In Shared nothing live migration with a virtual switch change and VLAN ID configuration I published a sample script. The script works well. But there are two areas of improvement. The first one is here in Checkpoint references a non-existent virtual switch. This post is about the second one. Here I show that I also need to check the virtual switch QoS mode during migrations. A couple of the virtual machines on the source nodes had absolute minimum and/or maximum bandwidth set. On the target nodes, all the virtual switches are created by PowerShell. This defaults to weight mode for QoS, which is the more sensible option, albeit not always the easiest or practical one for people to use.
Virtual switch QoS mode during migrations
First a quick recap of what we are doing. The challenge was to shared nothing live migrate virtual machines to a host with different virtual switch names and VLAN IDs. We did so by adding dummy virtual switches to the target host. This made share nothing live migration possible. On arrival of the virtual machine on the target host, we immediately connect the virtual network adapters to the final virtual switch and set the correct VLAN IDs. That works very well. You drop 1 or at most 2 pings, this is as good as it gets.
This goes wrong under the following conditions:
The source virtual switch has QoS mode absolute.
Virtual network adapter connected to the source virtual switch has MinimumBandwidthAbsolute and/or MaximumBandwidth set.
The target virtual switch with QoS mode weighted
This will cause connectivity loss as you cannot set absolute values to a virtual network attached to a weighted virtual switch. So connecting the virtual to the new virtual switch just fails and you lose connectivity. Remember that the virtual machine is connected to a dummy virtual switch just to make the live migration work and we need to swap it over immediately. The VLAN ID does get set correctly actually. Let’s deal with this.
Steps to fix this issue
First of all, we adapt the script to check the QoS mode on the source virtual switches. If it is set to absolute we know we need to check for any settings of MinimumBandwidthAbsolute and MaximumBandwidth on the virtual adapters connected to those virtual switches. These changes are highlighted in the demo code below.
Secondly, we adapt the script to check every virtual network adapter for its bandwidth management settings. If we find configured MinimumBandwidthAbsolute and MaximumBandwidth values we set these to 0 and as such disable the bandwidth settings. This makes sure that connecting the virtual network adapters to the new virtual switch with QoS mode weighted will succeed. These changes are highlighted in the demo code below.
Finally, the complete script
#The source Hyper-V host
$SourceNode = 'NODE-A'
#The LUN where you want to storage migrate your VMs away from
$SourceRootPath = "C:\ClusterStorage\Volume1*"
#The source Hyper-V host
#The target Hypr-V host
$TargetNode = 'ZULU'
#The storage pathe where you want to storage migrate your VMs to
$TargetRootPath = "C:\ClusterStorage\Volume1"
$OldVirtualSwitch01 = 'vSwitch-VLAN500'
$OldVirtualSwitch02 = 'vSwitch-VLAN600'
$NewVirtualSwitch = 'ConvergedVirtualSwitch'
$VlanId01 = 500
$VlanId02 = 600
if ((Get-VMSwitch -name $OldVirtualSwitch01 ).BandwidthReservationMode -eq 'Absolute') {
$OldVirtualSwitch01QoSMode = 'Absolute'
}
if ((Get-VMSwitch -name $OldVirtualSwitch01 ).BandwidthReservationMode -eq 'Absolute') {
$OldVirtualSwitch02QoSMode = 'Absolute'
}
#Grab all the VM we find that have virtual disks on the source CSV - WARNING for W2K12 you'll need to loop through all cluster nodes.
$AllVMsOnRootPath = Get-VM -ComputerName $SourceNode | where-object { $_.HardDrives.Path -like $SourceRootPath }
#We loop through all VMs we find on our SourceRoootPath
ForEach ($VM in $AllVMsOnRootPath) {
#We generate the final VM destination path
$TargetVMPath = $TargetRootPath + "\" + ($VM.Name).ToUpper()
#Grab the VM name
$VMName = $VM.Name
$VM.VMid
$VMName
#If the VM is still clusterd, get it removed form the cluster as live shared nothing migration will otherwise fail.
if ($VM.isclustered -eq $True) {
write-Host -ForegroundColor Magenta $VM.Name "is clustered and is being removed from cluster"
Remove-ClusterGroup -VMId $VM.VMid -Force -RemoveResources
Do { Start-Sleep -seconds 1 } While ($VM.isclustered -eq $True)
write-Host -ForegroundColor Yellow $VM.Name "has been removed from cluster"
}
#If the VM checkpoint, notify the user of the script as this will cause issues after swicthing to the new virtual
#switch on the target node. Live migration will fail between cluster nodes if the checkpoints references 1 or more
#non existing virtual switches. These must be removed prior to of after completing the shared nothing migration.
#The script does this after the migration automatically, not before as I want it to be untouched if the shared nothing
#migration fails.
$checkpoints = get-vmcheckpoint -VMName $VM.Name
if ($Null -ne $checkpoints) {
write-host -foregroundcolor yellow "This VM has checkpoints"
write-host -foregroundcolor yellow "This VM will be migrated to the new host"
write-host -foregroundcolor yellow "Only after a succesfull migration will ALL the checpoints be removed"
}
#Do the actual storage migration of the VM, $DestinationVMPath creates the default subfolder structure
#for the virtual machine config, snapshots, smartpaging & virtual hard disk files.
Move-VM -Name $VMName -ComputerName $VM.ComputerName -IncludeStorage -DestinationStoragePath $TargetVMPath -DestinationHost $TargetNode
$MovedVM = Get-VM -ComputerName $TargetNode -Name $VMName
$vNICOnOldvSwitch01 = Get-VMNetworkAdapter -ComputerName $TargetNode -VMName $MovedVM.VMName | where-object SwitchName -eq $OldVirtualSwitch01
if ($Null -ne $vNICOnOldvSwitch01) {
foreach ($VMNetworkadapater in $vNICOnOldvSwitch01) {
if ($OldVirtualSwitch01QoSMode -eq 'Absolute') {
if (0 -ne $VMNetworkAdapter.bandwidthsetting.Maximumbandwidth) {
write-host -foregroundcolor cyan "Network adapter $VMNetworkAdapter.Name of VM $VMName MaximumBandwidth will be reset to 0."
