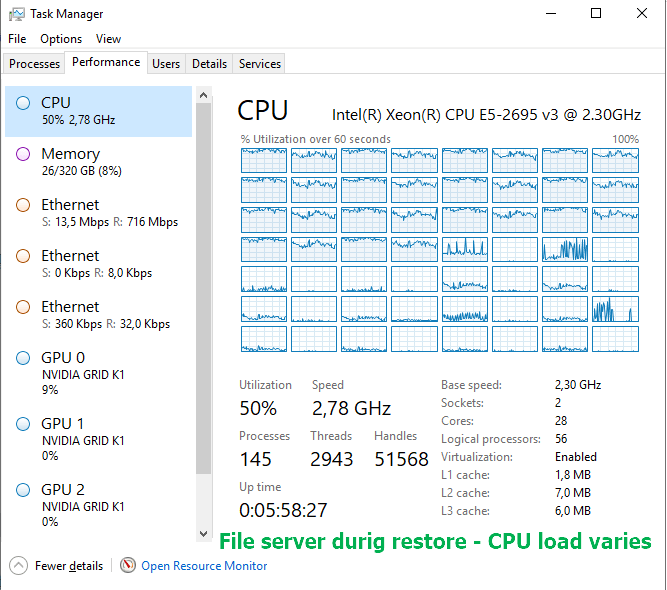
Below you will find a screenshot from the task manager on both the repository as well as the file server during the restore.
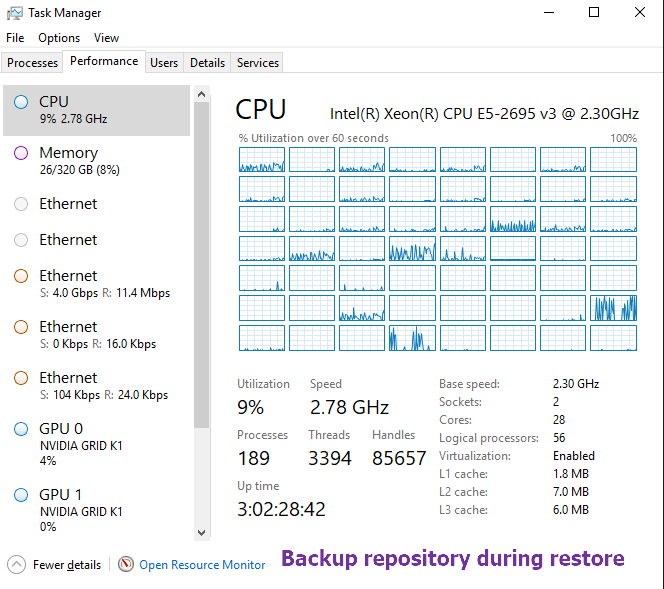
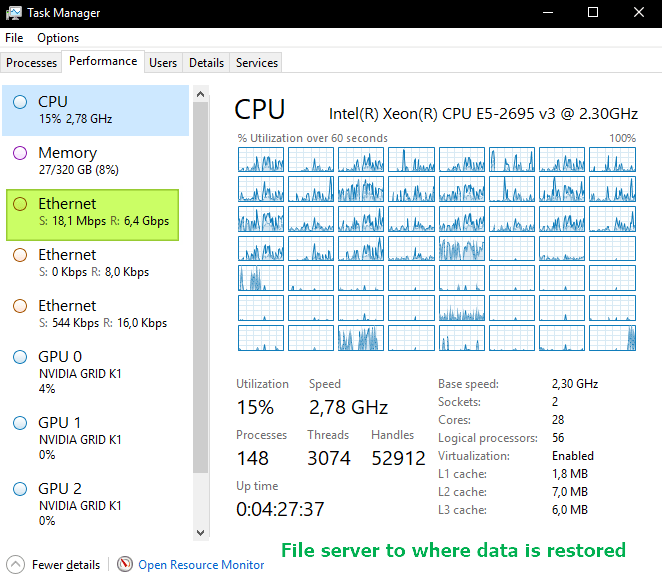
Mind you, this varies a lot and when it hits small files the throughput slows down while the cores load rises
Conclusion
For now, with variable data and lots of small files, it looks that restores take 2.5 to 3 times as long as backups with office worker data. We’ll do more testing with different data. With large image files, the difference is a lot less from our early testing. For now, this gives you a first look at our results with Veeam File Share backups and knowledge worker data As always, test for your self and test multiple scenarios. Your mileage will vary and you have to do your own due diligence. These lab tests are the beginning of mine, just to get a feel for what I can achieve. If you want to learn more about Veeam Backup & Replication go here.Thank you for reading.