
Introduction
When you have upgraded your SC Series SAN to SCOS 7.3 (7.3.5.8.4 at the time of writing, see https://blog.workinghardinit.work/2018/SCX08/13/sc-series-scos-7-3/ ) you are immediately ready to start utilizing the SCOS 7.3 distributed spares feature. This is very easy and virtually transparent to do.
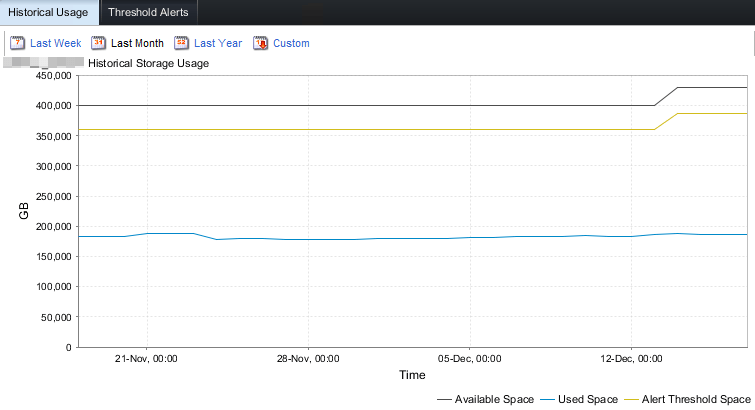
You will actually notice a capacity and treshhold jump in your SC array when you upgraded to 7.3. The system now know the spare capacity is now dealt with differently.
How?
After upgrading you’ll see a notification either in Storage Manager or in Unisphere Central that informs you about the following:
“Distributed spare optimizer is currently disabled. Enabling optimizer will increase
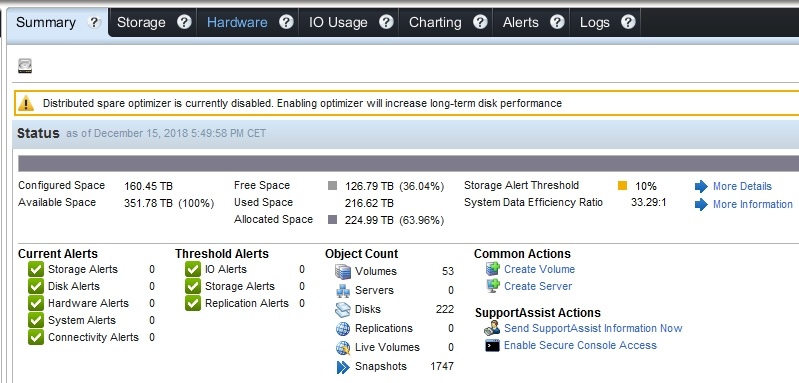
Once you click enable you’ll be asked if you want to proceed.
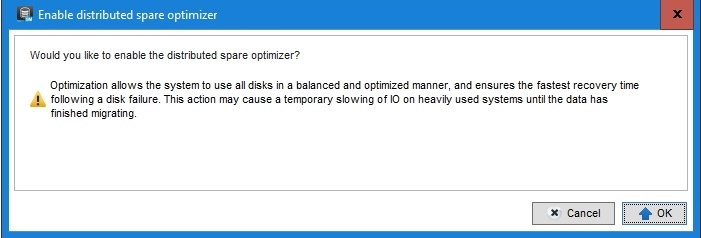
When you click “OK” the optimizer is configured and will start its work. That’s a one way street. You cannot go back to classic hot spares. That is good to know but in reality, you don’t want to go back anyway.
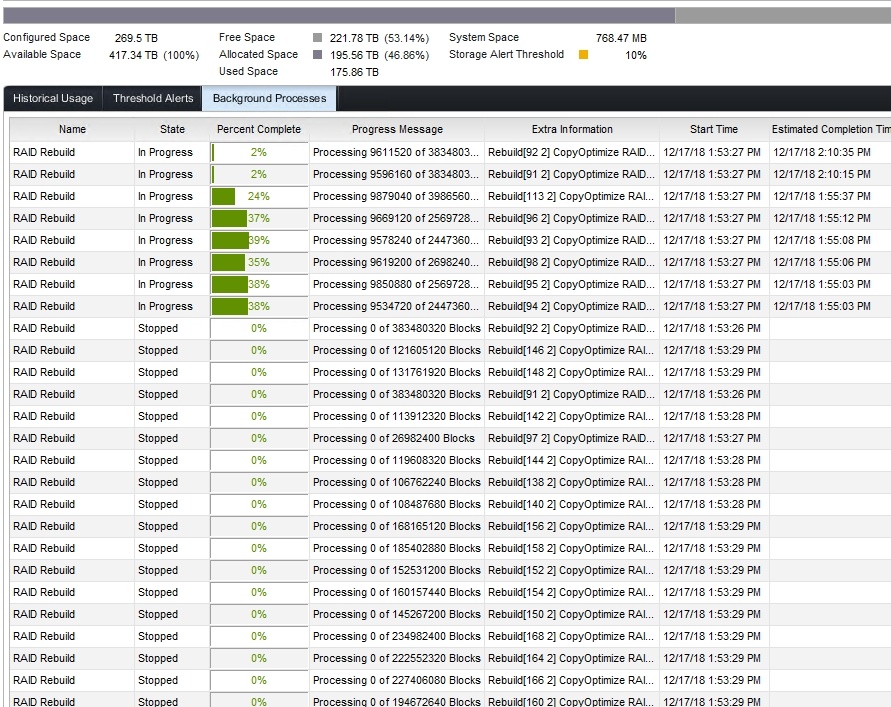
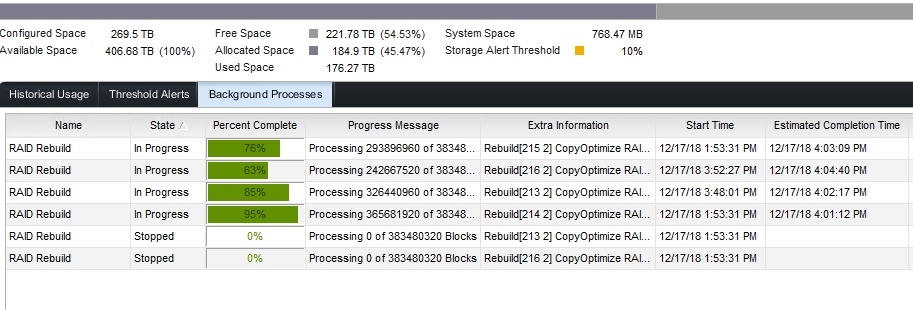
In “Background Processes” you’ll be able to follow the progress of the initial redistribution. This goes reasonabely fast and I did 3 SANs during a workday. No one even noticed or complained about any performance issues.