Set-VMNetworkAdapter -Name $VMNetworkAdapter.Name -VMName $MovedVM.Name -ComputerName $TargetNode -MaximumBandwidth 0
}
if (0 -ne $VMNetworkAdapter.bandwidthsetting.MinimumBandwidthAbsolute) {
write-host -foregroundcolor cyan "Network adapter $VMNetworkAdapter.Name of VM $VMName MaximuBandwidthAbsolute will be reset to 0."
Set-VMNetworkAdapter -Name $VMNetworkAdapter.Name -VMName $MovedVM.Name -ComputerName $TargetNode -MinimumBandwidthAbsolute 0
}
}
write-host 'Moving to correct vSwitch'
Connect-VMNetworkAdapter -VMNetworkAdapter $vNICOnOldvSwitch01 -SwitchName $NewVirtualSwitch
write-host "Setting VLAN $VlanId01"
Set-VMNetworkAdapterVlan -VMNetworkAdapter $vNICOnOldvSwitch01 -Access -VLANid $VlanId01
}
}
$vNICsOnOldvSwitch02 = Get-VMNetworkAdapter -ComputerName $TargetNode -VMName $MovedVM.VMName | where-object SwitchName -eq $OldVirtualSwitch02
if ($NULL -ne $vNICsOnOldvSwitch02) {
foreach ($VMNetworkadapater in $vNICsOnOldvSwitch02) {
if ($OldVirtualSwitch02QoSMode -eq 'Absolute') {
if ($Null -ne $VMNetworkAdapter.bandwidthsetting.Maximumbandwidth) {
write-host -foregroundcolor cyan "Network adapter $VMNetworkAdapter.Name of VM $VMName MaximumBandwidth will be reset to 0."
Set-VMNetworkAdapter -Name $VMNetworkAdapter.Name -VMName $MovedVM.Name -ComputerName $TargetNode -MaximumBandwidth 0
}
if ($Null -ne $VMNetworkAdapter.bandwidthsetting.MinimumBandwidthAbsolute) {
write-host -foregroundcolor cyan "Network adapter $VMNetworkAdapter.Name of VM $VMName MaximumBandwidth will be reset to 0."
Set-VMNetworkAdapter -Name $VMNetworkAdapter.Name -VMName $MovedVM.Name -ComputerName $TargetNode -MinimumBandwidthAbsolute 0
}
}
write-host 'Moving to correct vSwitch'
Connect-VMNetworkAdapter -VMNetworkAdapter $vNICsOnOldvSwitch02 -SwitchName $NewVirtualSwitch
write-host "Setting VLAN $VlanId02"
Set-VMNetworkAdapterVlan -VMNetworkAdapter $vNICsOnOldvSwitch02 -Access -VLANid $VlanId02
}
}
#If the VM has checkpoints, this is when we remove them.
$checkpoints = get-vmcheckpoint -ComputerName $TargetNode -VMName $MovedVM.VMName
if ($Null -ne $checkpoints) {
write-host -foregroundcolor yellow "This VM has checkpoints and they will ALL be removed"
$CheckPoints | Remove-VMCheckpoint
}
}
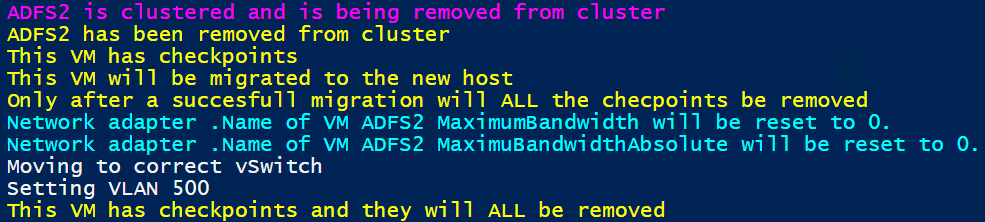
Below is the output of a VM where we had to change the switch name, enable a VLAN ID, deal with absolute QoS settings and remove checkpoints. All this without causing downtime. Nor did we change the original virtual machine in case the shared nothing migration fails.
Some observations
The fact that we are using PowerShell is great. You can only set weighted bandwidth limits via PowerShell. The GUI is only for absolute values and it will throw an error trying to use it when the virtual switch is configured as weighted.
This means you can embed setting the weights in your script if you so desire. If you do, read up on how to handle this best. trying to juggle the weight settings to be 100 in a dynamic environment is a bit of a challenge. So use the default flow pool and keep the number of virtual network adapters with unique settings to a minimum.
Conclusion
To avoid downtime we removed all the set minimum and maximum bandwidth settings on any virtual network adapter. By doing so we ensured that the swap to the new virtual switch right after the successful shared nothing live migration will succeed. If you want you can set weights on the virtual network adapters afterward. But as the bandwidth on these new hosts is now a redundant 25 Gbps, the need was no longer there. As a result, we just left them without. this can always be configured later if it turns out to be needed.
Warning: this is a demo script. It lacks error handling and logging. It can also contain mistakes. But hey you get it for free to adapt and use. Test and adapt this in a lab. You are responsible for what you do in your environments. Running scripts downloaded from the internet without any validation make you a certified nut case. That is not my wrongdoing.
I hope this helps some of you. thanks for reading.
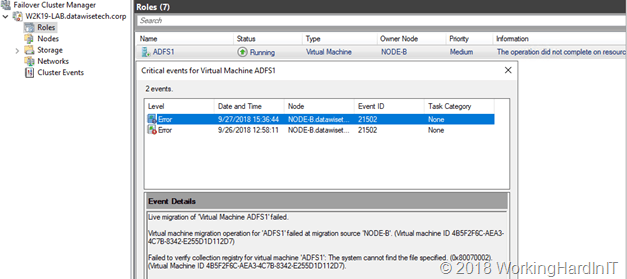
I was tasked to troubleshoot a cluster where cluster aware updating (CAU) failed due to the nodes never succeeding going into maintenance mode. It seemed that none of the obvious or well know issues and mistakes that might break live migrations were present. Looking at the cluster and testing live migration not a single VM on any node would live migrate to any other node. So, I take a peek the event id and description and it hits me. I have seen this particular event id before.
Log Name: System Source: Microsoft-Windows-Hyper-V-High-Availability Date: 9/27/2018 15:36:44 Event ID: 21502 Task Category: None Level: Error Keywords: User: SYSTEM Computer: NODE-B.datawisetech.corp Description: Live migration of ‘Virtual Machine ADFS1’ failed. Virtual machine migration operation for ‘ADFS1’ failed at migration source ‘NODE-B’. (Virtual machine ID 4B5F2F6C-AEA3-4C7B-8342-E255D1D112D7) Failed to verify collection registry for virtual machine ‘ADFS1’: The system cannot find the file specified. (0x80070002). (Virtual Machine ID 4B5F2F6C-AEA3-4C7B-8342-E255D1D112D7).The live migration fails due to non-existent SharedStoragePath or ConfigStoreRootPath which is where collections metadata lives.
More errors are logged
There usually are more related tell-tale events. They however are clear in pin pointing the root cause.
On the destination host
On the destination host you’ll find event id 21066:
Log Name: Microsoft-Windows-Hyper-V-VMMS-Admin Source: Microsoft-Windows-Hyper-V-VMMS Date: 9/27/2018 15:36:45 Event ID: 21066 Task Category: None Level: Error Keywords: User: SYSTEM Computer: NODE-A.datawisetech.corp Description: Failed to verify collection registry for virtual machine ‘ADFS1’: The system cannot find the file specified. (0x80070002). (Virtual Machine ID 4B5F2F6C-AEA3-4C7B-8342-E255D1D112D7).
A bunch of 1106 events per failed live migration per VM in like below:
Log Name: Microsoft-Windows-Hyper-V-VMMS-Operational Source: Microsoft-Windows-Hyper-V-VMMS Date: 9/27/2018 15:36:45 Event ID: 1106 Task Category: None Level: Error Keywords: User: SYSTEM Computer: NODE-A.datawisetech.corp Description: vm\service\migration\vmmsvmmigrationdestinationtask.cpp(5617)\vmms.exe!00007FF77D2171A4: (caller: 00007FF77D214A5D) Exception(998) tid(1fa0) 80070002 The system cannot find the file specified.
As well as event id 21111: Log Name: Microsoft-Windows-Hyper-V-High-Availability-Admin Source: Microsoft-Windows-Hyper-V-High-Availability Date: 9/27/2018 15:36:44 Event ID: 21111 Task Category: None Level: Error Keywords: User: SYSTEM Computer: NODE-B.datawisetech.corp Description: Live migration of ‘Virtual Machine ADFS1’ failed.
… event id 21066: Log Name: Microsoft-Windows-Hyper-V-VMMS-Admin Source: Microsoft-Windows-Hyper-V-VMMS Date: 9/27/2018 15:36:44 Event ID: 21066 Task Category: None Level: Error Keywords: User: SYSTEM Computer: NODE-B.datawisetech.corp Description: Failed to verify collection registry for virtual machine ‘ADFS1’: The system cannot find the file specified. (0x80070002). (Virtual Machine ID 4B5F2F6C-AEA3-4C7B-8342-E255D1D112D7).
… and event id 21024: Log Name: Microsoft-Windows-Hyper-V-VMMS-Admin Source: Microsoft-Windows-Hyper-V-VMMS Date: 9/27/2018 15:36:44 Event ID: 21024 Task Category: None Level: Error Keywords: User: SYSTEM Computer: NODE-B.datawisetech.corp Description: Virtual machine migration operation for ‘ADFS1’ failed at migration source ‘NODE-B’. (Virtual machine ID 4B5F2F6C-AEA3-4C7B-8342-E255D1D112D7)
Live migration fails due to non-existent SharedStoragePath or ConfigStoreRootPath explained
This is what a Windows Server 2016/2019 cluster that has not been configured with a looks like.
Get-VMHostCluster -ClusterName “W2K19-LAB”
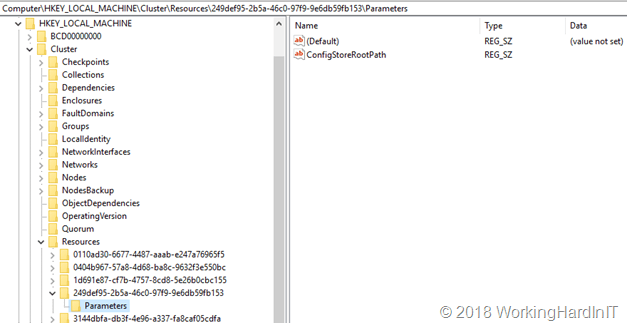
HKLM\Cluster\Resources\GUIDofWMIResource\Parameters there is a value called ConfigStoreRootPath which in PowerShell is know as the SharedStoragePath property. You can also query it via
And this is what it looks like in the registry (0.Cluster and Cluster keys.) The resource ID we are looking at is the one of the Virtual Machine Cluster WMI resource.
If it returns a path you must verify that it exists, if not you’re in trouble with live migrations. You will also be in trouble with host level guest cluster backups or Hyper-V replicas of them. Maybe you don’t have guest cluster or use in guest backups and this is just a remnant of trying them out.
When I run it on the problematic cluster I get a path points to a folder on a CSV that doesn’t exist.
Did they rename the CSV? Replace the storage array? Well as it turned out they reorganized and resized the CSVs. As they can’t shrink SAN LUNs the created new ones. They then leveraged storage live migration to move the VMs.