The benefits are crystal clear
The benefits of SCOS 7.3 Distributed Spares are crystal clear:
- Better performance. All disks contribute to the overall IOPS. There are no disks idling while reserved as a hot spare. Depending on the number of disks in your array the number of hot spares adds up. Next up for me is to rerun my
base line performance test and see if I can measure this. - The lifetime of disks increases. On each disk, a portion is set aside as sparing capacity. This leads to an extra amount of under-provisioning. The workload on each of the drives is reduced a bit and gives the storage controller additional capacity from which to perform wear-leveling operations thus increasing the
life span . - Faster rebuilds. This is the big one. As we can now read AND write to many disks the rebuild speed increases significantly. With ever bigger disks this is something you need and what was long overdue. But it’s here! It also allows for fast redistribution when a failed disk is replaced. On top of that when a disk is marked suspect the before it fails. A copy of the data takes place to spare capacity and only when that is done is the orginal data on the failing disk taken out fo use and is the disk marked as failed for replacement. This copy operation is less costly than a rebuild.
A few weeks ago, I was informed of an issue that can come up to migrating to distributed spares. When prepping for our 7.3 upgrade (scheduled for a couple weeks from now), I was told by the support technician I was on the phone with that if you have compression and especially de-duplication enabled the rebuild time for distributed spares may take weeks. During that time no data progression of any kind will take place. When I said that we would run out of space within a few days if data progression didn’t happen, the solution that he said they are using in that scenario is to pause the rebuild every day to allow data progression to happen and then resume the rebuild. This of course is something that Dell/EMC has to do for you (and remember to do daily). Not ideal, but workable.
Mileage will vary, depending on setup. So pausing distributed spares optimization your self won’t do? Have not checked yet if the PoSH modules offer a way to automate this, otherwise, that might be an option.
Are you saying that there is a way for us pause/resume it ourselves or conjecturing that the PowerShell modules might be able to do it? I can see background jobs that are running in DSM and SC, but I don’t see a way to interact with any of them. The tech indicated that this isn’t something the we can without involving them, but if there is a way for us to do it I would love to have that in my back pocket in case they forget to do it one night..
While I don’t know if what they do is the same but we as a user do have the option to disable the distributed spare optimizer see figure 7 in https://downloads.dell.com/manuals/all-products/esuprt_software/esuprt_it_ops_datcentr_mgmt/general-solution-resources_white-papers5_en-us.pdf that shows how to do it in Unisphere Storage Center for SC Series but you can also do it in the setting of your Compellent in the DSM (storage). I still need to see if we have a version of the PowerShell SDK that supports enabling/disabling it. You can ask if that’s what they do or if it is something else.
I’m not sure that that will do it when you are first enabling distributed spares. As your last couple of screenshots above show, that operation is classified as a RAID rebuild. When distributed spare optimization is running, what operation does it show?
We did our upgrade a couple of days ago and it actually took far less time to complete than expected (~24 hours for 184TB with a mix of WI SSDs, RI SSDs, 15k SAS, and 7k SAS). It turns out you can start and stop it yourself. In DSM, if you switch to the Storage tab and right-click on the Disk node, there is an option to Rebalance RAID. It allows you to start and stop RAID rebalancing at your leisure.
Nice 🙂
what about the pain that it brigs? like if you need to put on the storage big amount of data (bigger than can fit into allocated tiers) then the IO will almost stop. So even if there will be a lot of free space I’m limited to the allocated space which I can’t extend manually.
Not realy sure why this would bring you more pain than “normal”. Tier size need to be large enough, if not yeah that hurts. Next to that, tiering is an over a decade old idea when HDDs still were in swing and then it was better then not. But with all flash, in many systems, bar for caching it is no longer a great idea.
Tier size need to be large enough – sure it should, i would even say it must. but there is no way to extend it manually with Distributed Spares enabled.