The old CSV’s where left in place for about 6 weeks before they were cleaned up. As this was the first time they ran Cluster Aware Updating after removing them this is the first time they hit this problem. Bingo! You probably think you’ll just change it to an existing CSV folder path or delete it. Well as it turns out, you cannot do that. You can try …
Set-VMHostCluster : The operation on computer ‘W2K19-LAB’ failed: The WS-Management service cannot process the request. The WMI service or the WMI provider returned an unknown error: HRESULT 0x80070032 At line:1 char:1 + Set-VMHostCluster -ClusterName “W2K19-LAB” -SharedStoragePath “C:\Clu … + ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ + CategoryInfo : NotSpecified: (:) [Set-VMHostCluster], VirtualizationException + FullyQualifiedErrorId : OperationFailed,Microsoft.HyperV.PowerShell.Commands.SetVMHostCluster
Whatever you try, deleting, overwriting, … no joy. As it turns out you cannot change it and this is by design. A shaky design I would say. I understand the reasons because if it changes or is deleted and you have guest clusters with collection depending on what’s in there you have backup and live migration issues with the guest clusters. But if you can’t change it you also run into issues if storage changes. You dammed if you do, dammed if you don’t.
Workaround 1
What
Create a CSV with the old name and folder(s) to which the current path is pointing. That works. It could even be a very small one. As test I use done of 1GB. Not sure of that’s enough over time but if you can easily extend your CSV that’s should not pose a problem. It might actually be a good idea to have this as a best practice. Have a dedicated CSV for the SharedStoragePath. I’ll need to ask Microsoft.
How
You know how to create a CSV and a folder I guess, that’s about it. I’ll leave it at that.
Workaround 2
What
Set the path to a new one in the registry. This could be a new path (mind you this won’t fix any problems you might already have now with existing guest clusters).
Delete the value for that current path and leave it empty. This one is only a good idea if you don’t have a need for VHD Set Guest clusters anymore. Basically, this is resetting it to the default value.
How
There are 2 ways to do this. Both cost down time. You need to bring the cluster service down on all nodes and then you don’t have your CSV’s. That means your VMs must be shut down on all nodes of the cluster
The Microsoft Support way
Well that’s what they make you do (which doesn’t mean you should just do it even without them instructing you to do so)
Export your HKLM\Cluster\Resources\GUIDofWMIResource\Parameters for save keeping and restore if needed.
Shut down all VMs in the cluster or even the ones residing on a CSV even if not clusterd.
Stop the cluster service on all nodes (the cluster is shutdown if you do that), leave the one you are working on for last.
From one node, open up the registry key
Click on HKEY_LOCAL_MACHINE and then click on file, then select load hive
Browse to c:\windows\cluster, and select CLUSDB
Click ok, and then name it DB
Expand DB, then expand Resources
Select the GUID of Virtual Machine WMI
Click on parameters, on (configStoreRootPath) you will find the value
Double click on it, and delete it or set it to a new path on a CSV that you created already
Start the cluster service
Then start the cluster service from all nodes, node by node
My way
Not supported, at your own risk, big boy rules apply. I have tried and tested this a dozen times in the lab on multiple clusters and this also works.
In the registry key Cluster (HKLM\Cluster\Resources\GUIDofWMIResource\Parameters) of ever cluster node delete the content of the REGZ value for configStoreRootPath, so it is empty or change it to a new path on a CSV that you created already for this purpose.
If you have a cluster with a disk witness, the node who owns the disk witness also has a 0.Cluster key (HKLM\0.Cluster\Resources\GUIDofWMIResource\Parameters). Make sure you also to change the value there.
When you have done this. You have to shut down all the virtual machines. You then stop the cluster service on every node. I try to work on the node owning the disk witness and shut down the cluster on that one as the final step. This is also the one where I start again the cluster again first so I can easily check that the value remains empty in both the Cluster and the 0.Cluster keys. Do note that with a file share / cloud share witness, knowing what node was shut down last can be important. See https://blog.workinghardinit.work/2017/12/11/cluster-shared-volumes-without-active-directory/. That’s why I always remember what node I’m working on and shut down last.
Start up the cluster service on the other nodes one by one.
This avoids having to load the registry hive but editing the registry on every node in large clusters is tedious. Sure, this can be scripted in combination with shutting down the VMs, stopping the cluster service on all nodes, changing the value and then starting the cluster services again as well as the VMs. You can control the order in which you go through the nodes in a script as well. I actually did script this but I used my method. you can find it at the bottom of this blog post.
Both methods will work and live migrations will work again. Any existing problematic guest cluster VMs in backup or live migration is food for another blog post perhaps. But you’ll have things like driving your crazy.
Some considerations
Workaround 1 is a bit of a “you got to be kidding me” solution but at least it leaves some freedom replace, rename, reorganize the other CSVs as you see fit. So perhaps having a dedicated CSV just for this purpose is not that silly. Another benefit is that this does not involve messing around in the cluster database via the registry. This is something we advise against all the time but now has become a way to get out of a pickle.
Workaround 2 speaks for its self. There is two ways to achieve this which I have shown. But a word of warning. The moment the path changes and you have some already existing VHD Set guests clusters that somehow depend on that you’ll see that backups start having issues and possibly even live migrations. But you’re toast for all your Live migrations anyway already so … well yeah, what can I do.
So, this is by design. Maybe it is but it isn’t very realistic that your stuck to a path and name that hard and that it causes this much grief or allows for people to shoot themselves in the foot. It’s not like all this documented somewhere.
Conclusion
This needs to be fixed. While I can get you out of this pickle it is a tedious operation with some risk in a production environment. It also requires down time, which is bad. On top of that it will only have a satisfying result if you don’t have any VHD Set guest clusters that rely on the old path. The mechanism behind the SharedStoragePath isn’t as robust and flexible yet as it should be when it comes to changes & dealing with failed host level guest cluster backups.
I have tested this in Windows 2019 insider preview. The issue is still there. No progress on that front. Maybe in some of the future cumulative updates, things will be fixed to make guest clustering with VHD Set a more robust and reliable solution. The fact that Microsoft relies on guest clustering to support some deployment scenarios with S2D makes this even more disappointing. It is also a reason I still run physical shared storage-based file clusters.
The problematic host level backups I can work around by leveraging in guest backups. But the path issue is unavoidable if changes are needed.
After 2 years of trouble with the framework around guest cluster backups / VHD Set, it’s time this “just works”. No one will use it when it remains this troublesome and you won’t fix this if no one uses this. The perfect catch 22 situation.
The Script
$ClusterName = "W2K19-LAB"
$OwnerNodeWitnessDisk = $Null
$RemberLastNodeThatWasShutdown = $Null
$LogFileName = "ConfigStoreRootPathChange"
$RegistryPathCluster = "HKLM:\Cluster\Resources\$WMIClusterResourceID\Parameters"
$RegistryPathClusterDotZero = "HKLM:\0.Cluster\Resources\$WMIClusterResourceID\Parameters"
$REGZValueName = "ConfigStoreRootPath"
$REGZValue = $Null #We need to empty the value
#$REGZValue = "C:\ClusterStorage\ReFS-01\SharedPath" #We need to set a new path.
#Region SupportingFunctionsAndWorkFlows
Workflow ShutDownVMs {
param ($AllVMs)
Foreach -parallel ($VM in $AllVMs) {
InlineScript {
try {
If ($using:VM.State -eq "Running") {
Stop-VM -Name $using:VM.Name -ComputerName $using:VM.ComputerName -force
}
}
catch {
$ErrorMessage = $_.Exception.Message
$ErrorLine = $_.InvocationInfo.Line
$ExceptionInner = $_.Exception.InnerException
Write-2-Log -Message "!Error occured!:" -Severity Error
Write-2-Log -Message $ErrorMessage -Severity Error
Write-2-Log -Message $ExceptionInner -Severity Error
Write-2-Log -Message $ErrorLine -Severity Error
Write-2-Log -Message "Bailing out - Script execution stopped" -Severity Error
}
}
}
}
#Code to shut down all VMs on all Hyper-V cluster nodes
Workflow StartVMs {
param ($AllVMs)
Foreach -parallel ($VM in $AllVMs) {
InlineScript {
try {
if ($using:VM.State -eq "Off") {
Start-VM -Name $using:VM.Name -ComputerName $using:VM.ComputerName
}
}
catch {
$ErrorMessage = $_.Exception.Message
$ErrorLine = $_.InvocationInfo.Line
$ExceptionInner = $_.Exception.InnerException
Write-2-Log -Message "!Error occured!:" -Severity Error
Write-2-Log -Message $ErrorMessage -Severity Error
Write-2-Log -Message $ExceptionInner -Severity Error
Write-2-Log -Message $ErrorLine -Severity Error
Write-2-Log -Message "Bailing out - Script execution stopped" -Severity Error
}
}
}
}
function Write-2-Log {
[CmdletBinding()]
param(
[Parameter()]
[ValidateNotNullOrEmpty()]
[string]$Message,
[Parameter()]
[ValidateNotNullOrEmpty()]
[ValidateSet('Information', 'Warning', 'Error')]
[string]$Severity = 'Information'
)
$Date = get-date -format "yyyyMMdd"
[pscustomobject]@{
Time = (Get-Date -f g)
Message = $Message
Severity = $Severity
} | Export-Csv -Path "$PSScriptRoot\$LogFileName$Date.log" -Append -NoTypeInformation
}
#endregion
Try {
Write-2-Log -Message "Connecting to cluster $ClusterName" -Severity Information
$MyCluster = Get-Cluster -Name $ClusterName
$WMIClusterResource = Get-ClusterResource "Virtual Machine Cluster WMI" -Cluster $MyCluster
Write-2-Log -Message "Grabbing Cluster Resource: Virtual Machine Cluster WMI" -Severity Information
$WMIClusterResourceID = $WMIClusterResource.Id
Write-2-Log -Message "The Cluster Resource Virtual Machine Cluster WMI ID is $WMIClusterResourceID " -Severity Information
Write-2-Log -Message "Checking for quorum config (disk, file share / cloud witness) on $ClusterName" -Severity Information
If ((Get-ClusterQuorum -Cluster $MyCluster).QuorumResource -eq "Witness") {
Write-2-Log -Message "Disk witness in use. Lookin up for owner node of witness disk as that holds the 0.Cluster registry key" -Severity Information
#Store the current owner node of the witness disk.
$OwnerNodeWitnessDisk = (Get-ClusterGroup -Name "Cluster Group").OwnerNode
Write-2-Log -Message "Owner node of witness disk is $OwnerNodeWitnessDisk" -Severity Information
}
}
Catch {
$ErrorMessage = $_.Exception.Message
$ErrorLine = $_.InvocationInfo.Line
$ExceptionInner = $_.Exception.InnerException
Write-2-Log -Message "!Error occured!:" -Severity Error
Write-2-Log -Message $ErrorMessage -Severity Error
Write-2-Log -Message $ExceptionInner -Severity Error
Write-2-Log -Message $ErrorLine -Severity Error
Write-2-Log -Message "Bailing out - Script execution stopped" -Severity Error
Break
}
try {
$ClusterNodes = $MyCluster | Get-ClusterNode
Write-2-Log -Message "We have grabbed the cluster nodes $ClusterNodes from $MyCluster" -Severity Information
Foreach ($ClusterNode in $ClusterNodes) {
#If we have a disk witness we also need to change the in te 0.Cluster registry key on the current witness disk owner node.
If ($ClusterNode.Name -eq $OwnerNodeWitnessDisk) {
if (Test-Path -Path $RegistryPathClusterDotZero) {
Write-2-Log -Message "Changing $REGZValueName in 0.Cluster key on $OwnerNodeWitnessDisk who owns the witnessdisk to $REGZvalue" -Severity Information
Invoke-command -computername $ClusterNode.Name -ArgumentList $RegistryPathClusterDotZero, $REGZValueName, $REGZValue {
param($RegistryPathClusterDotZero, $REGZValueName, $REGZValue)
Set-ItemProperty -Path $RegistryPathClusterDotZero -Name $REGZValueName -Value $REGZValue -Force | Out-Null}
}
}
if (Test-Path -Path $RegistryPathCluster) {
Write-2-Log -Message "Changing $REGZValueName in Cluster key on $ClusterNode.Name to $REGZvalue" -Severity Information
Invoke-command -computername $ClusterNode.Name -ArgumentList $RegistryPathCluster, $REGZValueName, $REGZValue {
param($RegistryPathCluster, $REGZValueName, $REGZValue)
Set-ItemProperty -Path $RegistryPathCluster -Name $REGZValueName -Value $REGZValue -Force | Out-Null}
}
}
Write-2-Log -Message "Grabbing all VMs on all clusternodes to shut down" -Severity Information
$AllVMs = Get-VM –ComputerName ($ClusterNodes)
Write-2-Log -Message "We are shutting down all running VMs" -Severity Information
ShutdownVMs $AllVMs
}
catch {
$ErrorMessage = $_.Exception.Message
$ErrorLine = $_.InvocationInfo.Line
$ExceptionInner = $_.Exception.InnerException
Write-2-Log -Message "!Error occured!:" -Severity Error
Write-2-Log -Message $ErrorMessage -Severity Error
Write-2-Log -Message $ExceptionInner -Severity Error
Write-2-Log -Message $ErrorLine -Severity Error
Write-2-Log -Message "Bailing out - Script execution stopped" -Severity Error
Break
}
try {
#Code to stop the cluster service on all cluster nodes
#ending with the witness owner if there is one
Write-2-Log -Message "Shutting down cluster service on all nodes in $MyCluster that are not the owner of the witness disk" -Severity Information
Foreach ($ClusterNode in $ClusterNodes) {
#First we shut down all nodes that do NOT own the witness disk
If ($ClusterNode.Name -ne $OwnerNodeWitnessDisk) {
Write-2-Log -Message "Stop cluster service on node $ClusterNode.Name" -Severity Information
if ((Get-ClusterNode -Cluster W2K19-LAB | where-object {$_.State -eq "Up"}).count -ne 1) {
Stop-ClusterNode -Name $ClusterNode.Name -Cluster $MyCluster | Out-Null
}
Else {
Stop-Cluster -Cluster $MyCluster -Force | Out-Null
$RemberLastNodeThatWasShutdown = $ClusterNode.Name
}
}
}
#Whe then shut down the nodes that owns the witness disk
#If we have a fileshare etc, this won't do anything.
Foreach ($ClusterNode in $ClusterNodes) {
If ($ClusterNode.Name -eq $OwnerNodeWitnessDisk) {
Write-2-Log -Message "Stopping cluster and as such last node $ClusterNode.Name" -Severity Information
Stop-Cluster -Cluster $MyCluster -Force | Out-Null
$RemberLastNodeThatWasShutdown = $OwnerNodeWitnessDisk
}
}
#Code to start the cluster service on all cluster nodes,
#starting with the original owner of the witness disk
#or the one that was shut down last
Foreach ($ClusterNode in $ClusterNodes) {
#First we start the node that was shut down last. This is either the one that owned the witness disk
#or just the last node that was shut down in case of a fileshare
If ($ClusterNode.Name -eq $RemberLastNodeThatWasShutdown) {
Write-2-Log -Message "Starting the clusternode $ClusterNode.Name that was the last to shut down" -Severity Information
Start-ClusterNode -Name $ClusterNode.Name -Cluster $MyCluster | Out-Null
}
}
Write-2-Log -Message "Starting the all other clusternodes in $MyCluster" -Severity Information
Foreach ($ClusterNode in $ClusterNodes) {
#We then start all the other nodes in the cluster.
If ($ClusterNode.Name -ne $RemberLastNodeThatWasShutdown) {
Write-2-Log -Message "Starting the clusternode $ClusterNode.Name" -Severity Information
Start-ClusterNode -Name $ClusterNode.Name -Cluster $MyCluster | Out-Null
}
}
}
catch {
$ErrorMessage = $_.Exception.Message
$ErrorLine = $_.InvocationInfo.Line
$ExceptionInner = $_.Exception.InnerException
Write-2-Log -Message "!Error occured!:" -Severity Error
Write-2-Log -Message $ErrorMessage -Severity Error
Write-2-Log -Message $ExceptionInner -Severity Error
Write-2-Log -Message $ErrorLine -Severity Error
Write-2-Log -Message "Bailing out - Script execution stopped" -Severity Error
Break
}
Start-sleep -Seconds 15
Write-2-Log -Message "Grabbing all VMs on all clusternodes to start them up" -Severity Information
$AllVMs = Get-VM –ComputerName ($ClusterNodes)
Write-2-Log -Message "We are starting all stopped VMs" -Severity Information
StartVMs $AllVMs
#Hit it again ...
$AllVMs = Get-VM –ComputerName ($ClusterNodes)
StartVMs $AllVMs
The script is below as promised. If you use this without testing in a production environment and it blows up in your face you are going to get fired and it is your fault. You can use it both to introduce as fix the issue. The action are logged in the directory where the script is run from.
It’s not a secret that while guest clustering with VHDSets works very well. We’ve had some struggles in regards to host level backups however. Right now I leverage Veeam Agent for Windows (VAW) to do in guest backups. The most recent versions of VAW support Windows Failover Clustering. I’d love to leverage host level backups but I was struggling to make this reliable for quite a while. As it turned out recently there are some virtual machine permission issues involved we need to fix. Both Microsoft and Veeam have published guidance on this in a KB article. We automated correcting the permissions on the folder with VHDS files & checkpoints for host level Hyper-V guest cluster backup
But the big news here is fixing a permissions related issue!
The latest addition in the list of attention points is a permission issue. These permissions are not correct by default for the guest cluster VMs shared files. This leads to the hard to pin point error.
Error Event 19100 Hyper-V-VMMS 19100 ‘BackupVM’ background disk merge failed to complete: General access denied error (0x80070005). To fix this issue, the folder that holds the VHDS files and their snapshot files must be modified to give the VMMS process additional permissions. To do this, follow these steps for correcting the permissions on the folder with VHDS files & checkpoints for host level Hyper-V guest cluster backup.
Determine the GUIDS of all VMs that use the folder. To do this, start PowerShell as administrator, and then run the following command:
get-vm | fl name, id
Output example:
Name : BackupVM
Id : d3599536-222a-4d6e-bb10-a6019c3f2b9b
Name : BackupVM2
Id : a0af7903-94b4-4a2c-b3b3-16050d5f80f
For each VM GUID, assign the VMMS process full control by running the following command:
icacls <Folder with VHDS> /grant “NT VIRTUAL MACHINE\<VM GUID>”:(OI)F
As the above is tedious manual labor with a lot of copy pasting. This is time consuming and tedious at best. With larger guest clusters the probability of mistakes increases. To fix this we write a PowerShell script to handle this for us.
#Didier Van Hoye
#Twitter: @WorkingHardInIT
#Blog: https://blog.Workinghardinit.work
#Correct shared VHD Set disk permissions for all nodes in guests cluster
$GuestCluster = "DemoGuestCluster"
$HostCluster = "LAB-CLUSTER"
$PathToGuestClusterSharedDisks = "C:\ClusterStorage\NTFS-03\GuestClustersSharedDisks"
$GuestClusterNodes = Get-ClusterNode -Cluster $GuestCluster
ForEach ($GuestClusterNode in $GuestClusterNodes)
{
#Passing the cluster name to -computername only works in W2K16 and up.
#As this is about VHDS you need to be running 2016, so no worries here.
$GuestClusterNodeGuid = (Get-VM -Name $GuestClusterNode.Name -ComputerName $HostCluster).id
Write-Host $GuestClusterNodeGuid "belongs to" $GuestClusterNode.Name
$IcalsExecute = """$PathToGuestClusterSharedDisks""" + " /grant " + """NT VIRTUAL MACHINE\"+ $GuestClusterNodeGuid + """:(OI)F"
write-Host "Executing " $IcalsExecute
CMD.EXE /C "icacls $IcalsExecute"
}
Below is an example of the output of this script. It provides some feedback on what is happening.
Correcting the permissions on the folder with VHDS files & checkpoints for host level Hyper-V guest cluster backup
PowerShell for the win. This saves you some searching and typing and potentially making some mistakes along the way. Have fun. More testing is underway to make sure things are now predictable and stable. We’ll share our findings with you.
Below is a script that I use to collect cluster nodes with HBA WWN info. It grabs the cluster nodes and their HBA (virtual ports) WWN information form an existing cluster. In this example the nodes have Fibre Channel (FC) HBAs. It works equally well for iSCSI HBA or other cards. You can use the collected info in real time. As an example I also demonstrate writing and reading the info to and from a CSV.
This script comes in handy when you are replacing the storage arrays. You’ll need that info to do the FC zoning for example. And to create the cluster en server object with the correct HBA on the new storage arrays if it allows for automation. As a Hyper-V cluster admin you can grab all that info from your cluster nodes without the need to have access to the SAN or FC fabrics. You can use it yourself and hand it over to those handling them, who can use if to cross check the info they see on the switch or the old storage arrays.
Script to collect cluster nodes with HBA WWN info
The script demos a single cluster but you could use it for many. It collects the cluster name, the cluster nodes and their Emulex HBAs. It writes that information to a CSV files you can read easily in an editor or Excel.
The scripts demonstrates reading that CSV file and parsing the info. That info can be used in PowerShell to script the creation of the cluster and server objects on your SAN and add the HBAs to the server objects. I recently used it to move a bunch of Hyper-V and File clusters to a new DELLEMC SC Series storage arrays. That has the DELL Storage PowerShell SDK. You might find it useful as an example and to to adapt for your own needs (iSCSI, brand, model of HBA etc.).
#region Supporting Functions
Function Convert-OutputForCSV {
<#
.SYNOPSIS
Provides a way to expand collections in an object property prior
to being sent to Export-Csv.
.DESCRIPTION
Provides a way to expand collections in an object property prior
to being sent to Export-Csv. This helps to avoid the object type
from being shown such as system.object[] in a spreadsheet.
.PARAMETER InputObject
The object that will be sent to Export-Csv
.PARAMETER OutPropertyType
This determines whether the property that has the collection will be
shown in the CSV as a comma delimmited string or as a stacked string.
Possible values:
Stack
Comma
Default value is: Stack
.NOTES
Name: Convert-OutputForCSV
Author: Boe Prox
Created: 24 Jan 2014
Version History:
1.1 - 02 Feb 2014
-Removed OutputOrder parameter as it is no longer needed; inputobject order is now respected
in the output object
1.0 - 24 Jan 2014
-Initial Creation
.EXAMPLE
$Output = 'PSComputername','IPAddress','DNSServerSearchOrder'
Get-WMIObject -Class Win32_NetworkAdapterConfiguration -Filter "IPEnabled='True'" |
Select-Object $Output | Convert-OutputForCSV |
Export-Csv -NoTypeInformation -Path NIC.csv
Description
-----------
Using a predefined set of properties to display ($Output), data is collected from the
Win32_NetworkAdapterConfiguration class and then passed to the Convert-OutputForCSV
funtion which expands any property with a collection so it can be read properly prior
to being sent to Export-Csv. Properties that had a collection will be viewed as a stack
in the spreadsheet.
#>
#Requires -Version 3.0
[cmdletbinding()]
Param (
[parameter(ValueFromPipeline)]
[psobject]$InputObject,
[parameter()]
[ValidateSet('Stack', 'Comma')]
[string]$OutputPropertyType = 'Stack'
)
Begin {
$PSBoundParameters.GetEnumerator() | ForEach {
Write-Verbose "$($_)"
}
$FirstRun = $True
}
Process {
If ($FirstRun) {
$OutputOrder = $InputObject.psobject.properties.name
Write-Verbose "Output Order:`n $($OutputOrder -join ', ' )"
$FirstRun = $False
#Get properties to process
$Properties = Get-Member -InputObject $InputObject -MemberType *Property
#Get properties that hold a collection
$Properties_Collection = @(($Properties | Where-Object {
$_.Definition -match "Collection|\[\]"
}).Name)
#Get properties that do not hold a collection
$Properties_NoCollection = @(($Properties | Where-Object {
$_.Definition -notmatch "Collection|\[\]"
}).Name)
Write-Verbose "Properties Found that have collections:`n $(($Properties_Collection) -join ', ')"
Write-Verbose "Properties Found that have no collections:`n $(($Properties_NoCollection) -join ', ')"
}
$InputObject | ForEach {
$Line = $_
$stringBuilder = New-Object Text.StringBuilder
$Null = $stringBuilder.AppendLine("[pscustomobject] @{")
$OutputOrder | ForEach {
If ($OutputPropertyType -eq 'Stack') {
$Null = $stringBuilder.AppendLine("`"$($_)`" = `"$(($line.$($_) | Out-String).Trim())`"")
}
ElseIf ($OutputPropertyType -eq "Comma") {
$Null = $stringBuilder.AppendLine("`"$($_)`" = `"$($line.$($_) -join ', ')`"")
}
}
$Null = $stringBuilder.AppendLine("}")
Invoke-Expression $stringBuilder.ToString()
}
}
End {}
}
function Get-WinOSHBAInfo {
<#
Basically add 3 nicely formated properties to the HBA info we get via WMI
These are the NodeWWW, the PortWWN and the FabricName. The raw attributes
from WMI are not readily consumable. WWNs are given with a ":" delimiter.
This can easiliy be replaced or removed depending on the need.
#>
param ($ComputerName = "localhost")
# Get HBA Information
$Port = Get-WmiObject -ComputerName $ComputerName -Class MSFC_FibrePortHBAAttributes -Namespace "root\WMI"
$HBAs = Get-WmiObject -ComputerName $ComputerName -Class MSFC_FCAdapterHBAAttributes -Namespace "root\WMI"
$HBAProperties = $HBAs | Get-Member -MemberType Property, AliasProperty | Select -ExpandProperty name | ? {$_ -notlike "__*"}
$HBAs = $HBAs | Select-Object $HBAProperties
$HBAs | % { $_.NodeWWN = ((($_.NodeWWN) | % {"{0:x2}" -f $_}) -join ":").ToUpper() }
ForEach ($HBA in $HBAs) {
# Get Port WWN
$PortWWN = (($Port |? { $_.instancename -eq $HBA.instancename }).attributes).PortWWN
$PortWWN = (($PortWWN | % {"{0:x2}" -f $_}) -join ":").ToUpper()
Add-Member -MemberType NoteProperty -InputObject $HBA -Name PortWWN -Value $PortWWN
# Get Fabric WWN
$FabricWWN = (($Port |? { $_.instancename -eq $HBA.instancename }).attributes).FabricName
$FabricWWN = (($FabricWWN | % {"{0:x2}" -f $_}) -join ":").ToUpper()
Add-Member -MemberType NoteProperty -InputObject $HBA -Name FabricWWN -Value $FabricWWN
# Output
$HBA
}
}
#endregion
#Grab the cluster nane in a variable. Adapt thiscode to loop through all your clusters.
$ClusterName = "DEMOLABCLUSTER"
#Grab all cluster node
$ClusterNodes = Get-Cluster -name $ClusterName | Get-ClusterNode
#Create array of custom object to store ClusterName, the cluster nodes and the HBAs
$ServerWWNArray = @()
ForEach ($ClusterNode in $ClusterNodes) {
#We loop through the cluster nodes the cluster and for each one we grab the HBAs that are relevant.
#My lab nodes have different types installed up and off, so I specify the manufacturer to get the relevant ones.
#Adapt to your needs. You ca also use modeldescription to filter out FCoE vers FC HBAs etc.
$AllHBAPorts = Get-WinOSHBAInfo -ComputerName $ClusterNode.Name | Where-Object {$_.Manufacturer -eq "Emulex Corporation"}
#The SC Series SAN PowerShell takes the WWNs without any delimiters, so we dump the ":" for this use case.
$WWNs = $AllHBAPorts.PortWWN -replace ":", ""
$NodeName = $ClusterNode.Name
#Build a nice node object with the info and add it to the $ServerWWNArray
$ServerWWNObject = New-Object psobject -Property @{
WWN = $WWNs
ServerName = $NodeName
ClusterName = $ClusterName
}
$ServerWWNArray += $ServerWWNObject
}
#Show our array
$ServerWWNArray
#just a demo to list what's in the array
ForEach ($ServerNode in $ServerWWNArray) {
$Servernode.ServerName
ForEach ($WWN in $Servernode.WWN)
{$WWN}
}
#Show the results
$Export = $ServerWWNArray | Convert-OutputForCSV
#region write to CSV and read from CSV
#You can dump this in a file
$Export | export-csv -Path "c:\SysAdmin\$ClusterName.csv" -Delimiter ";"
#and get it back from a file
Get-Content -Path "c:\SysAdmin\$ClusterName.csv"
$ClusterInfoFile = Import-CSV -Path "c:\SysAdmin\$ClusterName.csv" -Delimiter ";"
$ClusterInfoFile | Format-List
#just a demo to list what's in the array
$MyClusterName = $ClusterInfoFile.clustername | get-unique
$MyClusterName
ForEach ($ClusterNode in $ClusterInfoFile) {
$ClusterNode.ServerName
ForEach ($WWN in $ClusterNode.WWN) {
$WWN
}
}